重写 500 Lines or Less 项目 - 3D 建模器
概述
本文章是 重写 500 Lines or Less 系列的其中一篇,目标是重写 500 Lines or Less 系列的原有项目:A 3D Modeller。
背景
3D Modeller 基于 Python 语言和 OpenGL 实现了可在窗口中查看、编辑和浏览的三维模型场景,有点类似于一个简化版的 3DS Max。对于初次接触三维图形编程的读者来说,主要难点在于它涉及到比较多的空间几何知识和图形变换;在此基础上,需要了解的 OpenGL 接口也具有相当的规模和复杂度。我简单统计了一下,原文仅作者编写的代码已经超过 650 行,这还没有包括其所引用的两个第三方模块————这些模块被作者以源码形式包含在了项目中,而这两个模块加起来也有 500 行左右了。因此可以说,该项目在 500lines 系列中也算是规模和难度比较大的一个了。
要在一篇文章中全面介绍 OpenGL 接口和相关知识,即便仅限于本文涉及的部分范围,也是不可能的。因此,本文着重于讲述程序本身的设计理念与实现过程,对于 OpenGL 接口仅给出了浮光掠影的介绍,希望读者理解。如果对某些函数的具体作用感到困惑,建议在阅读同时参考 OpenGL 文档或书籍,以获得更深入的信息。
本系列文章的大多数项目都是遵循迭代式方法逐步开发完成的:即便对于只有几百行代码的项目,一次完成也不太现实,层层推进、逐步完善对于普通用户来说是更加合理的做法。事实上我自己在首次阅读原作者代码时,对于其中涉及到的大量三维空间数学概念、以及相关的 OpenGL 接口,也有头昏脑胀之感。使用迭代式方法,在每个步骤中引入少量概念,可以减轻读者的认知负担,也能够更清楚地看到一个完整的项目是如何通过重构而不断成型的。
本文代码的实现与原文相比有几个不同之处。首先,原作者设计了一个类似这样的类交互关系:
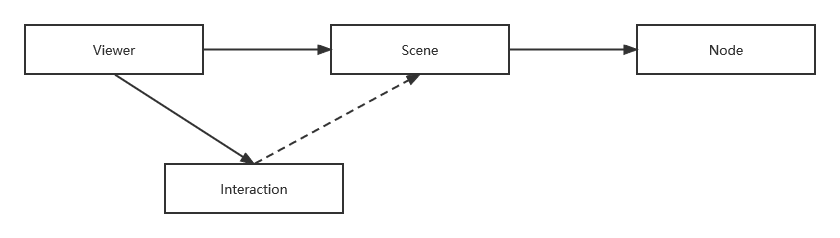
其中 Interaction 主要作用是管理鼠标/键盘的交互逻辑,并通过自行设计并管理数据结构实现了通常称为 Event Listener 设计模式。但在我看来,本项目并不存在多个“侦听者”的要求,因此该设计并未发挥应有的作用,反而多出一个间接层,使得组件之间的交互不那么直观,多少有点过度设计的嫌疑。因此,本文的实现取消了这个中间层,使用更加简单的设计:

原文层在开头部分提到一种图形化程序设计理念,尽管并未文中并未明确给出各个组件的名字,但很显然指的是 MVC 设计模式。客观地说,MVC 模式尽管在概念上不难理解,但它是站在一个较高的概念视角,对于具体到应用层面应如何实现缺乏明确的规定,因此在实践中发展出了各种各样的变体,包括 MVP、MVT、MVVM 等,才能适应各种图形框架自身的实际情况。此外,它与组件化开发的思想其实也存在一定冲突,所以我们会看到以组件化为只要指导思想的现代前端框架基本上都不再强调 MVC。对本文的设计来说,Window(窗口)大体上承担了控制器的角色,它的主要工作之一是处理和协调来自输入鼠标/键盘的输入,并调用Scene(场景)来完成渲染工作。Scene 可以视为同时承担 Model 和 View 的双重角色————由于 OpenGL 图形库接管了实际的渲染过程,View(视图)的概念在很大程度上被弱化了,但我们需要自己做好数据管理的工作。
这里涉及的另外一个组件是各种需要展示的形体(Shape),原文称为 Node,我认为“节点”这个名字并不准确,所以换成图形学中常用的叫法。对于它,我们主要使用了组件化和继承的设计方法,但在具体实现思路上和原文也存在一些差别。这些细节我们留到后面实现的部分再展开来讲。
目标
以上主要着眼于本项目在设计和理论层面的内容。为了让读者对程序有一个更加直观的了解,本环节将具体介绍本项目所希望实现的设计目标,同时对后续将要用到的主要术语加以说明,以便于读者理解。
3D Modeller 是一个三维展示和设计程序。由于计算机屏幕本身是二维的(不考虑 VR),在目前的技术限制下,我们只能将三维空间的内容“投影”到二维平面上。二维平面的主要问题在于它无法直观地表示出“景深”的维度,所以在视觉上需要一些辅助内容来帮助我们进行空间定位,其中主要方法之一就是在三维设计应用中常见的空间网格线(如下图)。为了避免不必要的干扰,本例显示的网格只显示 X-Y 平面,同时标记出三个坐标轴方向。因此示例中把该线称为平面(plane)。
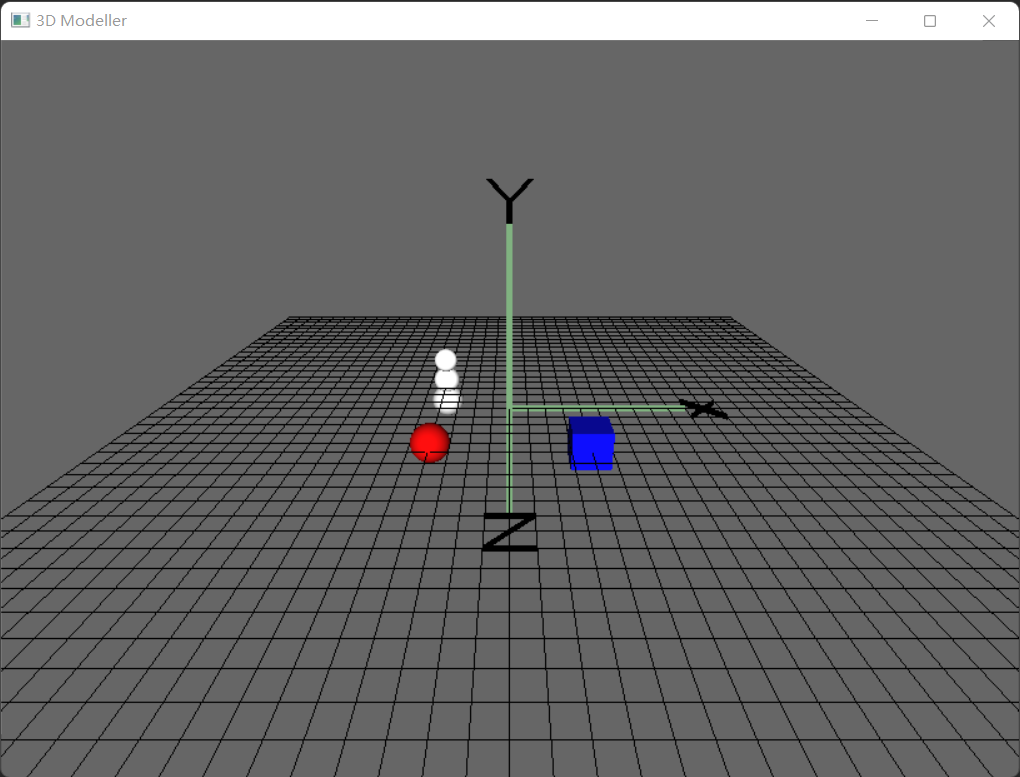
除了网格线之外,我们从图中还能看到一些三维形体,包括各种颜色的方块、圆球等。用户可以控制这些这些形体在空间范围内进行平移、缩放、改变颜色等。此外,整个空间也是可以平移、缩放或选装的,这样我们就可以从不同的角度去观察它们。
作为演示,本例实现的程序支持三种形体:
- 球体(
Sphere) - 方块(
Cube) - 雪球(
Snowball)。它实际上是一个复合形体,由三个小的圆球所构成,同时也是展示关于Composite界面设计模式的一个很好的实例。
对于以上形体,本程序支持下列操作:
- 鼠标左键点击形体进行选择(限于篇幅,程序只支持单选)。后续移动、缩放等操作都是对于选中的形体而言的
- 按住鼠标左键拖动,对选中的形状进行平移
- 按住鼠标中键拖动,对整个场景(也包括其中的形体)进行平移
- 按住鼠标右键拖动,则是以原点为中心对场景进行旋转
- 使用鼠标滚轮,对场景进行整体放大或缩小
同时,程序也支持以下键盘操作:
- 按
s键,在鼠标位置放置一个新的球体 - 按
c键放置一个方块 - 按
b键放置一个雪球 - 按方向键上/下,将选中的形体放大或缩小
- 按方向键左/右,让选中形体的表面颜色在一系列预定义颜色中切换
以上操作对于一个功能完善的 3D 编辑器来说还谈不上特别完整,不过作为一个起点已经非常不错了,在此基础上可以比较容易地添加其他高级功能。比如说,既然已经实现了如何添加形体,那么增加一个按 DEL 键删除形体的功能也不外乎就是反向操作了。限于 500 行代码的要求,我们不可能面面俱到,有兴趣的读者可以在其基础上进一步扩充完善。
源码
本文实现程序位于 代码库 的 modeller 子目录下。按照本系列程序的统一规则,要想直接执行各个已完成的步骤,读者可以在根目录下的 main.py 找到相应的代码位置,取消注释并运行即可。
本程序是基于 Python3 开发地。由于该程序用到 OpenGL 且需要较多数学计算,所以需要安装以下两个包:
PyOpenGLNumPy
我们使用的都是较为基础的功能,不需要太担心版本兼容性的问题,读者如果自己编写程序的话,只要简单地安装最新版即可。当然,如果需要同时维护多个项目的话,建议最好还是用 virtualenv 等工具单独创建一个虚拟环境,相信这个知识对于多数 Python 开发者来说已经是常识,这里不再赘述。要让 OpenGL 程序跑起来,在部分平台上可能还需要一些额外的步骤,具体情况我们留到实现环节再讲解。
实现
现在我们分步骤来实现这个程序。可能很多读者————包括我开始阅读原文时————对 OpenGL 并不是特别熟悉,因此首先从基础做起:让一个 Hello World 级别的程序先跑起来,以确认我们搭建的环境可以正常工作。
步骤 0: OpenGL 的 Hello World
from OpenGL.GL import *
from OpenGL.GLU import *
from OpenGL.GLUT import *
def render_func():
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)
glRotate(0.1, 5, 5, 0)
glutWireTeapot(0.5)
glFlush()
def main():
glutInit()
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGB)
glutInitWindowPosition(0, 0)
glutInitWindowSize(400, 400)
glutCreateWindow(b'OpenGL')
glutDisplayFunc(render_func)
glutIdleFunc(render_func)
glutMainLoop()
程序并不算复杂,至少比 Windows SDK 版本的 Hello World(70行左右) 要简单多了。对于编写过 GUI 程序的同学来说,它的整体结构应该非常眼熟:先进行一些初始化设置,指定一个回调函数,在该函数中完成绘制。不同之处在于该回调函数并不包揽程序中所有事件,而只负责渲染,至于键盘/鼠标输入处理等则由其他接口来完成。我们在这里调用了一个内置的 OpenGL 对象:茶壶(Teapot)的三维线框模型,它的主要任务之一就是确认图形是否可以正常显示,否则自己去定义一个三维模型还是需要很多工作的。
读者也许会注意到,我们在代码开头导入了 OpenGL 库的所有公开接口,且包含 GL/GLU/GLUT 三个子模块。OpenGL 是一个复杂的体系,其中核心规范是平台无关的,但为了能够在各个图形系统上得以运行,它来需要基于底层系统(主要是 X-Window 或 Windows GDI/DirectX)的适配,这些适配工作就是 GLU 和 GLUT 模块的任务。
一般来讲,在 Python 中使用星号导入是不被建议的做法,可能会出现变量混乱和难以定位的错误。如果读者去看原作者的代码,会发现他使用的是明确导入的方法。但 OpenGL 涉及的函数和常量实在太多,仅导入部分就占去了数十行代码,对这个总共也才几百行的程序来说似乎有点过分。另一方面,OpenGL 的接口函数均带有前缀,其实名称冲突的风险是很小的,如果使用模块导入的话,类似 glut.glutInit() 这样的写法也显得比较累赘和怪异。综合考虑后,我还是选择了全部导入,即便出现导入冲突问题的话,在这种规模的程序中也是很容易定位和排除的。当然,在生产级别的大规模应用中还是不建议这样写。
现在你可以试着运行程序。如果能看到转动的茶壶,那太好了,说明运行环境没有问题,你可以略过下面的内容,直接进入第二个步骤。如果有问题的话,请接着往下看。
如果读者是在一台全新的机器上(没有做过 OpenGL 相关开发)运行此程序,那么你有很大概率看到这样一条出错信息:
OpenGL.error.NullFunctionError: Attempt to call an undefined function glutInit, check for bool(glutInit) before calling
这个错误描述比较晦涩,它真正的原因是:我们引用的 PyOpenGL 库只是一个 Python 到 OpenGL/GLUT 的接口转换层,真正的实现是用 C++ 编写的动态库,它并未直接包含在引用的库中。
对于 Linux 用户来说,用系统的包管理工具搜索名称包含 freeglut 的包并安装,一般就可以解决此问题。Windows 用户就比较麻烦了,需要用户自己下载并拷贝 DLL 文件,并且网上相关的中文资料很多语焉不详,甚至含有错误,所以这里详细说明一下:
- 查找
freelut在Windows下的开源实现并下载。该项目的原始地址位于 SF.net,但官网只提供源码下载,Windows预编译版本可以从以下地址获取:点击打开 - 下载得到的是一个 zip 包,根据你的系统是 32 位还是 64 位,分别选择
freeglut\bin\freeglut.dll或者freeglut\bin\x64\freeglut.dll; - 请注意,这是很多网络资料所忽略的一点!直接拷贝
DLL文件是不行的,你还要为它改名,并且具体要改成什么名称还与Python版本有关。我的做法是找到PyOpenGL的导入部分代码,在我的虚拟环境下,它位于venv/lib/site-packages/OpenGL/platform/win32.py,其中导入代码类似这样:
@baseplatform.lazy_property
def GLUT( self ):
for possible in ('freeglut%s.%s'%(size,vc,), 'glut%s.%s'%(size,vc,)):
print('glut possible:', possible) # debug for DLL name
try:
return ctypesloader.loadLibrary(
ctypes.windll, possible, mode = ctypes.RTLD_GLOBAL
)
except WindowsError:
pass
return None
其中包含注释的一行是我添加的,用来检查系统使用的导入名称到底是什么。在我自己的系统上,输入结果是 freeglut64.vc14,因此我们要做的是把 freeglut.dll 改名为 freeglut64.vc14.dll,并拷贝到 venv\Scripts 目录下。如果你是全局安装 PIP 包的话,那么应该把它拷贝到 c:\Windows\System32,或 PATH 环境变量所包含的其他目录下,程序才能找到它。
解决了 OpenGL 的运行环境问题,我们转向下一个环节:重构,并引入自己的三维模型。
步骤 1:添加窗口(Window)和三维模型
在上一步实现的程序是非常简单的,并且带有明显的面向过程风格。我们后面要添加的内容会越来越复杂,最好从现在开始就考虑一下如何划分程序的问题。从代码中可以明显看到部分内容是和 Window 相关的,这里可以作为重构的起点,先把窗口定义部分提取出来,并且把渲染部分作为窗口类的方法:
class GLWindow:
def __init__(self, pos, size, title):
self.init_opengl()
self.create_window(pos, size, title)
def init_opengl(self):
glutInit()
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGB)
def create_window(self, pos, size, title):
glutInitWindowPosition(pos[0], pos[1])
glutInitWindowSize(size[0], size[1])
glutCreateWindow(title.encode())
glutDisplayFunc(self.render)
glutIdleFunc(self.render)
def main_loop(self):
glutMainLoop()
def render(self):
...
然后,主程序就可以简化为:
win = GLWindow((0, 0), (1024, 768), '3D Modeller')
win.main_loop()
这项重构可以说是轻而易举的。但继续显示茶壶似乎没有多大意思,所以我决定开始引入真正要显示的三维模型。老实说,这个步子迈得有点大,引入的新内容会很多,但它们又是渲染过程所不可或缺的,缺了一个显示效果就不正常,干脆还是一起搞定吧。为了减少阅读难度,接下来对其中要使用的重点概念依次进行解释。
定义模型
在 OpenGL 中,3维模型在显示之前必须首先定义,方法是调用 glNewList/glEndList 接口,并给新模型分配一个 id,以后就可以用此 id 进行渲染。大多数模型可以分解为一系列三角形的集合,部分特殊模型————比如后面将会讲到的球体和线条,虽然在技术上也可以做类似的分解,但让用户自己来处理确实不太现实,所以 OpenGL 提供了专门的接口来定义它们。
本程序的主要目标是实现多种可由用户独立修改的形体。这意味着它们需要维护自己在空间中的位置,因此复杂度较高。除此之外,我们在上图中看到的网格平面其实也是一个模型,不过它只起到视觉辅助定位的作用,本身无法被修改,也不需要动态坐标,实现起来相对简单一些。和其他模型相同的是,它也需要首先定义,才能在场景中被渲染。
我们先给本程序中需要用到的模型 id 分配一些常量:
class ObjectId:
plane = 1
sphere = 2
cube = 3
细心的同学也许会注意到在前面我们还提到一种模型雪球(snowball),但这里没有给它分配 id。这是由于雪球是一个复合形体,由三个 sphere 所组成,它本身是不需要 id 的。
定义平面由一个辅助函数实现:
def make_plane():
glNewList(ObjectId.plane, GL_COMPILE)
glBegin(GL_LINES)
glColor3f(0, 0, 0)
glVertex3f(-10.0 + 0.5 * i, 0, -10)
...
glEnd()
glEndList()
实际代码比这里列出的要长得多,但大多是一些点/线的坐标数据,这里不再详细列出。glBegin() 是一个看似简单、实则相当复杂的函数,它规定对后续定义的数据应如何解读,这里使用了 GL_LINES 表示后面每两个端点组成一条线段。至于其他可能的值请参考 OpenGL 文档。
模型定义之后,要显示它就很简单了,只要调用以下代码:
glCallList(ObjectId.plane)
对于目前的模型来说这句代码就够了。但对于可交互的对象来说,它可能显示在场景中的不同位置,那么如何指定它的显示位置呢?下面来讨论关于坐标的问题。
本地坐标与场景坐标
在上面定义模型的代码中,我们指定了一些坐标点的位置。模型的设计者通常会在模型中选择一个自己选择的位置作为坐标原点,对原点的选择并没有什么绝对的原则,只是出于习惯和便利性的考虑。比如说,对于球体或正方体这样的规则图形,把它们的几何中心作为原点是非常普遍的,但也有人把正方体的某个角点单座原点。模型中其他顶点的位置都是相对于原点而言的,和模型在场景中的具体位置无关,所以这种坐标可以称之为“本地坐标”。
一旦形体被放入场景,那么移动该形体就意味着组成形体的所有顶点坐标都发生了变化。很显然,让开发者自己去跟踪并计算这些坐标位置的变化是很不人道的。而有一些空间几何基础的同学应该知道,任何空间变化,包括平移/缩放/旋转,都可以表达为矩阵之间的乘法计算。因此 OpenGL 给我们提供了一种机制,让我们在渲染某个对象之前用矩阵指定其空间位置,然后再复原坐标(以便继续渲染下一个物体)。为此,我们要编写类似这样的代码:
glPushMatrix()
glMultMatrixf(transform_matrix)
glCallList(object_id)
glPopMatrix()
更有趣的是, glPushMatrix/glPopMatrix 是可以嵌套调用的。这给我们提供了很大的便利,因为形体既要自身可以移动,同时也要跟随场景的变换而移动,如果场景的变化需要同时修改形体就太麻烦了。通过嵌套调用,我们可以让场景和形体分别只关注自身的变换即可,不需要进行整体的重新计算。
光照与透视
光照就是在场景中点亮一盏“灯”,否则物体将无法被看见,此外“灯”的位置以及照射方式(直射或散射)对于物体呈现的外观也有很大影响。至于透视则是绘画及摄影的基本知识了。虽然在 OpenGL 中关于这两点有不少内容可以讲,但是要展开的话恐怕太长,且和程序结构没有直接关系,这里就暂且忽略了。大家去看代码的话,从函数名应该可以直观地猜出哪些函数是完成这些工作的。之所以要在这里提一下,是因为程序必须正确在场景中设置它们,要渲染的内容才能够正常显示。
轨迹球(Trackball)
所谓轨迹球(Trackball)是这样一个概念:假想我们要控制的场景被包裹在一个透明的圆形球体中,类似于一个地球仪,作为来自外部的观察者,只要轻轻拨动球体,就可以从各种角度观察模型的外观。这种假想的球体就是 Trackball。
严格来说,处理 Trackball 应该是后续步骤的任务,目前渲染工作还未涉及到交互问题。之所以要在这里引入它,是因为要让网格平面呈现一个比较舒服的观察角度,需要把视角放在一个略微倾斜的位置,这就需要一个指定一个矩阵。手工计算该矩阵也是可行的,但 Trackball 正好擅长处理球体坐标,直接委托给它可以省去不少工作。引入 Trackball 之后,显示平面的代码变成类似这样:
self.trackball = Trackball(theta=-25, distance=15)
...
tb_mat = self.trackball.matrix
glMultMatrixf(tb_mat)
glCallList(ObjectId.plane)
只要给 Trackball 指定位置参数,具体的位置计算交给它就好。我们在这里引用的是一个来自第三方的开源实现,作为一个单独的模块,并不计算在 500 行代码之内。有兴趣的读者也可以自己阅读其代码,位于项目的 common/trackball.py 文件。
到此,我们定义了坐标平面(plane)的三维模型,并把它渲染到界面上。现在运行该程序,应该看到类似下面的画面:
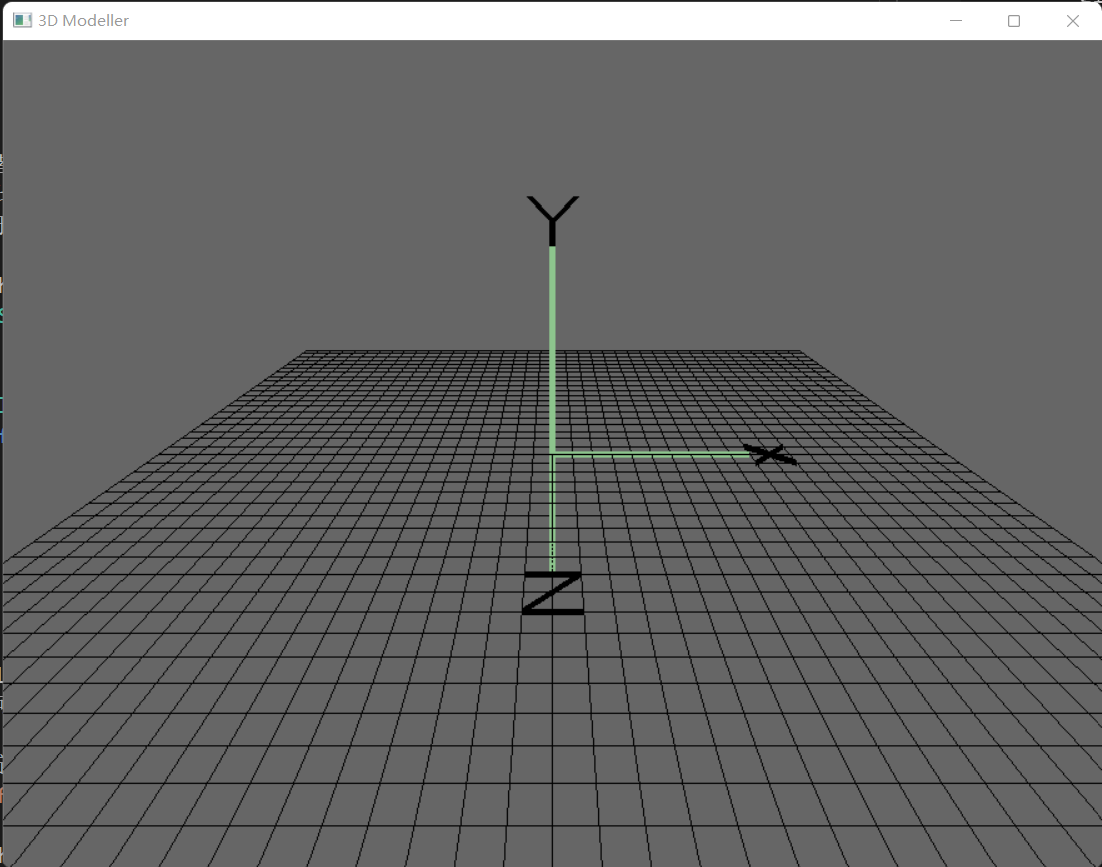
接下来,我们准备添加其他可交互的形体。
步骤 2:定义交互形体
如果你去看原作者的实现,会发现他是用一个类继承结构去实现各种可交互的形体,而平面(plane)则是由 Scene 单独处理的,这个类层次结构大致如下:
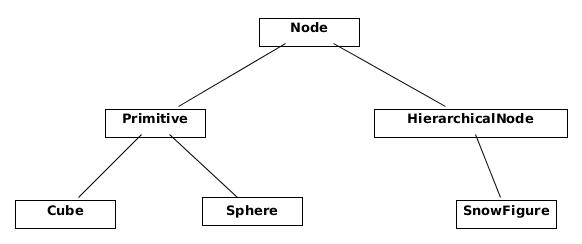
我在阅读代码后发现:Plane 和基础形体(也即是上图中的 Primitive)有相通之处,就是它们都需要用 glNewList() 来定义,并且渲染也都是调用 glCallList(),区别在于 Plane 随场景而移动,并不支持自身的独立变换。我的希望是把所有形体统一管理起来,相同的逻辑应该能够复用,最好也不要出现“特例特办”的情况。初看起来,只要把上述类层次多加一个层级,且把 plane 添加到其中某个分支就行了。但实际上这是有问题的,我们现在要处理的主要有以下三种形体,从特性角度看,它们又存在重叠:
| 类 | 是否需要定义 | 允许用户交互 |
|---|---|---|
| plane | 是 | 否 |
| primitive | 是 | 是 |
| hierarchical | 否 | 是 |
这里的难题在于,根据“是否定义”或者“是否可交互”两种标准,我们会得到两个不同的继承体系,但它们之间又存在重叠,如果使用单根继承的话,则不同的子类之间又很难重用代码。这种两难的抉择在复杂的继承体系中是一个比较棘手的问题。
为了解决此困境,我希望利用 Python 中类似多继承的语言机制以突破单继承的限制。在很多框架中,多继承是以 Mixin 的形态出现的。对于本程序而言,我决定将交互逻辑提取到一个名为 ActiveMixin 的类中:
class Shape: pass
class Plane(Shape): pass
class ActiveMixin: pass
class Primitive(Shape, ActiveMixin): pass
class Cube(Primitivie): pass
class Sphere(Primitive): pass
这样,就形成了下图所示的类继承体系:
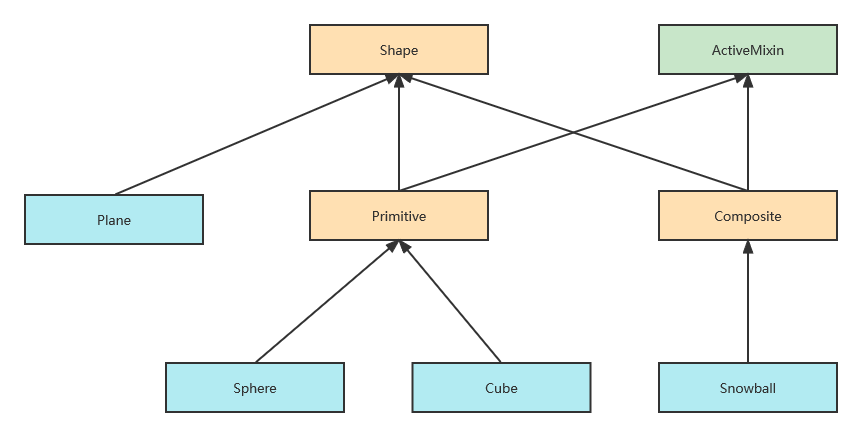
注意在该示意图中,箭头代表继承。途中抽象类、具体类以及 Mixin 用不同的颜色标记,以示区分。我不喜欢原文中用 Node 称呼形体,所以改成了 Shape。此外,图形化组件的组合是一种常见的设计模式,通行的名称是 Composite,所以我也用它替代了原文使用的 HierarchicalNode。如果读者希望对照原文阅读的话,请注意它们之间的对应关系。
ActiveMixin 用于支持可交互形体,也是我们这个步骤的重点。因为形体主要支持平移/缩放两种变换,所以我们添加成员变量以记录之:
class ActiveMixin:
def __init__(self):
self.translation = np.identity(4)
self.scaling = np.identity(4)
def translate(self, x, y, z):
self.translation = np.dot(self.translation, translation([x, y, z]))
def render(self):
glPushMatrix()
glMultMatrixf(np.transpose(self.translation))
glMultMatrixf(self.scaling)
self.render_self()
glPopMatrix()
可交互形体负责自身的渲染(通过 render() 方法),并在渲染前先设置好位置图形。我们后面会讲到,Primitive 和 Composite 渲染实现会有所不同,所以我们把具体工作委托给子类的 render_self() 抽象方法,而相通的位置变换逻辑由 Mixin 来完成。
对于单一实体(Primitive)而言,我们给它增加一个颜色属性,允许在预定义的颜色列表中选择,也可以不指定,这时分配给它一个随机的颜色。实际的渲染需要指定颜色,然后调用 glCallList():
class Primitive(Shape, ActiveMixin):
def __init__(self, color_index=-1):
super().__init__()
if color_index >= 0:
self.color_index = color_index
else:
self.color_index = self.random_color_index()
def render_self(self):
color = self.COLORS[self.color_index]
glColor3f(color[0], color[1], color[2])
glCallList(self.id)
我们说过,定义形体需要给它分配一个 id。由于每种形体只需要定义一次,不能通过实例方法来处理,所以我们规定:需要定义的形体(包括 Primitive 和 Plane)需要有一个 id 属性,以及一个名为 define() 的静态方法。比如说,Sphere 类的代码如下:
class Sphere(Primitive):
id = 2
@classmethod
def define(cls):
glNewList(cls.id, GL_COMPILE)
quad = gluNewQuadric()
gluSphere(quad, 0.5, 30, 30)
gluDeleteQuadric(quad)
glEndList()
在上一步我们已经实现了 Plane,不过是在单独的函数 make_plane() 中定义的。现在可以参考 Sphere 把它的实现移动到类中,这样代码也会更加 OO 一些。
此外,在上个步骤我们是直接调用 make_plane() 以注册形体。在建立类体系之后, 我们可以编写一个通用的辅助方法来完成同样的工作。它的逻辑是遍历该模块中所有 Shape 子类,如果发现其定义了 define() 方法,就假定这是形状定义,并调用之。这样要比硬编码所有形状要略微复杂一些,不过好处在于:如果以后再在此单元中添加新的形体,注册代码不需要任何修改:
def define_shapes():
for cls_name, cls in globals().items():
if isinstance(cls, type) and issubclass(cls, Shape):
method = getattr(cls, 'define', None)
if method is not None:
method()
既然有了多个形体,如何管理它们也是一个值得考虑的问题。我们可以把所有形状添加到一个简单的列表中,但以后还会需要更多处理,所以现在是引入场景(Scene)的合适时机:
class Scene:
def __init__(self):
self.shapes = [Plane()]
def add_samle_shapes(self):
cube = Cube(color_index=1)
cube.translate(2, 0, 2)
self.shapes.append(cube)
sphere = Sphere(color_index=3)
sphere.translate(-2, 0, 2)
self.shapes.append(sphere)
场景刚开始只包含辅助平面,但我们也增加了一个方法,来添加一些作为演示的形体。场景也应该负责自己的渲染,所以我们可以把 Window.render() 中原有的实现搬移过来,再略作修改:
def get_shapes(self, active):
return [x for x in self.shapes if x.is_active() == active]
def render(self):
...
glDisable(GL_LIGHTING)
for shape in self.get_shapes(False):
shape.render()
glEnable(GL_LIGHTING)
for shape in self.get_shapes(True):
shape.render()
...
我们希望把所有形状统一管理,但可交互形体和平面还是略有不同:前者需要考虑光照,特别是它在选中或未选中的外观上应该稍有区别,而后者则没有这个问题。为此,我们给基类 Shape 添加了一个用于区分的辅助方法,并在场景中分别渲染:
class Shape:
def is_active(self):
return isinstance(self, ActiveMixin)
class Scene:
def get_shapes(self, active):
return [x for x in self.shapes if x.is_active() == active]
完成以上工作后,我们还需要在 Window 中初始化场景,而 render() 方法现在可以委托给它:
class GLWindow:
def __init__(self, pos, size, title):
...
self.scene = Scene()
self.scene.add_samle_shapes()
def render(self):
self.scene.render()
现在运行程序,你应当会看到场景中出现了作为演示的方块和圆球。下面的步骤我们再接再厉,实现复合形体:雪球(Snowball)。
步骤 3:定义复合形体
从技术上讲,复合形体就是多个单一形体的组合,在对形体进行变换时,它的各个组成部分作为一个整体统一发生变换。本程序只实现了一种复合形体:雪球(Snowball),它是由三个 Sphere 组成的,默认显示为白色,不过三个球体在本地坐标中的位置和缩放比例有所不同。只要理解 Snowball 是如何实现的,再实现其他复合形体也都是同样的道理。我把复合形体的实现类命名为 CompositeShape。它的渲染逻辑也很简单,依次渲染每个子形体即可:
class CompositeShape(Shape, ActiveMixin):
def __init__(self):
super().__init__()
self.children = []
def render_self(self):
for child in self.children:
child.render()
由于基类基本上完成了所有工作,子类只需要关注定义形体的定义即可:
class Snowball(CompositeShape):
def __init__(self):
super().__init__()
self.add_sphere((0, -0.6, 0))
self.add_sphere((0, 0.1, 0), (0.8, 0.8, 0.8))
self.add_sphere((0, 0.75, 0), (0.7, 0.7, 0.7))
add_sphere(translation, scale) 方法用于添加一个位置和缩放比例略有变化的球体。它的实现很直观,为节约篇幅,这里就不再列出了。为了看到效果,我们在 add_sample_shapes() 方法中添加一个雪球:
def add_samle_shapes(self):
...
snowball = Snowball()
snowball.translate(-2, 0, -2)
self.shapes.append(snowball)
运行程序。如果一切正常的话,你应该看见类似雪球出现在屏幕上。
现在,我们的所有形体已经定义完毕,接下来进入另一个重要阶段:为场景以及形体添加交互行为的支持。
步骤 4:基础性输入支持
在前面曾说过,OpenGL 程序和普通 GUI 程序在结构上非常类似,都需要回调函数作为主要的实现机制。不同之处在于典型的 GUI 程序的回调函数需要处理几乎所有事件,而 OpenGL 则区分地更加细致:glDisplayFunc() 指定地的回调函数只处理渲染。对于来自鼠标/键盘等的输入则需要另外的接口,并且这些回调函数带有额外的参数,以记录鼠标位置或按下的按键等信息。
我们现在有两个主要的类:窗口(Window)和场景(Scene)。Scene 负责管理形体以及渲染,它的工作已经很繁重了,而 Window 则简单得多,由它来承担输入任务是比较合理的:
class GLWindow:
def create_window(self, pos, size, title):
...
glutDisplayFunc(self.render)
glutIdleFunc(self.render)
glutMouseFunc(self.handle_mouse_button)
glutMotionFunc(self.handle_mouse_move)
glutKeyboardFunc(self.handle_keystroke)
glutSpecialFunc(self.handle_keystroke)
def normalize_pos(self, x, y):
width, height = glutGet(GLUT_WINDOW_WIDTH), glutGet(GLUT_WINDOW_HEIGHT)
return x, height - y
def handle_mouse_button(self, btn, mode, x, y):
print('mouse button:', btn, mode, x, y)
def handle_mouse_move(self, x, y):
print('mouse move:', x, y)
def handle_keystroke(self, key, x, y):
print('key stroke:', key, x, y)
现在运行程序的话,会意识几个有趣的问题。对于 OpenGL 来说,鼠标移动(mouse_move)事件只有在某个按键按下时才会触发。glutSpecialFunc() 这个函数名字有点含糊,这是因为 OpenGL 对输入的划分非常细致,普通字母/数字键以及特殊功能键会当作不同事件来触发,但它们的接口是完全相同的,只是对应的 key 参数不同。在应用层面通常还是统一处理按键为好。
读者应该还会注意到上面的 normalize_pos 函数。对于鼠标来说,OpenGL 坐标采用的是通用的显示器坐标系:X 轴向右为正,Y 轴向下为正。但三维显示程序一般以 Y 轴向上为正,因此我们设计了该函数来做一个转换。
注册事件处理方法之后,我们可以添加一些交互逻辑。对于形体来说,要操作它首先必须要选择它,这就涉及到如何对形体进行点击命中的测试,也是一个有待解决的问题,我们留到下个步骤实现。本步骤先实现一些对场景整体的操作。为此,首先添加两个变量,用来记录哪个鼠标按键被按下,以及移动过程中的坐标位置:
class GLWindow:
def __init__(self, pos, size, title):
...
self.mouse_btn = None
self.mouse_pos = None
如果用户使用鼠标滚轮的话,我们将场景沿着 Z 轴移动。此外,代码还记录了当前鼠标按键和位置,这些信息会在以后移动形体时排上用场:
def handle_mouse_button(self, btn, mode, x, y):
# print('mouse button:', btn, mode, x, y)
self.mouse_pos = self.normalize_pos(x, y)
if mode == GLUT_DOWN:
self.mouse_btn = btn
if btn == 3: # scroll up
self.scene.translate(0, 0, 1.0)
elif btn == 4: # scroll down
self.scene.translate(0, 0, -1.0)
else: # mouse button up
self.mouse_btn = None
glutPostRedisplay()
注意代码最后调用了 glutPostRedisplay(),这表明显示内容发生了改变,通知 OpenGL 在合适的时机重绘界面。
对于鼠标移动,我们规定:用鼠标右键拖动是旋转场景;鼠标中键则是平移场景。至于左键,我们保留给场景中形体的拖动使用。
def handle_mouse_move(self, x, y):
# print('mouse move:', x, y)
curr_pos = self.normalize_pos(x, y)
changed = False
if self.mouse_btn is not None:
dx = curr_pos[0] - self.mouse_pos[0]
dy = curr_pos[1] - self.mouse_pos[1]
if self.mouse_btn == GLUT_RIGHT_BUTTON:
self.scene.drag(curr_pos, (dx, dy))
elif self.mouse_btn == GLUT_MIDDLE_BUTTON:
self.scene.translate(dx / 60.0, dy / 60.0, 0)
changed = True
self.mouse_pos = curr_pos
if changed:
glutPostRedisplay()
读者应该还记得,我们曾经为场景添加了 Trackball,它承担了拖拽旋转场景的大部分复杂计算,我们直接调用即可:
class Scene:
def drag(self, pos, delta):
self.trackball.drag_to(pos[0], pos[1], delta[0], delta[1])
原作者对于输入处理的实现是通过一个单独的 Interaction 对象来处理的,并且使用事件触发机制来进行响应。这种设计如果用于框架是合理的,但对于应用程序来说则显得中间步骤太多,并不直观,也没有带来明显的好处。因此我选择了直接让窗口处理输入,再把渲染任务委托给 Scene,这样类的交互看上去更简单一些。
步骤 5:输入 AABB
在上个步骤我们实现了对场景的输入处理。不仅场景自身可以移动,场景中的各个形体也是可以独立移动或缩放的,但为了处理形体,我们必须首先选择它。
测试三维空间中的形体是否被鼠标点击“击中”,特别是对于不规则物体来说并不是那么简单,如果想要足够精确往往需要复杂的边缘检测算法,而这种复杂计算又会对性能造成负面影响。特别是对于画面频繁变化的程序(比如游戏),要获得足够的响应性,我们往往需要在准确性和性能之间进行权衡。
AABB 是一种常见且简单的三维空间命中检测算法。它的基本思想是在目标形体设定一个最小的外接立方体,从鼠标点击位置发出一条假想的射线,只要射线击中了立方体,就认为点击命中。由于立方体的几何形状简单且规则,这种计算是非常高效的,对于比较规则的形体来说效果一般也很不错。当然,如果外接立方体与实际形体的差别很大,那么它的误差就会比较明显。所幸我们这里定义的都是非常规则的形体,因此采用 AABB 算法是合理的。对于复杂且要求较高的应用来说,可以探索其他更加复杂的命中算法。
为此,我们再引入一个开源的 AABB 实现,位置在项目的 common/aabb.py 模块中。因为只有可交互的动形体才需要命中检测,我们把它添加到 ActiveMixin 中:
class ActiveMixin:
def __init__(self):
...
self.aabb = self.define_aabb()
def pick(self, start, direction, mat):
newmat = np.dot(np.dot(mat, self.translation), np.linalg.inv(self.scaling))
results = self.aabb.ray_hit(start, direction, newmat)
return results
每种形体的外接矩形不同,所以我们让 define_aabb() 方法留给子类来完成。AABB.ray_hit() 方法返回的是一个元组 (hit, distance),其中两个元素分别代表是否命中,以及命中位置距离射线起点的距离。
现在,我们再为场景添加点击选中算法:
def pick(self, pos):
start, direction = self.get_ray(pos)
nearest_shape, nearest_distance = None, 2147483647 # sys.maxint
for shape in self.get_shapes(True):
hit, distance = shape.pick(start, direction, self.modelView)
if hit and distance < nearest_distance:
nearest_distance, nearest_shape = distance, shape
for child in self.get_shapes(True):
child.selected = (child is nearest_shape)
self.selected_shape = nearest_shape
以上代码有点复杂。它首先调用 get_ray() 从鼠标点击位置生成一条假想的射线,在该射线命中的所有形状中选择距离最近的那个,作为选中的形体。原文代码可能是用 Python 早期版本实现的,引用了 sys.maxint 当作最远的可能距离,但目前的 Python 已经不再支持该常量,所以我直接把具体数值写在这里。此问题也是在尝试运行原文代码的时候发现的。
这里还有一点设计上的问题需要说明。上述代码为场景添加了一个 selected_shape 成员来记录选中的形体,同时每个形体又有 selected 成员来记录它是否被选中。从设计思想来说,这是一种冗余,是应该避免的,否则可能引发数据不同步的潜在风险。那为什么还要保留它呢?因为选中的形状在渲染时在外观上要有所区别,它们需要知道自己是否被选中了;而场景在处理移动时也需要知道哪个形体是被选中的。如果修改代码来避免冗余也是可行的,但改动较大;而本程序选中形体的部分只有这一处,代码不同步的风险很小,即使有也很容易查找。权衡之下,我还是保留了这个做法。但如果在程序中有多处位置可以选择形体的话,那么最好还是提取公共方法,以避免可能的问题。
实现选择之后,我们可以继续完善窗口类中的选择逻辑:
def handle_mouse_button(self, btn, mode, x, y):
...
if mode == GLUT_DOWN:
...
if btn == GLUT_LEFT_BUTTON:
self.scene.pick(self.mouse_pos)
以及,允许用户左键拖动形体:
def handle_mouse_move(self, x, y):
...
if self.mouse_btn is not None:
if self.mouse_btn == GLUT_LEFT_BUTTON:
self.scene.move(curr_pos)
Scene.move() 涉及到一些三维空间位置的计算,实现较为复杂,但逻辑是直观的。这里不再列出,有兴趣的同学可以阅读源码。
为了直观地知道哪个形体被选中,我们还需要对形体稍作修改,让它在被选中时呈现略微“高亮”的效果:
class ActiveMixin:
def render(self):
...
if self.selected: # emit light if the node is selected
glMaterialfv(GL_FRONT, GL_EMISSION, [0.3, 0.3, 0.3])
self.render_self()
if self.selected:
glMaterialfv(GL_FRONT, GL_EMISSION, [0.0, 0.0, 0.0])
现在运行程序,我们可以点击选择某个实体,并且将它在场景中任意移动。
步骤 6:输入其他
以上实现尚未涉及到的是键盘输入的支持。对于键盘操作,我们规定:
- 按
s/c/b键分别表示在当前位置增加一个球体/正方体/雪球; - 键盘上下方向键对选中物体进行放大/缩小;
- 键盘左右键切换选中物体的颜色
为此,修改键盘处理函数:
def handle_keystroke(self, key, x, y):
# print('key stroke:', key, x, y)
curr_pos = self.normalize_pos(x, y)
changed = True
if key == b's':
self.scene.place('sphere', curr_pos)
elif key == b'c':
self.scene.place('cube', curr_pos)
elif key == b'b':
self.scene.place('snowball', curr_pos)
elif key == 0x65: # GLUT_KEY_UP
self.scene.scale_selected(True)
elif key == 0x67: # GLUT_KEY_DOWN
self.scene.scale_selected(False)
elif key == 0x64: # GLUT_KEY_LEFT
self.scene.rotate_color(True)
elif key == 0x66: # GLUT_KEY_RIGHT
self.scene.rotate_color(False)
else:
changed = False
if changed:
glutPostRedisplay()
以上代码调用了 Scene.place(name, pos),它根据 name 参数创建一个新的形体,并添加到当前场景中。复杂之处仍然在于三维坐标空间的计算:
def place(self, type_name, pos):
start, direction = self.get_ray(pos)
new_shape = None
if type_name == 'sphere':
new_shape = Sphere()
elif type_name == 'cube':
new_shape = Cube()
elif type_name == 'snowball':
new_shape = Snowball()
if new_shape is not None:
translation = (start + direction * self.PLACE_DEPTH)
pre_tran = np.array([translation[0], translation[1], translation[2], 1])
translation = self.inverseModelView.dot(pre_tran)
new_shape.translate(translation[0], translation[1], translation[2])
self.shapes.append(new_shape)
Shape 基类已经预定了一个可用的颜色列表。要切换颜色,我们添加一个辅助函数:
def rotate_color(self, forward):
color_count = len(self.COLORS)
if forward:
self.color_index = (self.color_index + 1) % color_count
else:
self.color_index = (self.color_index + color_count - 1) % color_count
到此,程序所有功能都已实现。我们可以按照前述规则按下键盘,观察屏幕的变化。
总结
在本程序中,我们实现了一个比较基础、但已初具规模的三维建模程序,基于 OpenGL 实现场景的展示,建立一个可以统一管理多种形状、在运行时动态添加内容的数据结构,并接受来自鼠标或键盘的输入以修改模型内容。如果读者对 AutoCAD 或者 Blender 这样的大型设计应用、或者游戏的场景编辑器等该兴趣的话,那么本示例应该可以作为一个很好的起点。
读者想要更进一步完善该应用的话,有一些明显的方向,比如说:按 DELETE 以删除选中的形状;通过类似 Undo/Redo 的操作给用户一个“后悔药”;从文件中保存和加载模型;增加一个“工具箱”以便用户更直观地选择模型,等等。
如果读者希望看到更加现实的三维建模程序,也有一些开源项目可供参考,比如 Blender 或 FreeSCAD 等等。当然,它们的规模更加庞大和复杂,并且通常是用 C++ 编写的,不论是学习还是修改的难度都比较高。无限风光在险峰,勇于挑战且对这个方向感兴趣的同学不妨尝试一下。
文章索引
- 重写 500 Lines or Less 项目 - 前言
- 重写 500 Lines or Less 项目 - Web Server
- 重写 500 Lines or Less 项目 - Template Engine
- 重写 500 Lines or Less 项目 - Continuous Integration
- 重写 500 Lines or Less 项目 - A Simple Object Model
- 重写 500 Lines or Less 项目 - A Python Interpreter Written in Python
- 重写 500 Lines or Less 项目 - Contingent
- 重写 500 Lines or Less 项目 - DBDB
- 重写 500 Lines or Less 项目 - FlowShop
- 重写 500 Lines or Less 项目 - Dagoba
- 重写 500 Lines or Less 项目 - 3D 建模器