重写 500 Lines or Less 项目 - Template Engine
概述
本文章是 重写 500 Lines or Less 系列的其中一篇,目标是重写 500 Lines or Less 系列的原有项目:模板引擎(A Template Engine)。本文借鉴了原程序的实现思路,但文章和代码都是从头编写的。相对于原文而言,本次重写在以下方面做出了比较重大的修改:
- Python 版本
原文示例代码基于 Python3,并且只使用了核心的语言特性,因此几乎在任何 PY3 版本均可运行。鉴于本文的写作时间是 2020 年,因此大胆使用了更加激进的策略,使用了部分较新的语法特性,比如 f-string、类型标注等。因此运行本文的实现代码需要 Python3.6 以上版本。相信这个要求对于今天的大多数用户和系统平台来说已经不成问题。
- 模板系统
原文主要参考了 Django 模板(DTL)的语法规则。DTL 对于非程序员来说可能会更为简单和友好一些,但同时也意味着它并不符合 Python 程序员的常规思路,功能也略显薄弱。本文则主要参考 Jinja2 也就是 Flask 内置的模板引擎的语法。虽然它和 DTL 比起来要复杂一些,但 Python 社区广泛认为它更富有表现力和灵活性、在性能上也更好一些。不过,本文所实现到的范围基本和原文一致(当然在具体语法方面是有所不同的)。
- 单元测试
原文附带了大量单元测试(甚至超过了功能代码的数量)。这是可以理解的:一方面,因为生成代码的过程很容易出错,为了保证健壮性,需要处理许多边际情况;另一方面,模板引擎需要处理的对象是纯粹的文本,不需要考虑复杂的外部环境及 Mock 等问题,因此它也是拿来作单元测试很好的对象。
本文则在原文的基础上再进一步:不仅用单元测试在事后保证质量,而且采用测试驱动(TDD)的方式,先编写测试,再实现功能。在开发过程中会看到,TDD 方式会对程序的演进方向带来深远的影响。因此,虽然本文和原文的基本原理是类似的,但最终的实现将大相径庭。有兴趣的同学也不妨把两篇文章对比阅读,相信会有更大的收获。
- 性能优化
原文在设计代码方案的同时已经考虑到性能问题,并在实现时直接采用了作者认为更加高效的方式。但我和原作者的意见有所不同;既然本文用 TDD 的方式编写,那么我们也尊重 KISS(Keep It Simple Stupid) 原则,先抛开对性能问题的关注,而先聚焦于实现基本功能。本文最后会有专门的部分来分析关于性能相关的问题。
- 结构调整
原文主要分成两部分:首先讲述基本原理,然后分析实现代码。而本文则采取迭代式的策略,逐步完成整个程序,每一步都对将要实现的功能和代码进行讲解。笔者相信这样的写法有利于读者循序渐进地理解整个过程,也更加符合项目开发的现实。
文章结构
本文的目标是采用和原文相同的约束条件,即在 500 行代码的限制下,实现一个覆盖大部分主要功能、且具有现实意义的模板引擎。(由于测试代码较多,最后的总代码行数会略微超过 500 行)。全文总体顺序如下:
- 基本接口 以输出最基本的常规文本为目标,实现模板引擎的调用接口;
- 表达式 在基础结构上进行扩展,支持插入表达式的代码块;
- 过滤器 进一步扩展表达式支持,支持类似
Jinja2的过滤器机制; - 注释 添加对于注释块的支持;
- For 代码块 从这里开始我们要支持更为复杂的代码块,因此程序会变得更为复杂。该步骤先从结构相对固定的 For 循环开始实现;
- If 代码块 在实现对代码块的支持基础上,更进一步实现更加复杂的 If 语句;
- 性能考虑 最后,我们通过实测代码性能来评估可能的优化方案,并且和原文的做法进行对比说明。
示例代码
本文及系列文章的所有代码都开源在 Github 仓库:500lines-rewrite。本文相关的代码位于 template_engine 目录,在其下为每个阶段创建了单独的子目录。为了避免为每个步骤创建单独的环境,读者可以将主目录下的 main.py 作为入口,找到对应步骤的代码,并取消前面的注释,即可运行程序。
需求与实现原理
首先还是花点时间来理解我们需要解决的问题。
在 Web 发展的上古时期(实际上也就 20 年左右),为了让 Web 服务器具有实际处理能力而不仅仅是产生静态的文档,主要需求之一就是能够生成动态的响应结果。要达到这个目的,通常要使用 CGI 或 Servlet 之类的机制,而程序员往往要编写大量类似这样的代码:
print('<html></head>')
print('<title>' + page_title + '</title>')
print('</head>')
...
print('</html>')
人们很快就意识到这种代码写起来麻烦、难以维护且容易出错,需要找到更好的途径。以上代码也反映了动态输出的主要特征:以固定的文档结构为主,混杂一些需要动态执行的代码逻辑或表达式。为了支持这种要求,模板应运而生。包括 ASP、JSP、PHP 等各种不同的语言实现在内,几乎所有 Web 框架都实现了自己的模板机制。
本文实现的模板引擎主要参考 Flask 框架内置的 Jinja2 语法规则,它的语法对 Python 程序员来说相当亲切。一个典型的模板类似这样:
<html>
<head>
<title>{{ page_title }}</title>
</head>
<body>
{% if user %}
Hello {{ user.name }}!
{% else %}
Hello Guest!
{% endif %}
</body>
</html>
近几年,基于虚拟 DOM 的前端框架逐渐成为主流,对于模板的要求有所削弱,不过它在动态化要求不高、需要对 SEO 友好的 Web 应用中仍然占有一席之地。此外,模板在其他领域——比如处理电子邮件及代码生成等方面——仍然是非常重要的技术。
模板的实现类似于简单的编程语言,也有解释执行和编译执行两种主要思路。出于性能和尽早发现错误的考虑,今天的模板引擎通常都采用编译执行的思路。在该思路下,模板的执行通常分为两个阶段:解析阶段和生成阶段。
- 解析阶段:程序分析模板的文本内容,并生成处理过的、有利于快速执行的内部结构
- 执行阶段:调用者传入具体的上下文数据,由模板控制执行并生成最终结果。
对于像 Python 这样的动态语言来说,将模板转换为内部代码是相当简单的,因为标准库通过 exec() 等接口已经提供了直接支持。一个基本的代码示例如下:
code = "print('Hello' + name)"
ctx = {"name": "user"}
code = compile(code, '', 'exec')
exec(code, None, ctx)
以上代码会输出 Hello, user!。在最简单的情形下,直接把文本形式的源码传递给 exec() 也是可行的,但模板通常都需要执行多次,为了避免反复解析的浪费,最好还是预先调用 compile() 将其编译为 Python 内部的字节码格式。
现在我们明白了实现原理,接下来考虑如何编码。
基本接口
测试驱动(TDD)要求我们在编写产品代码之前,首先为这些尚未存在的代码写出测试。这是一种“反常规”的做法,但它有助于帮助我们从使用者的角度思考代码的外部接口。
对于模板引擎而言,它至少需要两个参数:
- 模板的文本内容
- 注入模板的上下文数据
前面我们说过,模板的执行分为两个步骤,而上述参数正好是两个步骤分别需要的。因此,我们把模板引擎的接口设计为:模板内容在构造时传入,而上下文数据则在执行阶段传入。我们首先从最基本的场景开始实现,即:对于不包含逻辑代码的模板,输出应该直接返回原始内容。
class TemplateTest(unittest.TestCase):
def test_plain_text(self):
for text in [
'This is a simple message.',
'<h1>This is a html message.</h1>',
'This is a multi line message\nThis is line 2 of the message',
]:
ctx = {}
rendered = Template(text).render(ctx)
self.assertEqual(text, rendered)
尽管我们很清楚当前的实现会非常简单,但测试标准仍然按照严格的产品标准,多检验几种不同格式的文本,以确保各种边际条件都会覆盖到。
满足以上测试的代码再简单不过:
class Template:
def __init__(self, text: str):
self._text = text
def render(self, ctx: dict) -> str:
return self._text
上下文数据在模板中是按照名字访问的,所以把它作为字典来处理。
现在我们有了一个非常基础、但是可以工作的实现。目前的工作似乎过于简单,相信有些同学会迫不及待地希望加快速度,增加更多的代码。但我们还是遵循基本的 TDD 规则,走完一个红-绿-重构的完整步骤。聪明的同学会想到,后面还会陆续添加更多类似的测试,它们只是参数不同,逻辑是完全一样的。因此我们可以把渲染模板的逻辑提取出来,以简化后续的代码:
class TemplateTest(unittest.TestCase):
def render(self, text: str, ctx: dict, expected: str):
rendered = Template(text).render(ctx)
self.assertEqual(expected, rendered)
def test_plain_text(self):
for text in [
'This is a simple message.',
'<h1>This is a html message.</h1>',
'This is a multi line message\nThis is line 2 of the message',
]:
self.render(text, {}, text)
表达式
接下来考虑如何实现在模板中插入表达式。按照 TDD 的方式,我们应该有一个类似这样的测试:
self.render("Hello, {{name}}!",
{"name": "user"},
"Hello, user!")
然而,稍稍思考一下如何实现,我们会意识到这无法用平铺直叙的代码来实现,而是需要分成更小的步骤:
- 将模板解析成小的、有特定语法规则的标记(在编译术语中通常称为
Token) - 根据 Token 生成内部语法结构(抽象语法树 AST 或动态代码)
这些工作不是可以一蹴而就的。因此我们放慢脚步,首先实现第一条:将文本解析成 Token。这是一个相对独立的工作,为了避免 Template 的实现过于复杂,可以把它作为单独的函数,并编写测试:
class TokenizeTest(unittest.TestCase):
def test_single_variable(self):
tokens = tokenize("Hello, {{name}}!")
self.assertEqual(tokens, [
Text("Hello, "),
Expr("name"),
Text("!")
])
请注意,如果你看过原文的话,会发现它使用的是过程式的风格,而测试代码也全部是针对模板的外部接口进行的、粗粒度的测试。本文在开始写作时,对于使用何种风格并没有明确的倾向,但一旦开始这种细粒度的测试,就会发现:面向过程的方式缺乏明确定义的概念来帮助我们编写这种测试,只有面向对象的风格才可以。也就是说,测试在把我们导向 OOP。这是测试影响设计的一个明显的标志。
我们要实现两种类型的 Token,分别代表纯文本内容和需要计算的表达式。用 UML 简单表示它们的设计如下:
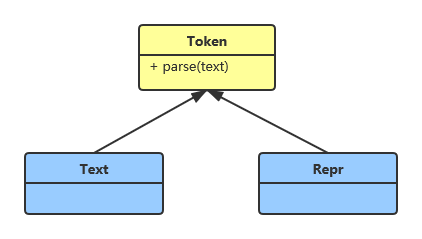
基于明确定义的分界符,用正则表达式就可以解析模板:
class Token:
def parse(self, content: str):
raise NotImplementedError()
...
class Text(Token):
def parse(self, content: str):
self._content = content
...
class Expr(Token):
def parse(self, content: str):
self._varname = content
...
def tokenize(text: str) -> typing.List[Token]:
segments = re.split(r'({{.*?}})', text)
return [create_token(x) for x in segments]
def create_token(text: str) -> Token:
if text.startswith("{{") and text.endswith("}}"):
token, content = Expr(), text[2:-2].strip()
else:
token, content = Text(), text
token.parse(content)
return token
按照良好的面向对象设计,我们让 Token 抽象类公开 parse() 方法,由每个子类去解析自己关心的内容。
如果我们现在去运行测试的话,会看到类似这样的输出:
AssertionError: Lists differ: [<tem[60 chars]196AA148>, <template_engine.step01_expr.tokeni[109 chars]208>] != [<tem[60 chars]196AA048>, <template_engine.step01_expr.tokeni[109 chars]248>]
First differing element 0:
<template_engine.step01_expr.tokenizer.Text object at 0x0000029A196AA148>
<template_engine.step01_expr.tokenizer.Text object at 0x0000029A196AA048>
出现这样古怪的结果是因为两个原因。第一是我们的类没有实现相等性比较,因此即使它们的内容是完全相同的,assertEqual() 也会返回 False。此外,为了看清对象的实际内容,还应该实现 __repr__。因此,我们应当实现 __eq__ 和 __repr__ 两个重要方法。它们的逻辑都是非常简单的,但是全部写在这里的话会太占用篇幅,因此请大家自行浏览代码库中的实现。
现在第一个测试已经能正常通过了。不过为了保险起见,我们还是再写一个更加复杂的测试:
def test_two_variables(self):
tokens = tokenize("Hello, {{name}} in {{year}}")
self.assertEqual(tokens, [
Text("Hello, "),
Expr("name"),
Text(" in "),
Expr("year")
])
它果然找到了代码中的一个问题:通过正则表达式解析得到的分片内容可能是空的,因此会在结果中看到额外的 Text(),从而导致比较失败。空文本对生成代码没有贡献,可以简单地忽略它们:
def tokenize(text: str) -> typing.List[Token]:
segments = re.split(r'({{.*?}})', text)
segments = [x for x in segments if x]
return [create_token(x) for x in segments]
修改过实现之后,测试就顺利通过了。接下来地工作是修改 Template,让它解析文本并生成代码。我们还是把这个工作委托给各个 Token 自己去实现,而通过抽象方法 generate_code() 来统一接口。而 Template 使用一个特殊变量 output 来收集所有代码。因此,对于类似这样的模板:
Hello {{name}}!
它应当对应生成这样的内部代码:
output.append("Hello ")
output.append(name)
output.append("!)
按照以上设想,修改 Template 的实现如下:
OUTPUT_VAR = "_output_"
class Template:
def __init__(self, text: str):
self._text = text
self._code = None
def _generate_code(self):
if not self._code:
tokens = tokenize(self._text)
code_lines = [x.generate_code() for x in tokens]
source_code = '\n'.join(code_lines)
self._code = compile(source_code, '', 'exec')
def render(self, ctx: dict) -> str:
self._generate_code()
exec_ctx = (ctx or {}).copy()
output = []
exec_ctx[OUTPUT_VAR] = output
exec(self._code, None, exec_ctx)
return "".join(output)
这里用到了懒惰初始化的技巧:如果从来没有调用过 render(),那么编译的动作也无需执行,从而避免无谓的浪费。输出变量的名称在 Token 内部也会用到,为了避免不一致产生错误,我们把输出变量名规定为常量(加下划线是为了避免和用户变量冲突)。
然后是各个 Token 生成代码的实现:
class Token:
def generate_code(self) -> str:
raise NotImplementedError()
class Text(Token):
def generate_code(self) -> str:
return f"{OUTPUT_VAR}.append({repr(self._content)})"
class Expr(Token):
def generate_code(self) -> str:
return f"{OUTPUT_VAR}.append({self._varname})"
对于文本内容,我们要用 repr() 把它转化为合法的代码形式,否则会出现语法错误。
实现完毕后执行单元测试,它应该是通过的。为了保证实现的健壮性,可以针对不同的变量形式增加更多的测试。事实上,通过测试确实捕获到了一个问题:因为表达式的结果未必是字符串,而非字符串内容不能直接参与 join,所以我们有必要执行一个转换,以保证放到输出的所有内容都是字符串形式:
class Expr(Token):
def generate_code(self) -> str:
return f"{OUTPUT_VAR}.append(str({self._varname}))"
我们也应该测试可能的异常情况,比如模板中包含变量,但实际并未传递该值的场景。编写测试如下:
def test_expr_variable_missing(self):
self.render("{{name}}", {}, "")
运行代码,会抛出 NameError: name 'name' is not defined。这个行为对于用户来说也还算容易理解,因此我们不再尝试包装它。测试修改如下:
def test_expr_variable_missing(self):
with self.assertRaises(NameError):
self.render("{{name}}", {}, "")
过滤器
在表达式的基础上,我们可以更进一步:让它支持过滤器,也类似 Unix 管道的串联调用形式。一个典型的过滤器调用如下所示:
{{ name | upper | strip }}
上述代码的功能是:将字符串变量转换为大写,并去掉两边的空白符号。它的实际效果相当于 strip(upper(name)),但在视觉上更加简单一些,也可以避免由于括号不匹配而产生的错误。
说明:这里我们对目标做了一点简化。对于真正的模板引擎比如 Jinja2 来说,过滤器可能是更为复杂的函数调用,比如 {{ name | default('No data') }}。然而,解析带有嵌套函数和表达式的过滤器比较棘手,可能要转向基于有限状态机的实现,这对于我们的例子而言是过于复杂了。为此,我们把目标设定为不带参数的过滤器。这样我们的工作就得以大大简化。但即便在简化以后,我们也不能简单地用 | 来分割它们,因为表达式本身也可能是包含 | 的字符串。
意识到解析过滤器的过程可能会比较复杂,我们还是放慢节奏,一步一步来。首先还是编写测试:
def test_parse_repr(self):
cases = [
("name", "name", []),
("name | upper", "name", ["upper"]),
("name | upper | strip", "name", ["upper", "strip"]),
("'a string with | inside' | upper | strip", "'a string with | inside'", ["upper", "strip"])
]
for expr, varname, filters in cases:
parsed_varname, parsed_filters = parse_expr(expr)
self.assertEqual(varname, parsed_varname)
self.assertEqual(filters, parsed_filters)
我们希望实现一个解析方法 parse_expr(),从完整的形式解析出前面的基础值和后续的过滤器集合。这个测试覆盖到 0、1 和多个过滤器的场景,为了完整性目的,还考虑到表达式本身包含 | 的情形。
为了拆分出过滤器,还是使用正则表达式:
def extract_last_filter(text: str) -> (str, str):
m = re.search(r'(\|\s*[A-Za-z0-9_]+\s*)$', text)
if m:
suffix = m.group(1)
filter_ = suffix[1:].strip()
var_name = text[:-len(suffix)].strip()
return var_name, filter_
return text, None
def parse_expr(text: str) -> (str, typing.List[str]):
var_name, filters = text, []
while True:
var_name, filter_ = extract_last_filter(var_name)
if filter_:
filters.insert(0, filter_)
else:
break
return var_name, filters
上述代码循环从表达式末尾查找过滤器,如果找到,则提取出来并放到结果集合中;否则查找结束。
解析部分到此写好了。过滤器只涉及表达式,因此要修改的部分基本上只要关注 Expr 这个类即可。但是且慢,还有一个问题需要考虑:模板引擎应该支持哪些过滤器?
作为示例,我们可以只实现一到两个过滤器,能够说明问题即可。但在现实项目中,总是希望模板引擎具有足够的灵活性,最好不要让设计者完全定死,而是可以让用户按照自己的要求去指定哪些过滤器可用。如果同学们比较熟悉 Flask 或者 Django 的话应该知道,在这些框架中,模板的创建是由框架内部管理的,但我们可以通过配置去调整,以满足具体项目的要求。
要让模板引擎具备这种灵活性的话,简单的构造函数将难以满足要求。为此引入一个新的类:TemplateEngine(恰好对应模板引擎这个概念)。从本质上讲,它就是设计模式中 Factory 模式的一种应用(也可以认为是类似的 Builder)。引入 TemplateEngine 之后,初始化模板的代码应该类似这样:
engine = TemplateEngine()
engine.register_filter('upper', lambda x: x.upper())
engine.register_filter('strip', lambda x: x.strip())
template = engine.create(source)
这样,只要把 register_filter() 方法暴露出来供用户调用,我们就有了一个可扩展的模板引擎。
为此,把测试接口稍微修改一下,允许它接受额外的过滤器参数(filters)。然后编写新的测试(render() 方法内部也要作相应的修改,类似上面代码,为节约篇幅不再列出):
def test_expr_with_addition_filter(self):
first = lambda x: x[0]
self.render("Hello, {{ name | upper | first }}!",
{"name": "Alice"},
"Hello, A!",
filters={"first": first})
按照接口实现模板引擎类:
class TemplateEngine:
def __init__(self):
self._filters = {}
def register_filter(self, name: str, filter_):
self._filters[name] = filter_
def create(self, text: str) -> Template:
return Template(text, filters=self._filters)
再修改 Template,将注册的过滤器保存下来,执行时作为全局变量:
class Template:
def __init__(self, text: str, filters: dict = None):
...
self._global_vars = {}
if filters:
self._global_vars.update(filters)
def render(self, ctx: dict) -> str:
...
exec(self._code, self._global_vars, exec_ctx)
功能完成之后,再花点时间考虑边界情况。最可能的问题是过滤器没有定义(可能因为输入错误)。为该情况编写写一个测试:
def test_filter_not_defined(self):
with self.assertRaises(NameError):
self.render("Hello, {{ name | upper | first }}!",
{"name": "alice"},
"Hello, A!")
Python 在执行代码时如果找不到变量,就会抛出 NameError,因此我们不需要为这种情况去额外编码了。
注释
接下来的任务比较轻松:支持在模板中插入注释。
注释的语法模仿 Jinja2:{# This is a comment. #}。我们已经实现了类似的解析语法,所以这个任务是很容易的。不过还是按照节奏,首先编写解析 Token 的测试用例:
def test_comment(self):
tokens = tokenize("Prefix {# Comment #} Suffix")
self.assertEqual(tokens, [
Text("Prefix "),
Comment("Comment"),
Text(" Suffix"),
])
为了支持注释,解析语法使用的正则表达式要扩展一下,并新增 Comment 类以代表注释语句:
def create_token(text: str) -> Token:
...
elif text.startswith("{#") and text.endswith("#}"):
token, content = Comment(), text[2:-2].strip()
...
def tokenize(text: str) -> typing.List[Token]:
segments = re.split(r'({{.*?}}|{#.*?#})', text)
...
Comment 的实现极其简单,这里就不再列出了。
然后,编写模板的测试用例:
def test_comment(self):
self.render("Hello, {# This is a comment. #}World!",
{},
"Hello, World!")
如果我们现在去运行测试,会发现结果是失败的。这揭示了代码的一个潜在问题:注释并不生成代码(因此 generate_code() 返回值是 None),但 join() 方法并不接受 None。我们要把在生成代码之前进行检查,去掉不需要的值:
class Template:
def _generate_code(self):
if not self._code:
tokens = tokenize(self._text)
code_lines = [x.generate_code() for x in tokens]
code_lines = [x for x in code_lines if x]
source_code = '\n'.join(code_lines)
...
再运行测试,就可以成功了。
For 循环
现在我们要进入比较复杂的阶段:实现代码块。在 Jinja2 模板引擎中,它们也被叫做控制结构(Control structure)。常用的代码块主要包括 For 和 If,它们各自有对应的结束语句,比如:
{% if messages %}
{% for msg in messages %}
{{ msg }}
{% endfor %}
{% endif %}
我们的任务是把它们转换为对应的 Python 代码。构造等效的 Python 代码看起来似乎并不困难,但我们要考虑到多种语句的解析、管理缩进、开始/结束的对应关系等等,因此程序的复杂度会有显著的提高。
考虑到 for 语句结构比较固定,而 If 涉及到 Elif/Else 等额外的从句,所以我们从 for 开始实现。
首先还是编写语法解析的测试:
def test_tokenize_for_loop(self):
tokens = tokenize("{% for row in rows %}Loop {{ row }}{% endfor %}")
self.assertEqual(tokens, [
For("row", "rows"),
Text("Loop "),
Expr("row"),
EndFor(),
])
For 语句包含两个重要变量:要遍历的目标集合以及当前项。因此,用于解析的正则再次扩展,以支持控制语句:
def tokenize(text: str) -> typing.List[Token]:
segments = re.split(r'({{.*?}}|{#.*?#}|{%.*?%})', text)
segments = [x for x in segments if x]
return [create_token(x) for x in segments]
create_token() 方法也需要增加对控制语句的解析:
def create_token(text: str) -> Token:
...
elif text.startswith("{%") and text.endswith("%}"):
content = text[2:-2].strip()
token = create_control_token(content)
...
我们可以预见到后面还会陆续实现多种不同的控制语句,这个分支会较为复杂,因此增加了一个 create_control_token() 函数来单独处理它。对于我们要实现的各种控制结构,只要通过解析到的第一个关键字就能确定它的类型,然后进行分派即可:
def create_control_token(text: str) -> Token:
text = text.strip()
m = re.match(r'^(\w+)', text)
if not m:
raise SyntaxError(f'Unknown control token: {text}')
keyword = m.group(1)
token_types = {
'for': For,
'endfor': EndFor,
}
if keyword not in token_types:
raise SyntaxError(f'Unknown control token: {text}')
return token_types[keyword]()
在开始实现 For/EndFor 之前,我们还必须解决一个大问题:之前的代码使用数组来收集代码行,但现在我们需要考虑缩进等问题,简单的数组已经不够用了。为此,设计一个用来管理代码的类:CodeBuilder。
class CodeBuilder:
def __init__(self):
self.codes = []
def add_code(self, line: str):
self.codes.append(line)
def indent(self):
self.codes.append(INDENT)
def unindent(self):
self.codes.append(UNINDENT)
def code_lines(self):
indent = 0
for code in self.codes:
if isinstance(code, str):
prefix = ' ' * indent * INDENT_SPACES
line = prefix + code
yield line
elif code in (INDENT, UNINDENT):
indent += code
以上显示了 CodeBuilder 的关键逻辑(完整的程序请参考代码库)。输出仍然是一个数组,但我们要在其中插入额外的值来控制代码的缩进与反缩进:要缩进则插入常量 INDENT(整数 1),取消缩进则插入 UNINDENT(-1)。code_lines() 方法负责根据缩进规则生成文本形式的代码。
现在,我们需要修改各个 Token 的接口以适应新的规则,因为 generate_code() 不能再只返回单个代码,而是可能返回多行。比如 For 控制语句的代码生成部分大致如下:
class For(Token):
def generate_code(self, builder: CodeBuilder):
builder.add_code(f"for {INDEX_VAR}, {self._varname} in enumerate({self._target}):")
builder.indent()
builder.push_control(self)
builder.add_code(f"loop = LoopVar({INDEX_VAR})")
这里使用 enumerate() 的目的是支持循环变量,免得用户自己去记录循环次数(模仿 Jinja2 的接口)。
而 EndFor 则取消缩进,同时也会检查是否有匹配的 For:
class EndFor(Token):
def generate_code(self, builder: CodeBuilder):
builder.unindent()
builder.end_block(For)
完成上述代码之后,测试就可以通过了。
再来考虑可能出现的边界情况和错误。语句块非常可能出现开始/结束不匹配的问题,如果出现此种情况,我们规定统一抛出 SyntaxError 异常。因此编写测试如下:
def test_render_for_loop_no_start_tag(self):
with self.assertRaises(SyntaxError):
self.render("{% endfor %}",
{"messages": ["a", "b", "c"]},
"")
为了通过测试,在 CodeBuilder 中用一个类似堆栈的结构记录控制语句,在正常情况下,遇到 For 则入栈,EndFor 则出栈,如果无法匹配的话,就表明模板语法有问题:
class CodeBuilder:
def end_block(self, begin_token_type):
block_name = begin_token_type.name
if not self._block_stack:
raise SyntaxError(f'End of block {block_name} does not found matching start tag')
top_block = self._block_stack.pop(-1)
if type(top_block) != begin_token_type:
raise SyntaxError(f'Expected end of {block_name} block, got {top_block.name}')
return top_block
OK! 模板引擎现在可以正确处理 For 循环了。
If 语句
现在我们来看如何实现 If 代码块。从理论上讲,它应该比实现 For 更为复杂,因为它除了块开始/结束之外,还包含两种额外的分支:
{% if flag1 %}
flag1
{% elif flag2 %}
flag2
{% else %}
none
{% endif %}
但实际上,大部分基础性的工作已经在上一步完成了,我发现这一步的实现简单到几乎没有什么可说的。简单看一下其中一个控制语句的实现:
class ElseIf(Token):
...
def generate_code(self, builder: CodeBuilder):
builder.unindent()
builder.add_code(f"elif {self._repr}:")
builder.indent()
因此,我们要做的无非是按部就班地实现几个子类,再把它们添加到 create_control_token() 方法支持的语句类型即可。所以代码就不再解释了,完整的程序可参考代码库的 step05_if_block 部分。
性能问题
模板引擎的所有功能到此全部实现完毕了。如果你读过原文的话,会知道原作者在设计模板的时候做了一个优化,即把常用的拼接方法单独提取出来,意图是减少不必要的方法查找,加快执行速度。因此,生成的代码类似这样:
result = []
append_result = result.append
append_result(...)
append_result(...)
然而,本文是按照敏捷原则、使用 TDD 方法开发的。敏捷原则要求我们避免过早进行程序优化,而是应该首先关注可运行的代码,再让它可维护,最后再去考虑速度问题。因此在前面的代码中,我们除了预先编译代码以外,其他地方并没有特意去考虑性能。如果要进行优化的话,我们也应该首先进行性能测试,让数字来告诉我们不同的设计方案对代码性能到底有多大的影响。
基于以上考虑,我分别采用不进行任何优化、以及原作者的优化方式,为相同的模拟模板逻辑生成代码,希望借此比较一下两者在性能上有多大差别。为了避免封装影响测试结果,本案例仅使用最基本的语言功能,而不使用前面包装过的模板实现:
def unoptimized_code() -> str:
return """
lines.append("Message 1")
lines.append("Message 2")
lines.append("Message 3")
"""
def optimized_code() -> str:
return """
c_append = lines.append
c_append("Message 1")
c_append("Message 2")
c_append("Message 3")
"""
def test(fn):
start = time.perf_counter()
source = fn()
code = compile(source, '', 'exec')
for i in range(TIMES):
lines = []
exec(code, None, {"lines": lines})
result = '\t'.join(lines)
elapsed = time.perf_counter() - start
print(f"Execute {fn.__name__} used time: {elapsed}, result: {result}")
实际比较结果如下:

令人惊讶的是,没有优化过的实现反而会更快一些。本结果是在 Windows 10 / Python 3.7 上面测试的,如果你在其他平台测试的话,也许会得到不一样的结果。
我并没有深究为什么无优化的代码反而更快的原因所在。既然简单的测试已经表明,(对目前的平台)原作者期望的那种优化措施实际上对于提高性能没有帮助,那么也就无需为此再去修改代码了。
希望以上过程会让大家意识到:在没有明确性能评测数据的前提下,不要仅凭猜想就去修改设计,否则不仅无助于优化,还有可能会适得其反。
面向过程与面向对象
本文使用了面向对象的开发方法,这是和原文的另一个重大区别。
如果大家阅读过原文的话,会发现它的实现基本上是面向过程的。虽然它也使用了 CodeBuilder(和本文的实现差别很大),但绝大部分具体功能是在 Templite 类的一个相当长的函数中实现的。
本文采取的面向对象设计风格,把针对各种代码块的语法规则分派给 Token 的各个子类去处理,Template 和 CodeBuilder 比起原作者的版本都要简单很多。特别是,如果以后引入新的语法构造,那么也只需要增加新类,上述两个类只需要作微小的改动。
通过本项目的实现也能够感受到,对于同样的项目,面向对象与面向过程的区别:
- 面向对象版本的代码更长
两个版本实现的功能是类似的,不过原作者的实现代码(不含测试)大约在 250 行出头,而本文的代码几乎达到 350 行。这主要是因为本文的实现包含大量子类,每个类都包含重载方法和用于比较的辅助函数,因此在代码空间的使用上不如过程版本那么紧凑。
- 面向对象版本更具有表意性
复出长度的成本也带来了一些好处,其中之一就是类名表达了代码的语义,比如 Comment, Expr, EndIf 等等。如果名字起得好的话,读者可以直观地通过这些名称来理解代码的意图,而过程版本则缺乏这样的手段,只能通过阅读代码去揣测了。
- 面向对象版本更有结构性
本文的代码把功能分布到各个子类中,因此类的数量很多,但每个类都不算复杂。相对应的是,过程版本几乎所有复杂性都集中在单个巨大的函数。当然,这也可能是因为作为教学案例,作者并没有有意识地去分解它,但在生产项目中,它很容易变成被称作“代码泥球”的坏味道。
我知道有些同学不同意我的观点:他们更喜欢把所有代码写在一起,觉得这样才容易理解;而面向对象的写法需要在多个类之间来回跳转,如果缺乏结构化思维的话往往会难以适应。长期来看,任何复杂的功能迟早是要分解的,否则它总会在某一个时间点上失去控制。
- 面向对象版本更容易维护
在开发过程中已经感受到了这一点:如果要支持新的语法,只需要增加新类,原有代码几乎不需要修改;如果真的要修改,也只需要把修改范围局限在一两个类的内部,不至于引起大范围的破坏。当然,这也需要经过深思熟虑的职责划分,才能保证设定的边界起到保护作用而不是反效果。
- 面向对象的灵活性是有限度的
尽管到目前为止我似乎一直在表扬面向对象地优点,但是公平地说,它也存在一个潜在的问题:如果类体系的设计不合理,那么它维护起来反而更为困难,重构的代价也更高。
我们不太容易从这个例子看到这一点,因为模板引擎尽管具体形式千变万化,但基本语法是非常稳定的,因此类的体系结构也是稳定的,这种场合很适合应用 OOP。但现实中的大量业务用例例子可能会遇到无法预料的需求变更,如果你设计的类结构比较复杂的话,那么修改起来会相当棘手(也容易出错)。纯粹的函数彼此之间耦合较弱,改动起来也容易一些。
我个人对于编程风格没有特别的偏好:对于 OOP 存在一些特别适用的领域,面向过程也有自己的用武之地,在计算为主的场景下纯粹的函数式风格通常表现更好。Python 语言特别让人欣赏的一点就是,它不强迫你采用任何特定的风格(某些框架可能会),因此你可以自由选择最适合自己的程序结构。
总结
到此,我们实现了一个较为完整的模板引擎,支持表达式、过滤器、注释以及复杂的控制结构。支持以上功能的模板引擎已经能够相当复杂的任务了(原文的实现用来支持 coverage.py 生成的 HTML 报告)。
当然,要真正实现一个生产级别的模板引擎,还要考虑许多其他功能,比如:
- 模板的包含与继承
- 自定义函数或标签(如
Jinja2中的 macro) - HTML 特殊字符自动编码(防止跨站点脚本)
- 参数化过滤器
- 调试支持和详细的错误信息
等等。
在代码说明部分也提到过,本文使用的文本解析方式使用的是最基本的正则表达式。当模板语法复杂到一定程度以后,仅靠正则去解析就不太可行了,最终可能要自己手写一个真正的语法解析器(或借助外部工具)。显然,我们不太可能在 500 行之内完成这个工作。如果目标并不是制作复杂的网页,而是根据数据生成 HTML 或其他文本形式的报表,那么这个引擎已经足够好用了。
要是想看一个真正的模板引擎例子,不妨参考 Jinja2。它有着超过 7000 行的实现以及 5000 行测试,算是一个颇有规模的工程,建议有一定经验、且业余时间比较充裕的同学去尝试。
如果你觉得模板引擎在前端工程化的背景下已然式微,那么不妨看看时下流行的解决方案——能用 500 行代码写出 Angular、React 或者 Vue 吗?当然,这其中最关键的问题可能是如何实现针对虚拟 DOM 的算法。对这个问题我也没有答案,如果你觉得可行的话,不妨一试!
文章索引
- 重写 500 Lines or Less 项目 - 前言
- 重写 500 Lines or Less 项目 - Web Server
- 重写 500 Lines or Less 项目 - Template Engine
- 重写 500 Lines or Less 项目 - Continuous Integration
- 重写 500 Lines or Less 项目 - Static Analysis
- 重写 500 Lines or Less 项目 - A Simple Object Model
- 重写 500 Lines or Less 项目 - A Python Interpreter Written in Python
- 重写 500 Lines or Less 项目 - Contingent
- 重写 500 Lines or Less 项目 - DBDB
- 重写 500 Lines or Less 项目 - FlowShop
- 重写 500 Lines or Less 项目 - Dagoba
- 重写 500 Lines or Less 项目 - 3D 建模器