Flask 应用集成测试案例谈
我们都知道,测试是有层次的。一般来说,测试的组织应该形成类似下图那样金字塔型的结构:在底层有数量很大、短小而快速的单元测试,在开发过程中提供实时反馈;中间层是集成测试,验证各个组件组合在一起是否正常工作;再往上则有所分化,依照不同的侧重点与表现形式、有系统测试、UI 测试、用户验收测试(UAT)、接口测试、端到端测试等多种不同的称呼。从自底向上的角度看,它们应该在数量上逐层递减,但测试覆盖的范围则更大(相应的执行速度也会变慢),在损失代码局部细节的同时,也获得了更广泛的全局视角。
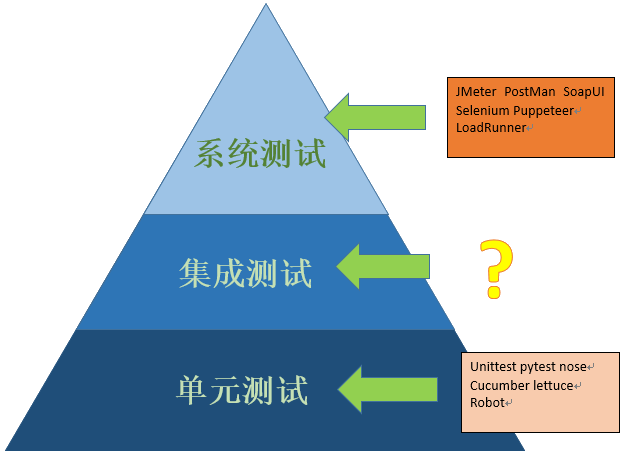
当然,面对这样广泛的测试层次,几乎没有哪个组织拥有足够的成本,可以在每个层次上都实现非常完备的测试。因此,具体的测试实施不可能全面出击,而是需要针对各个项目的具体需求和客观情况,去有重点地执行。
在实践中我们会发现一个问题:在单元测试测试这个层面上————这是敏捷开发的拥护者所偏爱的主题,有积累多年的 TDD/BDD 的理论支持(尽管 BDD 通常被认为比 TDD 在概念上要高一个层次,但是从实际执行的观点,我更倾向于认为它是 TDD 的一种方言),在网络上有大量相关介绍与学习资源,并且在几乎所有的现代语言/框架中都已经内置了对它的支持。在系统/接口测试的高层次上,通过标准的 HTTP 协议,我们也有大量已经被普遍使用的工具,比如 JMeter/Selecmium/LoadRunner 等等。奇怪的是,夹在中间的集成测试这个层次,却几乎没有什么流行的工具支持,也罕有技术文章去专门介绍它。推究原因,或许是由于为了实现集成测试,需要和框架/平台有比较深入的互操作,同时也与项目的技术选型有密切关系,因此难以形成独立的体系。但这不能不说是个遗憾的现象。
由于对集成测试这个术语的使用在社区中存在一定的混乱,因此这里需要做一点澄清。我看到某些资料把通过 HTTP 协议,比如使用 JMeter/Selenium 执行的测试也称为集成测试,严格来说这是不对的。通过外部接口执行的测试和在系统内部执行的测试应该视为两种完全不同的测试场景。
本文通过一个具体实例,介绍如何对典型的 Flask Web 应用进行集成测试,同时也会看到如何利用 Python 强大的数据分析功能,获取对于测试结果的深入理解,并以此为依据来指导性能优化工作。希望本文能够加深大家对集成测试的了解,充分发挥 Python 语言及其各种“电池”的效用,根据明确的度量数据来确定工作方向,避免“面向猜测开发”,减少浪费,改进程序的质量和工作效率。
目标
在开始测试之前,首先我们要明确一个问题,就是集成测试的目标究竟应该是什么?
顾名思义,集成测试的首要目的应该是验证系统的各个组件组合在一起能够正常工作。但是仔细想一想,这里似乎又有点问题。从概念上讲,如果各个软件组件都正确实现了它所要求的接口,并且设计不存在问题,那么它们组合在一起的时候,本来就应当正常工作,不是吗?
如果各个组件没有问题,放在一起却无法工作,这通常有几种可能:
- 第一个可能的原因是,某些组件并未真正完全实现接口的要求,特别是对于某些边界条件而言。这意味着对组件的测试覆盖不够完善。我们可以通过集成测试来发现这一类问题,但解决办法应该是完善单元测试;
- 第二种原因是设计上存在缺陷。说实话,我希望大家最好不要遇到这种情况,因为到集成的时候才发现设计问题是真正的大麻烦,很可能带来巨大的返工甚至推倒重来,这是正常的开发团队无法接受的。如果设计存在风险的话,那么架构师应该在实际编码之前就编写一些原型来验证方案的可行性。指望测试来发现这一类问题的话,那么你们的项目可能已经失败一大半了。
- 第三种原因是设计方案本身没有大的问题,但没有考虑到某些非正常的执行路径。我之前翻译过一篇文章《为什么大多数单元测试是浪费 - 续》,其中以数学的角度说明了为什么测试能够覆盖的范围是非常有限的(主要在单元测试的维度)。集成测试的确有助于捕捉到这一类的问题,但“预期之外的调用”是否算是一个真正的问题,看法可能因人/项目而异。顺带一提,上述文章尽管观点比较激进,但内容很值得一看。
综上而言,集成测试有助于捕捉到一些预期以外的调用路径,但不要指望它来发现设计存在的缺陷。
第二个观点是,集成测试应该涵盖单元测试所无法涉及的那一部分,尤其是数据库。
典型的单元测试理念通常认为,对于代码之外的部分,包括文件/数据库以及各种第三方服务,都不属于单元测试的范围,通常是因为 1. 它们太慢;2. 不可靠;3. 不在“单元”的概念之内。可以说,为了快速反馈和 100% 通过等目标,单元测试和 TDD 是有意地忽略了这些内容。
但对于一个完整的程序来说,如果不去验证这些部分的正确性,那么程序是否可靠要画上一个大大的问号。特别是涉及比较复杂的数据库操作,往往是程序中错误的高发区,并且对于几乎所有系统来说,数据库都是无法避开的话题。不涉及这些内容的策略选择,使得单元测试在实践中发挥的作用要打一个很大的折扣。
和常规的的静态语言如 Java/C# 比起来,像 Python 这样的动态语言有自己独特的特点。虽然 Python 有好几种略有差别的数据库访问模块,比如 SqlAlchemy、Django ORM、Peewee 等,但是它们总体来说是比较类似的,都使用了类似 ActiveRecord 的设计风格,而很少像静态语言那样创建一大堆 DAO/Repository。这也使得在测试中要避开对这类 model (数据模型)的访问通常是不太现实的。实际上,出于这种理由,著名框架 Rails 的设计者 DHH(David Heinemeier Hansson)多年前就表达过对于单元测试的意见(你可以参考本文最后的链接)。他的基本观点是,为了满足单元测试的要求生成许多模拟对象,对于代码的清晰是有损害的,还不如直接在更高层次上进行测试。因为现代文件系统、数据库和本地网络已经足够稳定和快速,并不至于影响反馈的效果。
对 DHH 的意见在网络上有很多不同的解读。我个人基本同意 DHH 的意见:集成测试能够覆盖单元测试所忽略的那些领域,同时对软件质量仍然起到很好的保护作用。但这也是一个存在争议的话题,所以你可以有自己的看法。
集成测试还有第三个方面的意义,那就是性能度量(及优化)。
说到 Python 程序的性能,可能大家首先会想到的是 timeit 或者 cProfiler 这一类传统的性能分析工具。Python 性能分析领域的很多著作如《Python 性能分析》等也是从这个角度入手的。但我个人的看法是,从模块角度分析程序性能入手并不可取。当面对一个大型应用的时候,你很难清楚地知道哪里会是性能瓶颈,如果从函数角度去分析地话,通常必须基于某种程度的主观意见(“这里好像比较慢”),但这种主观感觉往往是不够可靠的,也缺乏全局视角。如果对整个程序都进行跟踪的话,则马上就被海量的信息淹没,同样会失去方向。
那么从接口/系统测试的层次衡量性能又如何?这是一个不错的角度,我们已经知道,诸如 JMeter/Selemium 等工具也正是从这个层面着手的。它能够得到的是从用户或者接口层面看到的程序性能。但我们也应该看到系统测试的局限性:它覆盖的范围非常大,通常需要完整的程序部署,且其结果是 Web 服务器、网络、客户端等诸多因素共同影响的结果。这样,虽然你能够看到整体的性能表现,也能知道系统的瓶颈在哪个接口,但缺乏内部视角,难以确定性能问题到底是由于哪方面的因素引起的。此外,如果团队尚未完成整个开发过程的自动化,那么系统测试通常需要在项目的后期才有机会进行,从而在快速反馈和指导开发方面不能起到很好的作用。
集成测试恰好处于单元测试和系统测试的中间位置。和单元测试相比,它会涉及到针对众多基础设施和外部服务的访问,因此具有比较宽广的视角,能够充分了解到这些基础设施的运行情况;和系统测试比起来,它又比较存粹,排除 UI 界面或者外部调用的影响,能够得到内部的、应用服务器本身的性能信息。当然,我们最终关注的还是整体性能,但通常来讲,集成测试的结果已经能够在很大程度上代表应用程序的最终表现。还记得我们曾说过,不同层次的测试应该有所侧重吗?通常来讲,系统级别的测试首先关注的应该是正确性,那么在集成测试的层面上,我们不应该做太多重复的工作,而是更多地关注性能问题。同时,集成测试能够得到很多组件、基础设施和外部服务的运行数据————这是在接口层面通常很难获得的————对性能分析也优化也有着重要的意义。
综上所述,集成测试应该发现一些潜在的正确性和设计问题(但主要还是作为单元测试的补充和额外的保险),而更应当关注的应当是性能方面的表现。由于集成测试不像系统测试那样需要完整的部署,因此通常可以、也应该由程序员来执行。当然,在实施了开发过程自动化的团队中,让集成测试定期自动执行并生成报告也是一个不错的主意。
环境与需求
为了说明一个集成测试的设计,本示例将使用典型的 Flask 应用架构,即 Python + Flask + SqlAlchemy 的组合,数据库使用 Postgresql。在较大的应用中,我们可能还要关注其他一些服务如缓存、队列和搜索的性能,但把这些内容都加进来会把这个话题变得过于复杂。为了清晰起见,这里的案例着重关注数据库方面的性能,对于其他服务的度量,其基本思想是类似的。
为了对测试结果进行分析以评估效果,我们并不需要编写大量代码去处理测试结果,而是可以借助一些流行的数据分析工具,包括:
- pandas
- matplotlib
- jupyter
本文使用的都是上述框架中比较核心的功能,不太可能随着时间而过时。为了完整性,这里还是列出协作本文时使用的版本,以供参考。如果您对本文的设计或代码有疑问的话,请首先检查版本:
- Python=3.6.7
- Flask=1.1.1
- SqlAlchemy=1.3.6
- pandas=0.25.0
- matplotlib=3.1.1
- jupyter=1.0.0
我们已经知道,集成测试基本上没有什么现成的工具,而是需要我们自己编写一些代码。虽然也有很多开发者用单元测试框架来进行集成测试,但对我们的目标————每个测试应该包含本身和数据库方面的性能度量数据————而言,单元测试并不能满足我们的要求。因此,集成测试通常需要我们自己编写一些代码。好在集成测试的原理和代码并不复杂,本例的程序总共用了大约 300 多行,加上部分 Jupyter Notebook 代码也不过 400 行左右。在理解原理的基础上,基本上最多半天时间完全可以自己制作一个基本的框架出来。由于集成测试本身的特点,它和特定项目和架构通常有比较紧密的绑定关系,追求代码级别的复用是不太现实的,但原理都差不多,因此我鼓励大家亲自去实践。
原理
由于 Web 程序有着简单明晰的请求-响应模型,并且和框架的设计天然是匹配的,所以是一个非常好的切入点,基本上所有系统测试都选择在接口级别进行测试。我们的集成测试通常也应该选择这个粒度,从而和系统/接口测试形成明确的对应关系,便于查找和定位问题。
我们首先需要了解的是,对于 Flask 框架而言,如何才能从接口层次进行测试。
Flask
Flask 对于执行集成测试有着很好的支持。最核心的接口是 app.test_client() 方法,它返回的是一个 FlaskClient 类型的对象。如果你比较熟悉 Flask 的话,应当知道,绝大部分框架相关的代码都需要在 app_context 的上下文中才能正常执行。因此,一个基本的测试样板代码是这样的:
app_ctx = current_app.app_context()
app_ctx.push()
client = current_app.test_client(use_cookies=True)
resp = client.get(url_for('/home.index'))
# TODO: 验证结果
app_ctx.pop()
以上代码对首页执行了 HTTP GET 请求,并且隐含了视图响应和模板渲染的完整调用链,可以视为一次完整的服务调用过程。对于 POST 请求而言,则需要增加一个提交表单参数(相同的代码已省略):
resp = client.post('/test_form', data={
'field': 'value'
})
如果 Flask 是作为数据服务而使用(因此产生的结果不是 HTML 而是 JSON 数据),但是从测试的角度来讲,调用方法是完全相同的,并没有什么本质的不同。
顺便说一下,如果你使用的服务器框架是 Django 而不是 Flask,那么 Django 也有着非常相似的 Test Client 接口。应该说,作为 Web 框架的晚辈,Flask 在设计的时候从 Django 那里“偷”来了不少优秀的接口设计,所以这两个框架在很多方面都有着类似的地方,这并不奇怪。
登录
对于一般的 Web 应用,我们还需要考虑几个问题。最典型的是,对于那些需要登录才能访问的页面该怎么办。
最直观的想法是首先调用登录页面:
resp = client.post(url_for('auth.login'), data={
'username': '...',
'password': '...'
})
该方法最容易理解,也是完全可以工作的,因此已经被广泛采用。但是也有人对此方案表示过担心,因为把登录密码写在程序里通常会被视为有安全隐患。如果在开发流程上能够保证只使用测试用户登录,并且在生产环境中将测试用户禁用的话,那么这也许不构成什么问题。要是这样做无法接受的话,那么也可以采用如下另外一种思路:即调用框架提供的“后门”接口自动登录指定用户,并在生产环境中禁用该代码,以杜绝安全隐患。
import os
from flask_login import login_user
if os.getenv('FLASK_ENV') == 'test':
@app.rout('/test_login')
def test_login():
login_user(User.get_by_name('test'))
client.post('/test_login')
对于了解 HTTP 基础知识的同学,test_client 是个设计良好且容易理解的接口。尽管我们在这里无法覆盖它的所有细节,但是对于如何使用 PUT/DELETE 方法,如何添加自定义的 HTTP Headers,相信大家应该都能猜想得到。
错误处理
通常,我们希望知道测试过程中是否发生了异常(并且记录下来)。但是,为此我们需要了解 Flask 框架有关错误处理的一个小细节。在默认情况下,Flask 会在内部处理异常,并在进行一系列逻辑处理以后转发给 app.errorhandler。这意味着如果我们按照如下方式编写代码,那么将无法如预期的那样捕捉到异常:
try:
client.get('/a_error_view')
except:
print('This error cannot be caught!')
当然,我们也可以选择在 app.errorhandler 中捕获异常,但那样意味着测试代码“侵入”了正常的逻辑,这并不是一个好的设计。那该怎样解决这个问题呢?实际上做法很简单,设置 app 的一个属性即可。但是该细节在 Flask 文档中只是一笔带过,大多数教程或文章也没有提到,相信有很多同学并不清楚。示例代码如下:
app.testing = True
try:
client.get('/a_error_view')
except:
print('Now you seee the error here.')
testing 会修改 Flask 框架的一些细微的行为,特别是和测试相关的部分,但一般来说不会影响正常的业务逻辑。如果你想了解该内容的细节,请在官方文档中查找 test_client 方法相关的部分。
SqlAlchemy
为什么要关注 SqlAlchemy?因为在典型的 Web 应用中,数据库通常是主要的性能瓶颈,也是重要的优化目标。在框架级别,你可以很容易地与 SqlAlchemy 这样的数据访问框架交互,获得一些其内部的运行信息,比如调用的语句数量、执行时间等等。这些数据对于分析和评估性能有着很大的意义,而在单元测试和系统测试级别并没有直接的方法可以获得这些信息,也是集成测试的重要优势之一。
当然,我们也可以选择在数据库比如 Postgresql 的角度来获取运行信息,但问题在于这样将很难确定每条查询和代码之间的对应关系。一般来讲,从数据访问的层面来获取这些信息是最可取的选择。
对于 SqlAlchemy 如何支持运行信息的官方资料,你可以参考本文最后的链接。基本原理是关注以下两个事件:
from sqlalchemy import event
from sqlalchemy.engine import Engine
@event.listens_for(Engine, "before_cursor_execute")
def before_cursor_execute(conn, cursor, statement, parameters, context, executemany):
print('begin query')
@event.listens_for(Engine, "after_cursor_execute")
def after_cursor_execute(conn, cursor, statement, parameters, context, executemany):
print('after query')
我们看到,方法是很简单的,但是我们的测试需要找到一个办法,将查询的执行与特定的接口关联起来。在代码部分我们会看到这是如何实现的。
实践
原理我们到这里已经了解得差不多了,现在我们来具体开发一个实际的集成测试。首先从设计的角度看看,一个测试程序应该具有哪些组成部分。
测试用例
我们的测试主要是针对 URL 端点(在 Flask 的术语中称为 endpoint) 执行的。有些端点(比如首页)很简单,不需要任何参数。但大部分数据驱动的页面是需要参数的,比如 /order/1, /user/davy。至于 POST 请求则更加复杂,它可能包含 URL 参数,此外还包括 POST 请求的参数。总结起来,绝大部分请求基本上可归类为三种形式:
| endpoint | 方法 | URL 参数 | 表单参数 | 执行次数 |
|---|---|---|---|---|
| / | GET | 100 | ||
| /users/ |
GET | 1,2,3... | 10 | |
| /user/1/orders | POST | 1,2,3... | { page:1 } | 200 |
既然说到了 POST 请求,那么这里也要考虑一下 POST 对于测试的影响。我们知道 GET 请求是幂等的(原则上),彼此之间不会互相影响,所以它们执行多少、顺序如何都没有关系。但是 POST 请求则可能会对后续的测试早成影响。我们的集成测试需要记录程序中可能产生的异常,但对于各个请求结果是否正确,这并不是集成测试应该关注的主要目标(一般来说,单元测试和 UAT 应该关注程序的正确性)。因此,CRUD 中的 Create/Update 操作通常不会对集成测试造成什么障碍,但 DELETE 操作就需要小心了。如果删除操作并不是非常频繁的话(多数常规 Web 程序应该属于此类),那么从测试中排除删除请求是最简单的方法。否则的话,我们需要考虑在测试之后重置数据库状态,以避免出现潜在的问题。
有些同学可能也注意到了表格最后一列的执行次数参数。该参数主要包括几方面的作用: - 一是多次执行某个测试,以排除偶然因素导致数据不准确; - 二是对于参数化的测试,允许测试多次,每次使用不同的参数,以接近真实的运行情况,避免总是使用固定的“热点”数据。为此,测试程序需要提供一种机制,让测试能够在运行时从一批候选参数中随机选择; - 三是通过修改参数的大小,改变各个测试结果在整个测试集中的权重,以模拟用户的使用偏好,更好地反应真实的程序性能。当然,如何选择合适的数值也是个问题。如果你关注的重点是改善程序性能,那么随便分配一个也没有关系,因为这时候我们关注的是性能指标的变化情况,而不是数字值本身。当你在线上积累一定的网站分析数据以后,可能会对如何分配执行比例有一个更加客观的方案。
设计
经过以上设计,代码方案就很明显了。 以下是一个基本的设计方案:
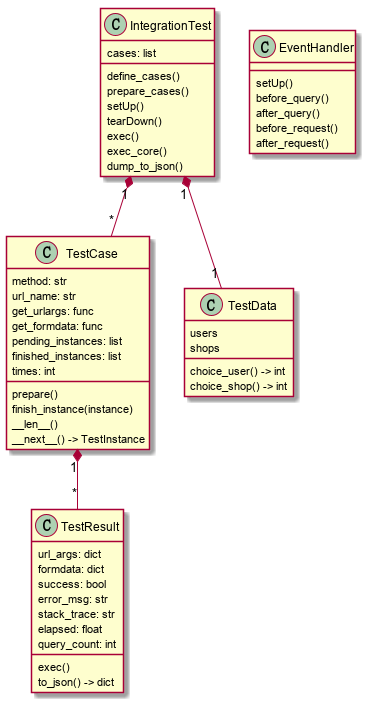
- IntegrationTest 代表集成测试,它记录需要执行的所有测试用例(
cases)。其主要方法exec()将依次执行各个用例(但为模拟实际情况,实际上会采取乱序执行的方式),最后通过dump_to_json()将测试结果记录到文件; - TestCase 表示某个特定的测试用例(从单元测试借用来的概念)。简单的测试只需要端点名称(
url_name),而复杂的用例则需要提供参数(URL /表单参数等)。你可能会注意到 TestCase 的设计使用了 pythonic 的方式,比如 len() 和 next() 协议,这主要是为了方便提供测试内容给 IntegrationTest 使用。 - TestInstance 代表测试用例的一次执行结果。它需要在执行测试之后,记录本次执行的耗用时间、是否成功、数据访问时间等跟踪信息,用于后续的结果分析。
- TestData 用于给测试提供参数。为此,它需要从测试数据库中选择一批有代表性的数据。该类与项目的结构与业务逻辑紧密相关,也是整个结构中最难以复用的部分。
- EventHandler 是一个比较独立的对象。它的主要作用是侦听特定事件,包括测试用例的开始/结束执行,以及我们介绍过的数据访问接口,并将它们关联起来。
主要代码
为了方便参考,我在这里列出该测试所实现的主要代码。为了节约篇幅,部分和业务逻辑相关、以及比较次要的部分将会忽略。首先我们从入口点说起。
入口点:
为了便于从命令行执行,我们可以把测试实现为一条 Flask 命令。Flask 对于添加自定义命令有非常方便的接口:
@app.cli.command(name='integration_test')
def command():
current_app.testing = True
test = IntegrationTest()
test.exec()
json_path = os.path.join(current_app.root_path, '../data/analytics.json')
test.dump_to_json(file_path)
准备/清理测试环境
然后是集成测试的主体。按照我们介绍过的原理,它首先准备和清理测试环境:
class IntegrationTest:
...
def setUp(self):
self.app_ctx = current_app.app_context()
self.app_ctx.push()
self.client = current_app.test_client(use_cookies=True)
create_redis().flushall()
def tearDown(self):
db.session.remove()
self.app_ctx.pop()
self.app_ctx = None
def exec(self):
self.setUp()
try:
self.define_cases()
self.prepare_cases()
self.exec_core()
finally:
self.tearDown()
在初始化的同时,我们也应当重设一下系统中用到的、可能有影响的外部服务(比如 Redis 缓存),以保证得到稳定的测试结果。
准备测试
接下来准备测试用例。由于 GET/POST 参数有所不同,所以我们分两路进行。
def define_cases(self):
for url_name, get_urlargs in [
('home.index', None),
('user.index', self.data.user_kwargs),
...
]:
self.add_case(url_name, 'GET', get_urlargs)
for url_name, get_urlargs, get_formdata in [
('user.query', self.data.user_query_args, self.data.user_query_formdata),
...
]:
self.add_case(url_name, 'POST', get_kwargs)
执行测试
为了接近真实情况,我们从候选测试中随机抽取执行。TestCase 实现了 Python 风格的 len()/next() 等协议,所以这里的写法可以得到一定程度的简化:
def exec_core(self):
while True:
candidates = [x for x in self.cases if x]
if not candidates:
break
case = random.choice(candidates)
instance = next(case)
instance.exec()
case.set_finished(instance)
单个用例执行
由于我们的程序只用到 GET/POST 请求,所以这里的实现比较简略。支持其他方法只要稍微扩展一下即可:
def exec(self):
client = self.case.root.client
event_handler.before_request(self)
try:
url = url_for(self.case.url_name, **self.urlargs)
if self.case.method == 'GET':
client.get(url)
else:
client.post(url, data=self.formdata)
except Exception as e:
self.success = False
self.error_msg = str(e)
self.stack_trace = traceback.format_exc()
finally:
event_handler.after_request(self)
这里在执行测试的同时也发出了事件通知。而事件通知的处理则需要跟踪并记录运行数据:
class EventHandler:
def elapsed(self, begin_time):
return (datetime.now() - start_time).total_seconds()
def before_query(self):
self.query_time = datetime.now()
def after_query(self):
self.query_count += 1
self.query_elapsed += self.elapsed(self.query_time)
def before_request(self, result):
result.query_count = 0
result.query_elapsed = 0
result.request_time = datetime.now()
self.query_count = 0
self.query_elapsed = 0
def after_request(self, result):
result.elapsed = self.elapsed(result.request_time)
result.query_count = self.query_count
result.query_elapsed = self.query_elapsed
该方法记录了测试时间、数据查询次数和查询耗费时间。需要说明的是,这里有一个隐含的假设,即所有测试是串行执行的,因此不需要考虑并发问题。鉴于 Python GIL 的存在,用多线程方式执行测试几乎没有什么意义,除非采用多进程方式。在多进程方式下,我们可能需要考虑用一个 multiprocessing.Queue 来传递数据。
所有测试执行完毕后,我们会把结果输出到一个 JSON 文件中。在最简单的情况下,该文件可以是一个平面记录文件,大概类似这样:
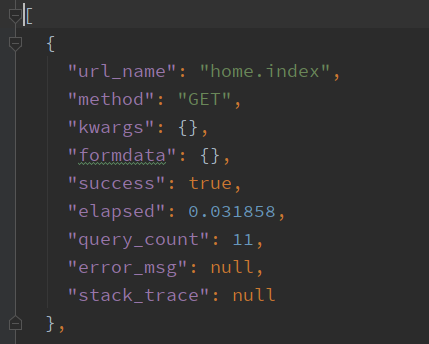
接下来,我们借助一些工具,根据文件内容进行性能分析。
结果分析与优化
Python 一个显著的优势是拥有非常丰富和全面的数据分析工具。鉴于测试结果已经输出到 JSON,我们可以在几乎无需编写代码的前提下,借助 Jupyter Notebook(以及 pandas/matplotlib)等辅助工具,对结果进行可视化、交互式的分析。
当然,对于数据分析来说,上述工具有一些已经显得有点“古老”,有的同学可能觉得它们不够酷。但是对于测试结果分析这个目的而言,上述工具已经足够好用(我们看重的是信息,外观粗糙一些无关紧要),因此我们将继续沿用它们。
基本信息
我们在一个 Jupyter Notebook 中打开它们。首先调用 pandas.read_json() 方法,打开我们生成的数据文件,并显示测试的全局信息:
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
df = pd.read_json('analytics.json')
df.describe()
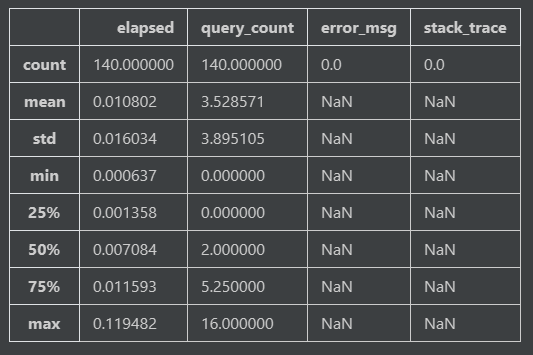
从结果我们可以看到,本次测试总共执行了 140 个测试(为了让后续的图表不至于过于复杂,我排除了一些次要的测试),没有出现错误(很好)。平均每个请求大概需要 0.01 秒的反应时间(也还不错),但是耗时最长的请求花费了 0.12 秒的时间,请求期间最多调用 16 次查询。这个结果就存在比较明显的性能问题了。
数据分布
为了更好的看清测试结果的分布情况,我们再利用 pandas 生成关于执行时间和查询数量的柱状图。它们分别对应于结果的 elapsed 和 query_count 字段:
df.elapsed.hist()
df.query_count.hist()
结果如下:
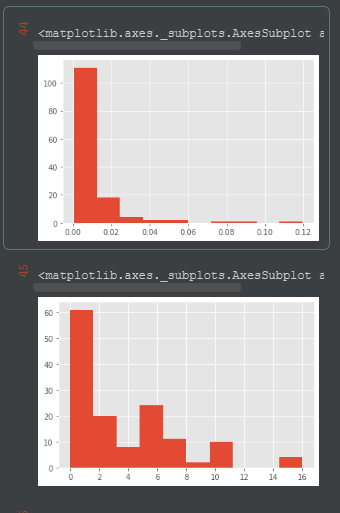
这是一个典型的性能测试结果:少数页面具有突出的性能问题。可以说,这是一个“好”的结果,因为只要能够显著提升一两个页面的响应时间,我们性能优化的工作几乎就完成了。至于其他页面,对整体性能的影响非常之小,如果我们花费的精力不是在优化头部几个页面的话,那就等于是在做无用功。(尽管经济学上会讲“长尾效应”,但是每个优化都是需要付出成本的,对长尾部分进行优化是非常不明智的举动)。
在非瓶颈的地方进行性能优化是浪费时间。
查看瓶颈
我们已经发现了性能瓶颈,但还不知道它具体对应到哪个端点。利用 pandas 输出烛台图可以帮我们找到这个信息。
df.boxplot(column='elapsed', by='url_name', figsize=(20, 7))
结果如下:
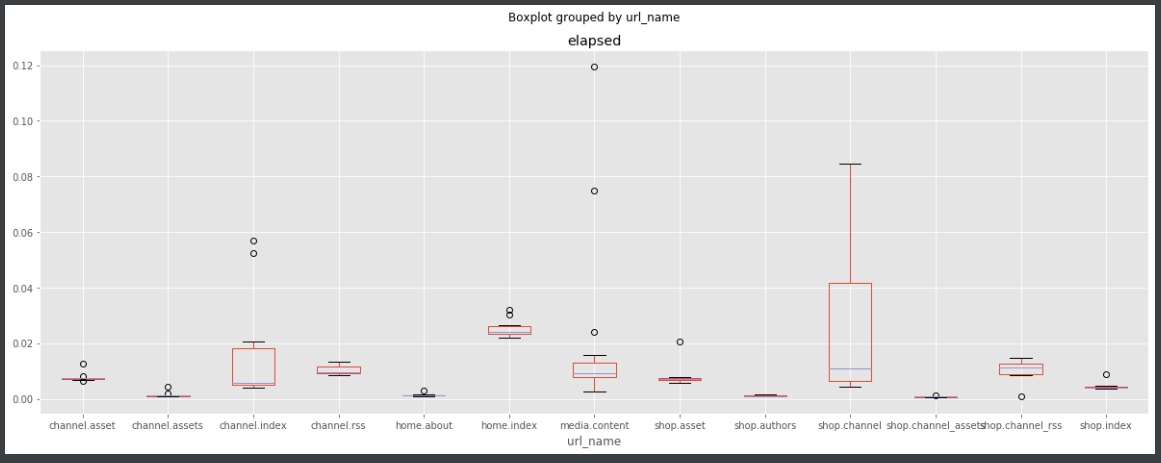
从图中我们可以看到,性能焦点所在的端点是 shop.channel。
查找问题
现在问题已经定位到特定的端点。如果代码不是特别复杂的话,不一定要动用 cProfiler 等工具,大概浏览一下代码,通常也能大概猜到问题在哪里。
对于该例而言,其实方法本身并没有太大问题,而在于模板中有类似这样的语句:
{% for channel in shop.available_channels() %}
<a href={{ channel.url }}>{{ channel.name }}</a>
{% endfor %}
问题在于,available_chanels() 在背后实际上是发起了一次查询,而这个问题通过 for 循环又被放大了。虽然现在看起来很明显,但是在一个庞大的代码库中,如果不通过集成测试的帮助,我们通常很难意识到存在这样的问题。
要解决这个问题,我们应该尽量在一次查询中获得尽可能多的数据。由于本程序使用 postgresql 数据库,因此我们可以使用数据库支持的 partition by 语句,一次性获得所有的记录。但是将 partition by 映射到 SqlAlchemy 的方法调用有点棘手。基本上有两种方式,一种是通过 SqlAlchemy 本身提供的接口:
@classmethod
def get_partitions_api(cls, shop_id: int, count: int):
from sqlalchemy import func
subquery = db.session.query(cls,
func.rank().over(order_by=cls.update_at.desc(),
partition_by=cls.shop_id).label('rnk')
).subquery()
query = db.session.query(subquery) \
.filter(cls.shop_id == shop_id, subquery.c.rnk <= count)
return query
第二种方法则更依赖于原生的 SQL:
@classmethod
def get_partitions_raw(cls, shop_id: int, count: int):
from sqlalchemy.sql import text
sql = """select * from (
select channels.*, rank() over (partition by shop_id order by update_at desc) as pos
from channels where shop_id=:shop_id) as ss where pos<=:count"""
return db.session.query(cls) \
.from_statement(text(sql)) \
.params(channel_id=channel_id, count=count) \
.all()
说实话,虽然第一种是 SqlAlchemy 内置的接口,但实在是过于复杂,并且一旦出现错误,不清楚内部原理的同学恐怕很难自己解决。第二种方法则很容易验证其正确性,也比较容易理解(虽然也有它的问题)。我个人强烈建议使用第二种方法。
修改实现以后重新测试,这次得到的整体结果如下:
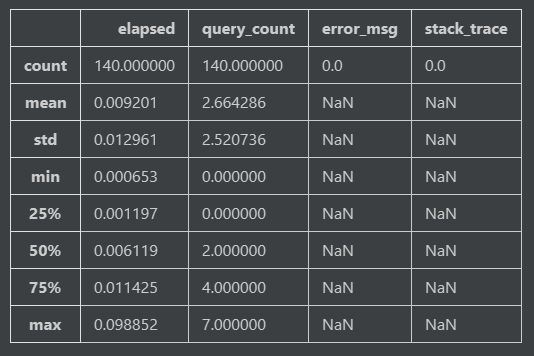
和第一次的结果比较,我们会发现,几乎所有指标都有所改善,特别是调用的查询数量从 16 减少到了 7。但性能提升可能没有预期的那么高(18%)左右。这可能意味着还有需要提升的空间,但重要的是,我们看到集成测试为性能优化指明了方向,不再是靠猜测去优化了。
但同时我们也应该看到,性能优化也有一些负面的作用。最主要的地方在于,代码虽然性能有所提升,但同时也变得不那么直观和易读了。此外,引入 SQL 也隐含地让代码变得脆弱了一点,数据库的变更或无意修改了字符串都可能导致问题。因此,这里存在一定的权衡,首先应当考虑针对新增的代码补充一些回归测试。同时,如果有其他手段可以补偿性能(比如缓存)的话,那么也不一定要在数据访问的层面进行修改。
扩展
对测试的讨论到此告一段落。本示例是一个比较基本的集成测试实现,完成整个测试代码用了大概 400 行左右,加上少许 Notebook 代码,有经验的同学应该不难自己实现一个出来。前面也提到过,集成测试的主要优点是能够在代码级别得到关于服务器框架、数据库与 ORM、以及其他服务的很多内部信息;而缺点也是由于和框架紧密相关,所以不太容易形成通用的解决方案。当然,基本思想是通用的。本文介绍的只是一个基本的、服务于特定应用的集成测试案例,相信大家看过以后,结合自己的实际经验,能够设计出更好的测试程序。
以下介绍一些可能的提升和扩展之处。
记录 SQL 语句
当你发现某个端点存在性能瓶颈的时候,你可能会希望进一步跟踪调用该端点时发生了哪些数据库查询,以找出问题的具体所在。
对于 Flask/SqlAlchemy,在配置中定义 SQLALCHEMY_ECHO = True 可以开启全局跟踪。但是这样的话输出内容实在太多,如果不结合其他工具进行整理的话,几乎无法使用。
在前面我们已经介绍过通过事件跟踪 SqlAlchemy 执行语句的方法,稍作修改,你可以实现诸如针对特定访问才输出语句这样的功能。
并发执行
本案例中的测试数量并不太多,且大多执行很快,很快就能得到结果,因此并不需要特别考虑效率问题。
如果测试数量很多,或执行事件较长,将大大加长整体时间,不利于迅速得到反馈信息。这时你可以考虑将测试改为多进程架构,让多个测试并发执行(多线程在这种情况下意义不大),通过 multiprocessing.Queue 或者 Redis 这样的服务来传递测试结果。但相应地,测试的实现也会更加复杂和容易出错,需要细心设计。
自动化
很容易把集成测试写成一个命令,并通过 Flask 命令行调用(本案例实际上就是这么做的)。更进一步,你可以考虑把命令放到 持续集成服务器比如 Jenkins 中,让它在签入代码时自动执行,并自动创建结果报告。
尽管自动化从技术角度讲绝对是好事,但参照自己过去的经验,我还有一些顾虑的。按照我的经验,部分开发人员,特别是一些项目管理者,会迷恋于漂亮的图表和报告,甚至为得到一些好看的数字而让开发者做手脚(面向KPI开发?)这会让测试的努力失去意义,甚至得到负面效果。从团队角度讲,比起某些具体的数字,我们应该更关注变化的趋势,比如性能指标是否随着团队的工作进展而稳定提升(好兆头),或者在某个时间点出现剧烈的变化(通常意味着有些事情需要注意)。总之,对于测试这件事情,我们还是务实一点好。
性能优化
我们的示例已经说明了如何用集成测试来指导性能优化。对于性能优化,虽然其基本原则(比如“过早优化是万恶之源”)应该已经是尽人皆知了,但在实践中,很多项目还是在用猜测和盲目尝试的方式去优化,这是应当反对的。因此,这里再总结性能分析和优化应当遵循的一些规则:
- 首先也是最重要的一条,必须有一套可行的性能分析和评估体系(集成测试是方法之一)。没有这个大前提,任何优化工作都是在撞大运。
- 性能优化也应该遵循“单一职责”原则。这就是说,如果本次工作的目标是性能,那就只做性能优化。不要试图顺手做一些其他工作(比如整理代码)————你可以留下备注,在下一次迭代中完成。
- 在测试前后运行性能分析并对比。“好”的性能应该满足:
- 对目标接口的优化有明显作用(“明显”的定义视乎根据具体要求而定)
- 对其他接口性能没有显著影响。也许你认为有正面影响应该是件好事。从结果来说,是的,但这有时候也意味着两个接口存在着不应出现的依赖关系,因此值得关注和评估
- 如果在提高性能的同时,可读性有所降低,有时候我们不得不面对这种选择,但同时也应该问一问,有没有其他选择?我们能通过其他手段(比如补充一些测试)来弥补这种不良影响吗?
- 最后,如果有可能的话,考虑将这个过程自动化。但请记住,自动化只是工具,分析和评估工作最终还是应当由人来完成!