说透 CSV 格式
CSV 这么简单的格式,需要单独一篇文章来说明吗?其实细节隐藏在魔鬼之中,我们过去的团队在生成 CSV 内容的时候,由于兼容性问题也是吃过苦头的。因此,我觉得还是有必要写一篇文章,从各个方面把这个格式彻底讲透。
本文将介绍:
- CSV 格式的来源、历史背景和规范化情况;
- 规范化的 CSV 格式要求与实际支持情况;
- Python 内置库与第三方库处理 CSV 的接口与细节;
- 处理 CSV 格式应该注意的常见问题和注意事项。
历史背景
CSV 格式的诞生甚至比个人计算机(PC)更早。在上个世纪 70 年代的 IBM FORTRAN 77 已经定义了用逗号或空格作为文本定界符的处理方式,当时它被称为列表导向的 IO(List-Directed Input/Output )。
CSV 的名称大约是在 1983 年出现的。伴随着电子表格软件的兴起,人们发现该格式和电子表格存在天然的关联。并且由于使用人类可读的文本形式,而不是计算机可读的二进制格式,不仅使得操作员能够理解、分析和处理它们,也避免了不同机器之间的体系差异带来的问题,所以很快成为数据交换的流行选择。在早期电子表格软件 SuperCalc 手册中首次给了它名字:逗号分隔的值(Comma-Separated-Value),并规定了文件格式和处理方法。

当然,用户手册是从具体使用角度出发的,并未给 CSV 格式一个非常严格的定义。2005 年,国际标准化组织 IETF 通过 RFC4180 正式定义了 CSV 文件的格式要求。2014 年,又通过 RFC7111 补充规定了 CSV 文件在 Web 应用中的一些规范,主要是 MIME Type 及 URL 片段的正式约定。
2015 年,W3C 给表格化的数据/元数据制定了一个推荐草案,试图将数据的格式和使用方法进行规范化,其中也包含了对 CSV 格式的要求。
上述规范的原始地址请参阅文章最后的引用部分。
CSV 格式在发展过程中也逐渐演变出其他一些分支和变种。从名字(Comma-Separated-Value)可以看出,坚持使用逗号才是正规的做法。但有些程序也开始使用 Tab 或管道符(|),甚至其他更多符号来进行分割。 在格式变化的同时,有的程序继续沿用 CSV 的名称,有的则引入了其他稍有变化的名字,比如 DSV(Delimiter-Separated Values)。这使得局面变得有点混乱,而这种混乱,到现在仍然在延续...
今天,CSV 仍然是数据交换的主流格式之一,所有电子表格软件包括 Excel 在内都支持它,在 Python 标准库中也内置了用于处理该格式的 csv 模块。其他很多与数据处理相关的第三方软件包也几乎都支持 CSV 格式。
看过了 CSV 格式的发展历史,接下来我们来了解该格式的规范详情,包括一些不太为人所知、但在具体处理时往往容易出错的细节。
格式规范
CSV 的基本格式是逗号分隔的一系列字段。同时规范要求,所有字段都可以用引用符号(通常是双引号 " )包围起来。因此,以下两行数据在语义上是完全相同的:
shenzhen,2019,china
"shenzhen","2019","china"
至于何时应该加引号、何时不加,规范并无明确要求,而是把这个决定留给应用程序。但如果字段内容中出现了逗号,为了避免歧义,就必须加上引号。此外,如果字段内容中存在空白字符的话,为了明确起见,一般也建议加上:
shenzhen,"Oct 2019","Guangdong, China"
引号也用来表达跨越多行的字段内容:
shenzhen,2019,"The 1st line.
The 2nd line."
如果字段内容中本来就有引号,该怎么办呢?那就需要在前面再加一个引号。比如:
shenzhen,2019,"known as ""Special region"""
你可能在某些地方看到类似 C 语言的转义符用方法:
shenzhen,2019,"known as \"Special region\""
但这只是部分程序的行为,并不是规范的做法,也不为许多标准的 CSV 库所支持。
如果使用引号的话,还需要注意:按照规范要求,引号与逗号之间不应该存在空白。因此,下面的内容严格来说是非法的:
"shenzhen" , "2019" , "china"
但对于类似这样的错误该如何处理,标准也没有明确规定。有些“聪明”的软件会自动尝试去掉空格。但 Python 内置的 CSV 库对此的处理是返回包含空格和引号在内的值,作为字段内容。比如,上述第二个字段会返回' "2019" '。你不妨自行尝试一下。
除了上述场景以外,标准的 CSV 还应遵循如下要求:
- 所有行应该拥有相同数量的字段;
- 换行符应统一使用 CRLF;
- 可以有一个可选的标题行。但文件中到底是否包含标题,并无确定的方法来指定,而是留给开发者自己判断。
规范也没有指定 CSV 应使用何种字符编码。但 RFC7111 有一个补充说明:在 Web 服务器上使用的时候,标准的 MIME Type 应该为 text/csv,像其他文本格式一样,可以有一个可选的编码。因此,CSV 内容的头部信息应该类似这样:
Content-Type: text/csv; charset=utf-8
如果没有指定 charset 的话,客户端应该假定编码是 UTF-8。
上面给出的是 RFC 规范要求的 CSV 标准格式。我们已经知道,在 CSV 的发展过程中出现了一些变种,而这些变化并未体现在 RFC 规范中。为了兼容现有程序,让 CSV 的处理具有更大的灵活性,数据标准化组织 ODI (Open Data Institute)制定了一个辅助规范,称为方言(CSV Dialect)。通过指定不同的方言,允许对 CSV 的处理有一定灵活性,比如说,使用其他的分隔符、引用符号或换行,等等。上述规范的原始地址请参考本文后面的链接。Python 的 CSV 库也支持方言的概念,我们会在后续的部分加以说明。
由以上讨论可知,CSV 虽然是一个简单的文本格式,但仍然有不少需要处理的细节,完整实现这些规范对普通程序员来说并不是太轻松的任务。由于部分编程语言并没有内置对 CSV 格式的支持,所以有些开发者遇到相关需求时,往往会把这件事看得很容易,以至于直接自己手撸一个 CSV 库出来。但是不客气地说,它们通常是有 bug 的,并未考虑很多边缘情况。因此,我还是建议大家花点时间去寻找稳定成熟的类库,尽量避免自己从头写。
我们也看到,规范对于具体处理过程中一些边际场景和错误问题应该如何处理,并未做出详细说明,而是留给开发者自己决定。比如说,规范要求 CSV 的所有行应该拥有相同数量的字段。但如果真的遇到数量不同的内容,又该怎么处理?有些库会返回长度不定的数组,有些库则会出错,还有些库通过提供更丰富的参数来让开发者自定义行为。这就带来了在实际应用中,哪怕对于相同的 CSV,不同的库也可能彼此表现不同,无法互相兼容。如果要处理来自外部的 CSV 文件,我们也必须小心提防风险。了解 CSV 的具体规范有助于让我们知道在哪些环节可能发生问题,并作出必要的防范。假如对 CSV 的支持是一个非常重要的需求,不妨考虑把它提取出来作为单独的库/服务,对外提供统一的接口,避免让每个程序都实现一套自己的 CSV 读写逻辑,以防止可能出现的兼容性问题。
Python CSV 库
Python 内置了对 CSV 的支持,使用也很简单,可能不少同学已经用过了。我们会结合前面介绍过的 CSV 规范,重点介绍使用中应该注意的一些细节。
方言
前面我们说过,CSV 支持方言的概念。在 Python 中,我们可以通过以下方法列出 Python 内置支持的所有方言:
>>> csv.list_dialects()
['excel', 'excel-tab', 'unix']
可以看到,Python 内置了三种方言。顾名思义,excel 和 unix 分别用来兼容对应的系统。而 exel-tab 和 excel 的唯一区别是它使用 Tab 作为分隔符。
如果你很好奇的话,我们也可以打开源码,看看它们各自指定了哪些选项:
class excel(Dialect):
"""Describe the usual properties of Excel-generated CSV files."""
delimiter = ','
quotechar = '"'
doublequote = True
skipinitialspace = False
lineterminator = '\r\n'
quoting = QUOTE_MINIMAL
register_dialect("excel", excel)
class excel_tab(excel):
"""Describe the usual properties of Excel-generated TAB-delimited files."""
delimiter = '\t'
register_dialect("excel-tab", excel_tab)
class unix_dialect(Dialect):
"""Describe the usual properties of Unix-generated CSV files."""
delimiter = ','
quotechar = '"'
doublequote = True
skipinitialspace = False
lineterminator = '\n'
quoting = QUOTE_ALL
register_dialect("unix", unix_dialect)
很直白的代码,大多数参数的含义我们应该猜想得到,如果不太明白的话,可以参考官方文档。特别需要说明的是 quoting 这个选项,它用来指定何时需加在字段两边加引号的策略。有几种可能的选择:
- QUOTE_NONE 永远不加引号
- QUOTE_MINIMAL 只有字段内容包含逗号等界定符的时候才添加
- QUOTE_ALL 总是添加引号
- QUOTE_NONNUMERIC 对所有非数字的字段添加引号
如果有必要的话,我们也可以像上述代码一样定义自己的方言,并且用 csv.register_dialect() 来注册它。但需要自己定义方言的场合应该很少,这里就不再展开了。
读写 CSV
Python csv 模块用来读写 CSV 文件的主要接口是 reader/writer。reader 的构造方法如下:
csv.reader(csvfile, dialect='excel', **fmtparams)
关于 dialect 我们在前面已经介绍过了。csvfile 用来读取实际数据,它可以是任何返回字符串的迭代对象,包括文件流或字符串数组都是可以的。而命令参数 fmtparams 其实就是 dialect 所定义的一系列选项,可以进一步细化处理方式,比如:
reader = csv.reader(csvfile, delimiter="|", quotechar="'")
for item in reader:
print(item)
writer 就是 reader 的反向操作,接口也非常相似。输出实际内容时要使用 writerow:
with open(filename, 'w', newline='') as f:
writer = csv.writer(f, dialect='excel')
writer.writerow(['item 1', 'item, 2', 'item "3"'])
需要注意的是,如果打开的是文件,我们应该指定 newline=''。由于 csv 方言本身就会通过 lineterminator 来控制换行,如果文件本身再输出的话,就会出现多余的空白行,这是我们不希望看到的。
如果 CSV 文件包含标题的话,我们可以用 DictReader/DictWriter 来读写它们。csv 模块甚至还提供了一个 Sniffer 类用来探测 CSV 文件,判断它使用了什么方言、是否包含标题等信息。但从前面的介绍我们也能想到,这个判断并不保证 100% 准确,很多情况下还是通过明确指定这些信息更为可靠。
第三方库
除 Python 内置类库之外,很多用于数据分析的第三方库也支持 CSV 格式。比如 pandas 这个功能强大的库,它的调用接口简直复杂到令人叹为观止的地步:
pandas.read_csv(filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]], sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
当然,其中大多数参数是可选的,因而实际使用过程中并没有看上去的那么恐怖。其中部分参数和 Python csv 模块存在对应关系,且名字也大体相同:
- dialect
- sep, delimiter (它们实质上是同一参数的不同叫法)
- lineterminator
- doublequote
- quotechar
- quoting
- escapechar
read_csv 的其他参数则大多是用于处理数据的,与 CSV 没有直接关系。只要我们掌握 Python csv 模块的用法,pandas.read_csv 也没有那么可怕了。
应用程序支持
Excel
大多数项目中,我们需要考虑 CSV 文件对 Excel 的兼容性。虽然这主要是 Excel 的使用问题,出于实际需求,还是在这里顺便提一下。
如果我们在 Excel 中导入 CSV 文件的话,会看到如下的向导。Excel 对 CSV 的处理不像编程语言有那么多选项,我们能控制的主要包括文件编码、是否包含标题以及分隔符等:
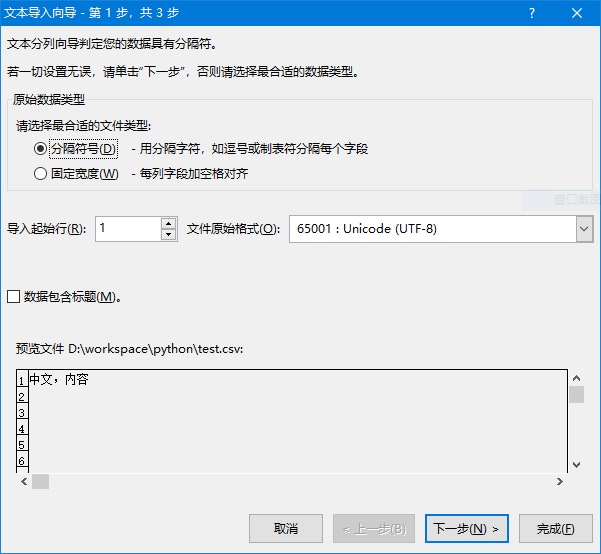
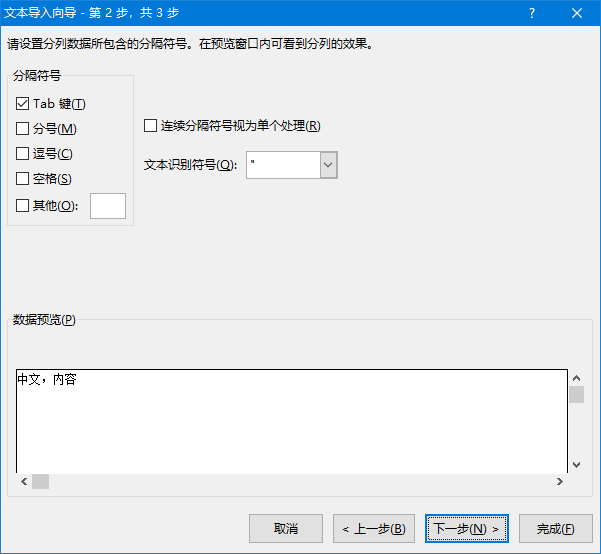
考虑到现实中 Excel 操作人员未必很了解图中这些选项代表的意义,如果我们让他们自己选择的话,很可能会出现问题。因此,如果输出 CSV 主要以 Excel 为目标的话,对于文件编码、分隔符等选项,应该尽可能使用 Excel 的默认值,避免让用户手工调整。
据测试,Excel 2010 以后的版本对 UTF-8 编码支持较好,当我们打开一个以 UTF-8 编码的文件时通常能正确识别它们。而 2007 之前的版本就比较糟糕,可能呈现出一团乱码。如果你不得不支持这些老版本,且内容包含中文的话,请考虑使用 GBK 之类编码。
总结
本文主要介绍了 CSV 模块的历史背景、规范与使用细节、Python 内置库和第三方模块的使用及注意事项。
如果你要在自己的项目中支持 CSV 格式的话,我对你有如下建议:
- 如果输出内容包含逗号、跨越多行等边界情况,要事先想清楚该如何处理,全体开发团队必须统一处理方法;
- 对于要读取的 CSV 文件,特别是一些比较复杂的内容,请结合规范去理解,不要盲目猜测;
- 尽可能使用成熟、有较好社区支持的 CSV 处理库,不要自己从头编写基础代码;
- 对多团队或跨语言开发,考虑将 CSV 处理封装为单独的库或服务,避免重复开发和兼容性问题;
- 做好异常处理和单元测试。