重写 500 Lines or Less 项目 - Static Analysis
概述
本文章是 重写 500 Lines or Less 系列项目其中一篇,目标是重写 500 Lines or Less 系列的原有项目:静态分析/Static Analysis。原文章代码是基于 Julia 这种新型的编程语言,主要分析目标是该语言中比较被强调的一个特性:多重分派(multiple dispatch)。考虑到 Julia 语言并不是特别普及,同时多重分派在其他语言中也并非常见特性(也有与之相近的概念),可能大部分读者对它会比较陌生,影响对于原文的理解。因此,本文选择基于主流、同时也比较便于学习和理解的 Python 来演示静态分析的原理和过程,不再按照原文的体例。
示例代码
本文及系列文章的所有代码都开源在 Github 仓库:500lines-rewrite。本文相关代码位于 static_analytics 目录,其中 main.py 为执行程序的入口点,tests 目录则是用内置模块 unittest 编写的单元测试代码。
读者可以在命令行或者集成开发环境中直接执行上述程序或测试代码,来检查实际效果。需要说明的是,程序和测试在执行过程中可能会生成一些辅助性的文件(默认位于 dump 目录下),如果程序运行所在的工作目录不是 static_analysis 的话,那么执行有可能会出错,或者把文件输出到其他意外的位置。
静态分析
虽然听起来像一个比较高深的概念,实际上从用户角度讲,使用各种编程语言的开发者对静态分析技术已经非常熟悉了。当我们在自己喜爱的编辑器或 IDE 中编辑代码的时候,这些工具会在幕后自动解析源码,将其中可疑或有错误的部分用红色波浪线标记出来。熟练的开发者会把执行代码风格检查、或者叫做 Linting 的工具加入自己的工具箱,通过持续集成之类的技术,让它们在每次签入代码时自动执行,其结果也可以作为评估代码质量或开发节奏的辅助信息。
对 Python 来说,从著名的 PEP8 开始,很多推荐的代码风格和指导性建议被陆续引进官方规范之中。在此基础上也诞生了众多静态分析和检查工具,比如 pylint、pydockstyle、pyflakes、flake8,以及各个 IDE 集成的同类功能。大家可能或多或少已经用过上述工具的其中一些了。
要想实现对程序代码的静态分析功能,首先要将源码解析成能够理解的结构化数据,也就是所谓的抽象语法树(AST)。这是个有相当难度的工作,好在我们不需要从头做起,以 “自带电池” 而著称的 Python 已经内置了这个功能。让我们先来了解这个有用的模块:ast。
Python 内置模块:ast
ast 模块的基本用法是相当简单的:解析源码,得到抽象语法树。
import ast
code = """print('Hello World!')"""
root = ast.parse(code)
print(root)
以上代码会在命令行输出(实际数字当然在每台机器上结果不同):
<_ast.Module object at 0x0000021C9ECA6BE0>
Python 程序以模块为代码组织的基本单位,因此解析到的根节点总是一个 Module 对象。所有节点都是 ast.AST 的子类。要了解完整的节点类型列表,我们可以参考官方文档 Abstract Syntax Trees:
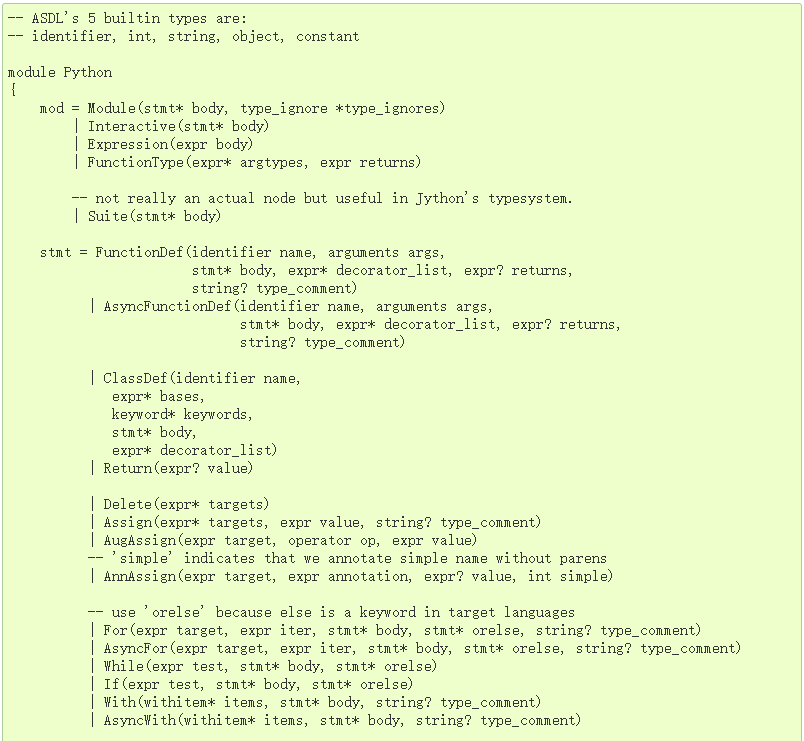
以上是一个并不完整的列表。我们从名字大概就可以知道它们的含义:赋值(Assign)、返回(Return)、循环(For)、条件判断(If),以及更加高层的块级语法,包括函数定义(FunctionDef)、类定义(ClassDef),等等。异步方法的元素则是单独定义的(名字带有 Async 前缀)。
除了知道有哪些可能的语法元素外,我们还需要了解 AST 的结构是什么样的。当然,每种节点有自己的数据定义,不过从一般角度讲,所有节点都有两个重要成员(都有下划线):
- _attributes 节点自身的属性。它们通常是一些简单的值,几乎所有节点都包括以下四个属性:
lineno/col_offset/end_lineno/end_col_offset。显然,它们表示元素在代码中的起止位置。有点不太直观的是,lineno是从 1 开始计数,而col_offset却是从 0 开始计数的。这是设计上一点缺乏一致性的地方。 -
_fields 包含节点持有的“子节点”。这是一个有点抽象的说法,实际上它可能是以下三种情况之一:
-
节点本身持有的信息,通常是比较复杂的对象
- 另一个
AST节点,也就是该节点的子节点 - 在更复杂的情况下可能是列表(
list),表示多个子节点的集合。
由于 AST 本身是一个树状结构,用来处理它的算法几乎总是递归的。为了支持节点遍历这种常见需求,ast 模块提供了一个抽象类:NodeVisitor,从名称可知,它使用了 Design Patterns 中的访问者模式。我们的实现会大量使用该类,所以先对它有一个深入的了解是很有必要的。(此外还有一个更加高级的 NodeTransformer,不过本文不涉及转换 AST 的内容,因此不作讨论。)
NodeVisitor 是一个抽象基类。要使用它,我们需要继承它得到一个派生类,再按照自己的要求添加成员。常见的实现模式有以下两种:
- 如果我们关心某种特定类型的的节点,按照
NodeVisitor的约定,需要添加一个名为visit_XXXX的方法,其名称和节点的类名严格对应(各种节点对应的类型可参考前面给出的AST文档),参数是访问到的节点。例如,要访问函数定义,则添加方法visit_FunctionDef(node),依此类推; - 如果想要同时支持多种节点类型,或有其他特殊要求,可以重载其
visit(node)方法。
不管使用哪种方式,如果要继续遍历的话,必须调用基类的 generic_visit(node) 方法,否则遍历过程将会中断。
典型示例如下所示:
class MyVisitor(ast.NodeVisitor):
def visit(self, node: ast.AST):
print('visit node:', node)
return self.generic_visit(node)
def visit_FunctionDef(self, node: ast.FunctionDef):
print('visit function:', node)
return self.generic_visit(node)
实际上,NodeVisitor 的实现并不复杂,而且可以帮助我们理解为什么会有上述要求。我们不妨看一下源码:
class NodeVisitor(object):
def visit(self, node):
method = 'visit_' + node.__class__.__name__
visitor = getattr(self, method, self.generic_visit)
return visitor(node)
def generic_visit(self, node):
for field, value in iter_fields(node):
if isinstance(value, list):
for item in value:
if isinstance(item, AST):
self.visit(item)
elif isinstance(value, AST):
self.visit(value)
从源码可以发现,visit 方法会根据节点类型寻找对应的处理函数,如果没有定义的话,则调用 generic_visit()。而 generic_visit() 的做法则是访问所有字段,如果是 AST 节点的话,就递归执行下去。值得注意的是,根据字段值是否为列表需要进行不同的处理。
输出 AST
理论性的东西我们已经讲了很多,不过眼见为实,具体的语法树到底是什么样子?Python 的 ast 模块有一个辅助方法 dump() 可以输出 AST 内容,大家可以自己试试看。一个基本的输出大概是类似这样的:
Module(body=[FunctionDef(name='add', args=arguments(posonlyargs=[], args=[arg(arg='a', annotation=None, type_comment=None), arg(arg='b', annotation=None, type_comment=None)], vararg=None, kwonlyargs=[], kw_defaults=[], kwarg=None, defaults=[]), body=[Return(value=BinOp(left=Name(id='a', ctx=Load()), op=Add(), right=Name(id='b', ctx=Load())))], decorator_list=[], returns=None, type_comment=None)], type_ignores=[])
可见内容并没有得到很好的整理,看上去相当吃力,即便手工格式以后也还是不够清晰。社区也存在一些第三方工具,比如 instaviz 可以把 AST 结构渲染成图形,有兴趣的同学也可以尝试。然而说实话,instaviz 生成的界面非常复杂且缺少重点,缺乏经验的用户很容易看得一头雾水。
为了实现静态分析,我们需要对目标代码的 AST有一个清楚的了解,因此帮助我们查看 AST 结构的辅助工具是非常有必要的。既然没有理想的工具,不妨自己来写一个。本文将要实现的工具使用另外一种思路:将 AST 结构输出到 XML 文件。之所以选择这个方法,主要是出于以下几方面原因:
- 首先,AST 的复杂性可能会超出你的预料。输出到普通文本,哪怕是带有缩进的文本,其内容仍然过于复杂。而 XML 可以很好地展示内部结构;
- 其次,现代编辑器对 XML 这样的结构化文本都有完善的支持,用户可以展开或折叠特定地节点,逐步了解各个层次结构,同时忽略那些不需要关心的部分;
- 有的朋友可能会问,为什么不使用
JSON?网络上很多资料会告诉你JSON比XML更简单,但那是有条件的。对于 AST 这种复杂的结构,XML每个元素都有明确的名字,可以清楚地看到每个节点的类型,而JSON必须付出额外的努力,才能理解每一层大括号到底表示什么含义。另外,JSON文档格式化以后太过冗长,同时嵌套层次又非常深,对于阅读来说其实是非常不利的。使用XML还有一个好处,那就是AST的_attributes和_fields恰好能匹配到 XML 中Attribute与Element的概念,所以处理起来更加自然。
我把生成 XML 的操作封装到源码中的 astxml.py 模块。因为这只是个辅助工具,就不再占用文章篇幅了,读者有兴趣的话可以去阅读源码。现在,我们可以用一个简单的源码来进行测试:
import ast
from astxml import AstXml
code = """
def add(a, b):
return a + b
""".strip()
ast_node = ast.parse(source_code)
AstXml(ast_node).save_file('filename.xml')
然后打开生成的 XML 文件,应该会看到类似这样的内容(部分):
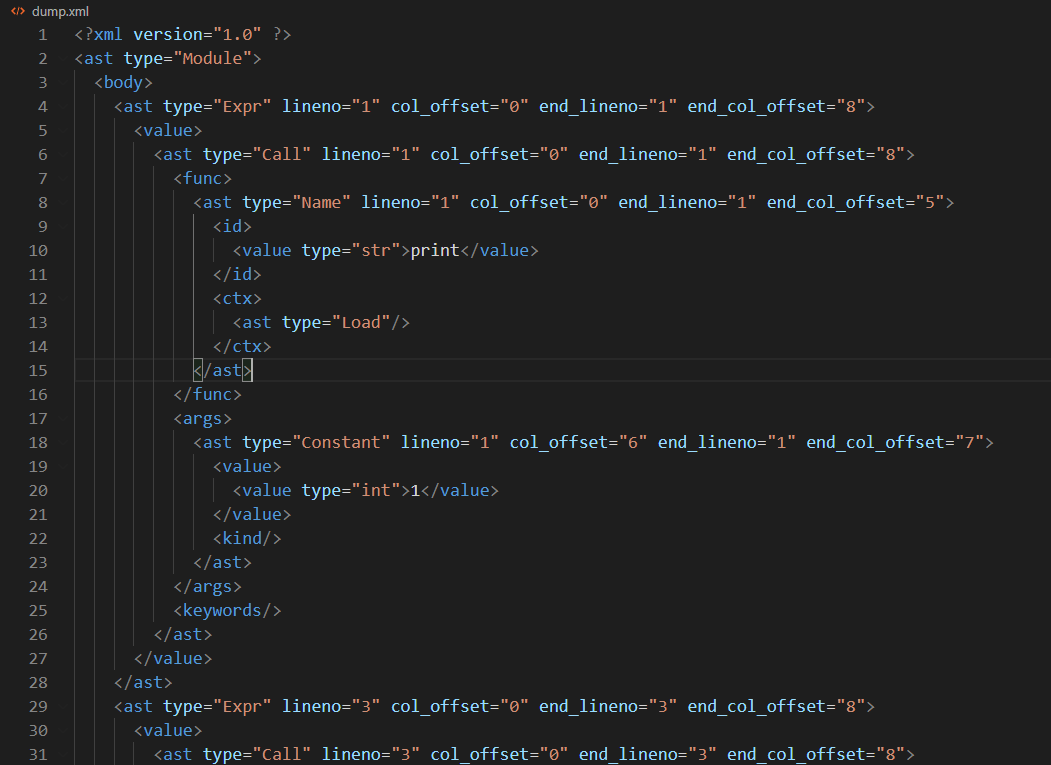
初学者首次看到 AST 结构往往会吓一跳,因为它比起对应的源码来说实在是复杂太多了。不过仔细多看几遍,还是能看出一些规律的:
- AST 的根节点总是从
Module开始; - 除了
Module之外,所有 AST 节点几乎都包含起止位置的行号/列号,也就是lineno/col_offset/end_lineno/end_col_offset这几个字段; - 每种 Python 语法有自己的 AST 结构。比如
print()方法调用,我们可以再分析其结构: - 它是一个表达式(
Expr) - 表达式内容是函数调用(
Call) - 函数引用是一个
Name,Name.id记录其具体名称 - 参数是一个集合,对于常量参数,表示为
Constant
以上虽然是一个简单的示例,但也揭示了静态分析工具的典型开发方法:不论多么复杂的语法处理,首先要做的是理解它的 AST 结构是什么样的,然后才能做出相应的处理。
编写程序
现在,我们理解了 AST 的基本原理和分析方法,是时候开发一个真正的静态分析工具了。
本文的实现目标是:挑选出一些常见的 Python 代码问题,通过自己编写静态分析工具来识别到这些问题,并返回明确的出错(或警告)信息给用户。
我们已经看到,AST 结构是相当复杂的,可想而知解析的工作也比较容易出错。因此用测试驱动开发(TDD)来保证程序质量是一个不错的主意。我们也会采用自底向上的方式,先逐个实现对每种问题的单独检查,再把所有功能组合起来形成完整的程序。
数据结构设计
在实现检查之前,首先设计一下程序需要的数据模型。我们需要一个数据结构来表示出错的信息,可以想象,它应该包括文件名、出错位置、错误信息等。为了便于处理,很多工具还会给每种错误类型分配一个内部编号。本文系列的基本原则是充分利用语言特性,不用特意考虑对低版本的兼容性问题,因此用新的数据类(dataclass)来描述:
@dataclass
class CodeIssue:
filename: str = None
line: int = 0
column: int = 0
code: str = None
message: str = None
def __str__(self):
pattern = '{file}({line},{col}) {code}: {message}'
return pattern.format(file=self.filename,
line=self.line,
col=self.column,
code=self.code,
message=self.message)
考虑到检查过程通常会找到多个错误,再实现一个 Context 类来管理找到的内容:
class AnalysisContext:
def __init__(self, filename: str):
self.filename = filename
self.issues = []
def add_issue(self, node: ast.AST, code: str, message: str):
issue = CodeIssue(filename=self.filename,
line=node.lineno,
column=node.col_offset,
code=code,
message=message)
self.issues.append(issue)
该类基于一个简化的假定:本示例实现的检测都是针对单个代码文件的。实际开发中当然需要支持多个源文件,但管理多个文件及其与问题的映射关系需要很多额外的工作,且显得有点偏离主题。读者如果觉得不满意的话,可以在实现基本功能之后再进一步扩展。
代码长度检查
PEP8 中对代码长度有这样的要求:
Limit all lines to a maximum of 79 characters.
For flowing long blocks of text with fewer structural restrictions (docstrings or comments), the line length should be limited to 72 characters.
我们已经知道,几乎所有 AST 节点都包含行号/列号信息,因此实现长度检查的要求是非常容易的。不过,AST 结构不是固定的,要访问所有节点就必须使用递归遍历的方法,也就是前面介绍过的 NodeVisitor。针对长度检测这个要求而言,我们计划实现一个派生类称为 LineLengthVisitor。按照 TDD 的要求,首先为它编写一个测试:
class LineLengthVisitorTest(TestCase, VisitorTestMixin):
visitor_type = LineLengthVisitor
def test_visit(self):
code = """
print('short line')
print('this is a very, very, very, very, very, very, very, very, very, very, very, very long line...')
""".strip()
ctx = AnalysisContext('test.py')
visitor = LineLengthVisitor(self.ctx)
ast_node = ast.parse(code)
visitor.visit(ast_node)
AstXml(ast_node).save_file('dump/line-length.xml')
self.assertEqual(1, len(ctx.issues))
issue = ctx.issues[0]
self.assertEqual((2, 'W0001'), (issue.line, issue.code))
这段代码略微有点长,但其中的逻辑不难理解。代码创建 LineLengthVisitor 来遍历AST 结构,如果实现正确的话,应该发现第 2 行超过了允许的长度(回忆一下,行号从 1 开始计数)。按照约定的规则,我们应该给错误信息一个编号。这是第一个目标问题,且应该视为警告(Warning)而不是错误,所以我们把它编号为 W0001。
上述测试选择行号和信息编号两个字段来检查,是因为它们通常是相对稳定的。列号和消息通常变化比较大,容易引起测试的不稳定。当然,在产品级别的代码中还是应该想办法加以验证,作为演示程序来说就不在这上面费力气了。
能够通过测试的实现逻辑很简单:
class LineLengthVisitor(ast.NodeVisitor):
max_length = 79
def __init__(self, ctx: AnalysisContext):
super().__init__()
self.ctx = ctx
def visit(self, node: ast.AST):
if 'end_col_offset' in node._attributes and node.end_col_offset > self.max_length:
self.ctx.add_issue(node, 'W0001', f'Exceed max line length({self.max_length})')
else:
self.generic_visit(node)
尽管绝大部分 AST 节点都包含行列号,但也有个别节点不支持(比如 Module),为了避免出错,我们先验证这些字段确实存在,然后再去检查它们的值。如果当前节点没有问题的话,再检查它们的子节点,所以别忘了调用 generic_visit()。
现在运行测试的话,应该是正常通过的。很好!我们成功迈出了第一步。
要完整实现 PEP8,还需要注意关于文档的补充条款:
For flowing long blocks of text with fewer structural restrictions (docstrings or comments), the line length should be limited to 72 characters.
我们可以自己写一段带注释的 Python 代码,用上文实现过的辅助工具去分析其结构。但我们会发现一个棘手的问题:分析到的 AST 结构并不包含文档内容!这是因为 ast 模块主要是为执行 Python 程序服务的,它出于效率考虑去掉了一些在执行时无关紧要的信息,尤其是注释。不过好消息是,文档注释(docstring)还是保留下来了(如果我们是用 -OO 开关运行 Python 的,那么文档信息可能不会保留)。因此我们不得不降低要求,不去考虑注释,只分析 docstring。
再编写一个针对 docstring 的测试:
def test_visit_docstring(self):
code = """
def fn():
'''
This is a very, very, very, very, very, very, very, very, very, very, very, very long doc string
The second line
'''
pass
""".strip()
...
issue = ctx.issues[0]
self.assertEqual((3, 'W0001'), (issue.line, issue.code))
除了源码和错误信息之外,其他大部分代码是重复的,为节约篇幅就不再完整列出了。大家可以参考 Github 上的完整代码。
当我们试图实现上述规则的时候又会遇到一个棘手的问题。文档字符串(docstring)并没有单独的 AST 类型,而是表示为常量(Constant)。但要分析一个 Constant 是否是 docstring 不得不做一些额外的分析工作。实际上,ast 模块为我们提供了一个辅助方法 get_docstring(),但尝试一下就会发现,它返回的只是注释内容,不包含节点信息,因此无法获得准确的行号。我们不得不自己去做一些额外的工作:从 get_docstring 实现复制代码,并修改为返回节点:
def get_docstring_node(self, node):
"""Return the AST node of docstring"""
if not isinstance(node, (ast.AsyncFunctionDef, ast.FunctionDef, ast.ClassDef, ast.Module)):
raise TypeError("%r can't have docstrings" % node.__class__.__name__)
if not(node.body and isinstance(node.body[0], ast.Expr)):
return None
value_node = node.body[0].value
if isinstance(value_node, ast.Constant) and isinstance(value_node.value, str):
return value_node
return None
然后,修改 visit 方法,增加对注释内容的判断:
class LineLengthVisitor(BaseVisitor):
max_length = 79
max_docstring_length = 72
def visit(self, node: ast.AST):
if isinstance(node, ast.FunctionDef):
self.check_docstring(node)
# ... origin code
def check_docstring(self, node: ast.AST):
doc_node = self.get_docstring_node(node)
if not doc_node:
return self.generic_visit(node)
for offset, line in enumerate(doc_node.value.split('\n')):
if len(line) >= self.max_docstring_length:
lineno = doc_node.lineno + offset
self.ctx.add_issue(node, 'W0001',
f'Docstring for {node.name} exceed max length({self.max_docstring_length})',
lineno=lineno)
上述代码有带来一个新的要求:add_issue() 方法需要增加可选参数 lineno,因为具体行号和节点的开始位置有可能不是完全对应的。这个修改很容易实现,本文也不再具体列出了。
现在新增的两个测试都应该正常通过了。不过在开始下一个任务之前,我们应该考虑一下如何清理现有代码。目前仅有的两个测试已经出现了一些重复,特别是遍历 AST 和检查结果的部分。可以有把握地说:后面的测试仍然会使用类似的结构,只是参数和结果有所不同。为了简化后续的工作,有必要把这些重复的代码提取出来。
因为测试用例都是从 TestCase 派生而来的,重用代码最直观的思路是继承。(由于测试类本身持有一些状态,所以单纯的函数并不太适用)但是,使用派生类也存在一些潜在的问题,特别是抽象类可能会被错误地当作需要执行的用例。因此,我选择使用 Mixin 模式和多重继承,因为 Mixin 不是从 TestCase 继承而来,也就不会有被错误执行的风险。
将访问 AST 并检查结果的基本模式提取如下:
class VisitorTestMixin:
visitor_type = None
def run_visitor(self, code: str, xml_filename: str = None):
self.assertIsNotNone(self.visitor_type, 'Visitor type not defined.')
self.ctx = AnalysisContext('test.py')
visitor = self.visitor_type(self.ctx)
ast_node = ast.parse(code)
visitor.visit(ast_node)
if xml_filename:
AstXml(ast_node).save_file('dump/' + xml_filename)
然后,测试代码就可以简化成:
class LineLengthVisitorTest(TestCase, VisitorTestMixin):
visitor_type = LineLengthVisitor
def test_visit(self):
code = ...
self.run_visitor(code, xml_filename='line-length.xml')
self.assert_found_issue(2, 'W0001')
异常类型检查
接下来要实现的问题有关异常。按照业界的最佳实践,在多数情况下,我们应当尽量避免捕获所有异常,而是明确指定特定类型,从而使得异常处理更有针对性。以下是一个简单示例:
# Correct
try:
x = my_dict[key]
except KeyError:
...
# Wrong
try:
x = my_dict[key]
except Exception:
# or except:
...
为实现此要求,用辅助工具检查一下异常处理代码的 AST 结构:

可见:异常处理的主体是一个 Try 节点,我们需要重点关注的是其中的 handlers 部分。不过要注意,Try 结构包含其他一些变化形式,比如:
- 同时捕获多个异常类型,如
except (ValueError, KeyError) - 不指定具体类型,只包含一个简单的
except
上述变体在结构上也是有所差别的。为保证代码足够健壮,我们也应该在单元测试中包含各种可能的场景,保证代码在所有边界情况下都能正常执行。
相信大家已经熟悉这个步骤,我们可以稍稍加快一点节奏,一次编写两个测试,分别针对没有异常处理、以及基本的异常处理代码:
class ExceptionTypeVisitorTest(TestCase, VisitorTestMixin):
visitor_type = ExceptionTypeVisitor
def test_no_handler(self):
code = """print('hello')""".strip()
self.run_visitor(code, xml_filename='exception-no-handler.xml')
self.assert_no_issue()
def test_handler_generic(self):
code = """
try:
calc()
except Exception as e:
print(e)
""".strip()
self.run_visitor(code, xml_filename='exception-catch-generic.xml')
self.assert_found_issue(3, 'W0002')
我们已经知道异常代码的 AST 结构,实现起来毫无难度:
class ExceptionTypeVisitor(BaseVisitor):
def visit_ExceptHandler(self, node: ast.ExceptHandler):
exp_type = node.type
if isinstance(exp_type, ast.Name) and exp_type.id == 'Exception':
self.ctx.add_issue(node, 'W0002', f'Avoid catch generic Exception.')
self.generic_visit(node)
但是,再增加一个针对边界情况的用例,就会发现上述实现还不够完善:
def test_catch_multiple_types_with_issue(self):
code = """
try:
calc()
except (Exception, ValueError) as e:
print(e)
""".strip()
self.run_visitor(code, xml_filename='exception-catch-multi-with-issue.xml')
self.assert_found_issue(3, 'W0002')
我们应该根据输出的 XML 文件来验证一下。在同时匹配多个异常的情况下,ExceptionHandler 的 type 部分是一个 tuple,其中包括所有要捕获的异常类型。为了避免重写所有代码,让我们编写一个辅助函数,统一将异常类型作为集合返回,这样访问异常节点的代码主体可以保持不变:
class ExceptionTypeVisitor(BaseVisitor):
AVOID_TYPES = ('Exception', 'BaseException')
def iter_exception_types(self, node: ast.AST):
if isinstance(node, ast.Name):
yield node
elif isinstance(node, ast.Tuple):
for name_node in node.elts:
if isinstance(name_node, ast.Name):
yield name_node
def visit_ExceptHandler(self, node: ast.ExceptHandler):
for name_node in self.iter_exception_types(node.type):
if name_node.id in self.AVOID_TYPES:
self.ctx.add_issue(name_node, 'W0002', f'Avoid catch generic Exception.')
self.generic_visit(node)
这样测试又可以正常通过了。
最后是无异常类型的检查:
def test_catch_no_type(self):
code = """
try:
calc()
except:
print(e)
""".strip()
self.run_visitor(code, xml_filename='exception-catch-no-type.xml')
self.assert_found_issue(3, 'W0002')
这种情况下,用分析工具可以看到 AST 的 type 节点为 None。因此我们只需要简单增加一个检查即可:
def visit_ExceptHandler(self, node: ast.ExceptHandler):
if not node.type:
self.ctx.add_issue(node, 'W0002', f'Please specify exception type to catch.')
# ... origin code
变量使用检查
声明过的变量从未被使用,是程序中非常常见且值得关注的一类问题。出现这类问题可能是因为开发者修改了实现、但未能清理原有代码,也可能纯粹是开发者打错了字。在 Python 中这类问题尤其值得关注,因为没有编译器来捕获这类错误(单元测试当然也是一个途径,但不在本文讨论范围之内)。接下来我们考虑如何用静态分析来发现这种问题。
用辅助工具来检查代码对应的 AST,我们会发现:变量无论是声明还是引用,都会表示为 Name 节点。区别在于,在 Python 中并没有单独的变量声明,而是赋值就自动生成变量,它对应到语法树的 Assign 节点。Assign 之外的 Name 都可以视为引用。
我们还是编写测试,来检查在变量被使用和未被引用的情况下,程序是否能正确检查到问题:
class VariableUsageVisitorTest(TestCase, VisitorTestMixin):
visitor_type = VariableUsageVisitor
def test_vars_all_used(self):
code = """
def fn():
name = 'user'
print(name)
""".strip()
self.run_visitor(code, xml_filename='var-used.xml')
self.assert_no_issue()
def test_vars_not_used(self):
code = """
def fn():
name = 'user'
print('hello')
""".strip()
self.run_visitor(code, xml_filename='vars-unused.xml')
self.assert_found_issue(2, 'W0003')
表面看起来,实现这个要求并不复杂,只要看 Name 节点是否出现在 Assign 内部就行了。但实际上,我们需要考虑作用域的问题:函数内部变量和全局变量(实际上应该是模块级变量)是不一样的。在 Python 中,函数还可以嵌套定义,这让问题进一步复杂化了。
还是首先编写测试。我们需要验证,在没有定义变量、定义并使用、或者定义但未使用等场景下,程序能检查到预期的问题:
class VariableUsageVisitorTest(TestCase, VisitorTestMixin):
visitor_type = VariableUsageVisitor
def test_no_func(self):
code = """print('hello')""".strip()
self.run_visitor(code, xml_filename='var-no-func.xml')
self.assert_no_issue()
def test_global_vars_used(self):
code = """
name = 'user'
print(name)
""".strip()
self.run_visitor(code, xml_filename='global-vars-used.xml')
self.assert_no_issue()
def test_global_vars_unused(self):
code = """
name = 'user'
print('hello')
""".strip()
self.run_visitor(code, xml_filename='global-vars-unused.xml')
self.assert_found_issue(1, 'W0003')
实现部分有些复杂,所以我们分步讲解。为了记录哪些变量被定义/引用,我们需要增加额外的成员变量,此外还要记录当前是否在赋值(Assign)作用范围内,以判断是否变量定义。
细心的同学会发现声明/使用两个集合的定义是不对称的。当发现未使用的变量时,我们需要输出其原始位置,但多次赋值(AST节点不同)应视为同一变量,所以记录为 {var_name: node} 的形式。而哪些变量被使用只要知道变量名即可,所以可以定义为 set。
class VariableUsageVisitor(BaseVisitor):
def __init__(self, ctx: AnalysisContext):
super().__init__(ctx)
self.in_assign = False
self.declare_vars = {}
self.used_vars = set()
def visit_Assign(self, node: ast.Assign):
self.in_assign = True
self.generic_visit(node)
self.in_assign = False
当访问到 Name 节点时,根据是否赋值记录其用途:
def visit_Name(self, node: ast.Name):
var_name = node.id
if self.in_assign:
self.declare_vars[var_name] = node
else:
self.used_vars.add(var_name)
最后,当访问完毕后,将定义/引用的变量列表转换成 set 进行集合运算,其差就是那些未被引用的变量:
def visit_Module(self, node: ast.Module):
self.generic_visit(node)
unused_vars = set(self.declare_vars) - self.used_vars
for var_name in unused_vars:
node = self.declare_vars[var_name]
self.ctx.add_issue(node, 'W0003', f"Variable '{var_name}' declared but never used")
到此,我们实现了对变量使用情况的基本检查逻辑,但还没有考虑到的一个问题是作用域。再编写一个测试:
def test_nested_funcs(self):
code = """
def outer():
def inner():
name = 'inner'
print('hello')
name = 'outer'
print(name)
""".strip()
self.run_visitor(code, xml_filename='vars-nested-func.xml')
self.assert_found_issue(3, 'W0003')
该代码中有两个 name 变量,它们从属于不同的作用域,第一个变量是没有被使用的。我们目前的实现无法检查出这个问题,因为它会把两个 name 当作同一个。为解决此问题,我们还有对原代码做比较大的修改。
所谓变量的作用域,从本质上来说也是一棵树,但是在访问时它的表现更像一个堆栈:进入函数(或类)定义是“入栈”,从函数返回是“出栈”。栈上的每一项都应该记录哪些变量在该范围内被使用,而不是使用全局数据结构。因此,我们先要把记录变量信息的记录提取出来作为一个数据结构,我把它命名为 VariableScope。它基本上就是把前面代码中对 declare_vars 和 used_vars 相关的处理集中起来,计算方法完全相同,这里也不再列出了,读者可以阅读源码。
VariableUsageVisitor 的实现也需要做比较大的修改。我们在其构造函数中增加一个列表,用来记录作用域的堆栈:
class VariableUsageVisitor(BaseVisitor):
def __init__(self, ctx: AnalysisContext):
super().__init__(ctx)
self.in_assign = False
self.scope_stack = []
当进入一个新的作用域时,我们将该节点压入堆栈,调用完毕后弹出,并检查变量的使用情况:
def visit(self, node: ast.AST):
is_scope_ast = isinstance(node,
(ast.Module, ast.FunctionDef, ast.ClassDef))
if is_scope_ast:
scope = VariableScope(node)
self.scope_stack.append(scope)
super().visit(node)
if is_scope_ast:
self.scope_stack.remove(scope)
scope.check(self.ctx)
最后,在访问 Name 节点时,我们把它记录在当前作用域(也就是堆栈的最顶层一项)中:
def visit_Name(self, node: ast.Name):
if self.scope_stack:
scope = self.scope_stack[-1]
scope.use(node, self.in_assign)
self.generic_visit(node)
完成这些修改之后,对于嵌套定义的测试用例也可以正确通过了。
需要说明的是,对于作用域问题,我们还是做了一些简化。特别是 Python 中有一些特殊语句,比如 global/nonlocal 等,它们会改变变量的查找逻辑,而我们并未考虑如何去处理这些规则。考虑到我们实现的是一个不到 500 行的演示程序,这样的缺点也还是可以接受的。
语序问题检查
Python 以简洁易懂而著称,也特别重视语句是否直观、自然。比如,以下两种写法在逻辑上是等效的,但 PEP8 明确指出:应该尽可能地使用第一种写法。
# Correct
if foo is not None: pass
# Wrong
if not foo is None: pass
为了检查类似这样的问题,我们还是用辅助工具观察一下它的 AST 是什么结构。结果大概如下:
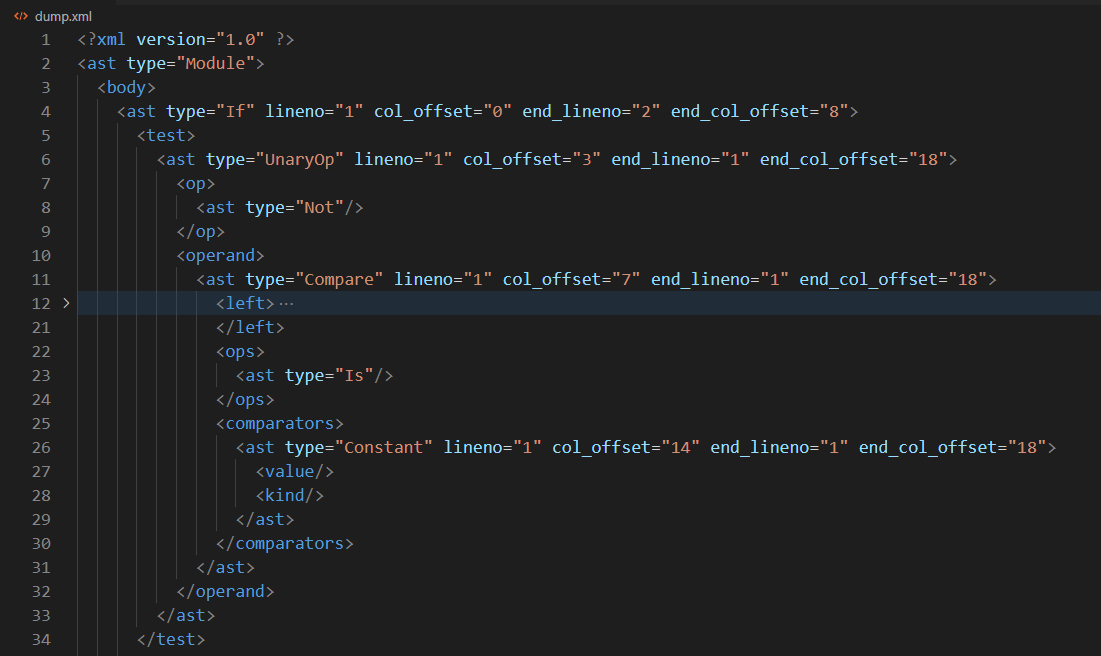
其中重点是 Not 和 Is 两个关键元素出现的位置。
了解完结构,按照规则还是先写单元测试:
class PreferIsNotVisitorTest(TestCase, VisitorTestMixin):
visitor_type = PreferIsNotVisitor
def test_is_not(self):
code = """
if a is not None:
print(a)
""".strip()
self.run_visitor(code, xml_filename='is-not.xml')
self.assert_no_issue()
def test_not_is(self):
code = """
if not a is None:
print(a)
""".strip()
self.run_visitor(code, xml_filename='not-is.xml')
self.assert_found_issue(1, 'W0004')
因为语法结构是固定的,所以不再需要遍历,只考虑目标节点即可。以下实现非常直接,但因为做了很多类型检查,所以显得有点繁冗。经验告诉我们,对于 AST 这种变化多端的结构,检查太多总好过太少。当然读者可以有不同的见解。
class PreferIsNotVisitor(BaseVisitor):
def visit_If(self, node: ast.If):
if isinstance(node.test, ast.UnaryOp) and \
isinstance(node.test.op, ast.Not):
operand = node.test.operand
if isinstance(operand, ast.Compare) and \
len(operand.ops) == 1 and \
isinstance(operand.ops[0], ast.Is):
self.ctx.add_issue(node, 'W0004', 'Use if ... is not instead')
self.generic_visit(node)
这次的目标非常简单,也没有其他变化,所以这样的实现就足以通过测试了。
汇总
完成以上四种问题的检查,我们把它们合成一个完整的静态分析工具。这一步就很轻松了。
class CodeAnalyzer:
def visitors(self, ctx: AnalysisContext):
yield LineLengthVisitor(ctx)
yield ExceptionTypeVisitor(ctx)
yield VariableUsageVisitor(ctx)
yield PreferIsNotVisitor(ctx)
def analysis(self, filename: str, code: str):
self.ctx = AnalysisContext(filename)
ast_root = ast.parse(code)
for visitor in self.visitors(self.ctx):
visitor.visit(ast_root)
def print(self):
for issue in self.ctx.issues:
print(issue)
if __name__ == '__main__':
analyzer = CodeAnalyzer()
analyzer.analysis('test.py', CODE)
analyzer.print()
CodeAnalyzer 使用所有支持的 NodeVisitor 来访问程序,并记录检查结果。如果以后实现了新的 visitor,只要简单地把它加入 visitors 集合即可。
总结
本文以四种典型的代码问题为例,演示了静态分析工具是如何通过遍历代码 AST 去查找问题的。相信读者在阅读本文后,举一反三,能够检测更多其他问题,或者从各个方面去完善上述程序。
但是在实现此程序的过程中,我们也意识到,Python 的 ast 模块是有一些限制的。尤其是它不包含空格、换行、注释等貌似冗余的信息,但这就使得部分代码风格的分析变得困难。与此同时,现实的静态分析工具很多时候要使用某种特殊格式的注释去调整静态分析的行为,而去掉了注释使得这种调整变得不可能。当然,从理论上讲,我们可以根据位置信息和源码的文本反推来获得一些额外的信息,但这显然是不合理的。由于 ast 模块主要是为执行程序而设计的,为了保证速度,在信息的完整性上的确有所欠缺。如果有更高级的要求,我们可以考虑采用其他第三方的实现,比如说,著名的静态检测工具 pylint 就附带了一个更加完整的 AST 分析库:astroid,有兴趣的同学可以去了解。
另一个问题是,本文所实现的各种 visitor 都是针对单个问题而实现的。这种设计固然让类的功能专一而内聚,但对于每种可能的问题都对整个 AST 执行遍历,显然容易引起性能上的问题。对于生产级别的工具而言,我们可能需要考虑把一些逻辑上类似或有关联的 Visitor 合并起来,让它能够通过单次遍历找到多个代码问题。当然,这也要我们首先编写出一定数量的 visitor,然后才能看到其中的规律。
如果读者觉得本文的实现还不够深入的话,也可以去参考真正具有现实价值的项目,包括本文开头部分曾经提到过的各种广泛使用的静态分析工具。好消息是,它们几乎都是开源的。即便读者并不打算自己去实现一个,相信通过本文也可以体会到:编写静态分析工具在原理上不见得有多复杂,主要难点在于实现上的繁琐,以及正确处理各种语法的变体。也能够体会到,在貌似简单的背后,各种编译器和开发辅助工具实际上完成了大量困难的工作,为开发者的日常工作带来了便利。我们应该深深感谢开发出这些工具的前辈们。
文章索引
- 重写 500 Lines or Less 项目 - 前言
- 重写 500 Lines or Less 项目 - Web Server
- 重写 500 Lines or Less 项目 - Template Engine
- 重写 500 Lines or Less 项目 - Continuous Integration
- 重写 500 Lines or Less 项目 - Static Analysis
概述
本文章是 重写 500 Lines or Less 系列的其中一篇,目标是重写 500 Lines or Less 系列的原有项目:A Python Interpreter Written in Python。
在原文中,作者(Allison Kaptur)首先通过自己设计并实现的几种教学指令,来说明 Python 解释器的工作原理。该指令系统与真正的 Python 字节码在原理上类似,但在具体指令上有很大差别。随后,作者介绍了自己实现的、用 Python 实现的 byterun 解释器,这是一个较为复杂、但可以用来执行许多 Python 程序的真正可用的解释器。
我认为作者在前半部分对于解释器工作原理部分的讲解还是相当清楚的。但该文和和系列的其他文章存在相似的问题,即:后半部分开始大段罗列代码。如果读者像我一样,对 Python 字节码有大概的了解但并不深入,那么阅读前半部分应该没什么困难,但后面的实现就涉及到各个指令的细节,这就有相当的难度了,而作者的讲解显然不是很充分。另一方面,我们只能看到一个最终的实现,无法得知一个解释器是如何从头编写出来的,也看不到作者思考和重构的过程。这样阅读收益就比较有限了。
在本文中,我试图针对同样的主题,用测试驱动开发(TDD)的思路从头开始编写代码。我希望:本文的例子既不要像原文的教学解释器那样简单(这样在真正实现解释器的时候就需要从头来过),也不要像完整的 byterun 程序那样复杂。因此,我希望走一条“中间路线”,即:一开始就以真正的 Python 字节码为实现目标,但只实现一些比较常见和基础性的语法构造,目的是为了说明基本原理,而不是试图实现一个完整的解释器。
在程序编写过程中,随着需求的增加和变化,代码也会经历几次较大规模(相对本应用而言)的重构。我希望读者能从重构的过程理解到,现实的程序并不需要在一开始就把所有细节想清楚,也没有必要花费太多时间去设计一个完美的架构;好的程序总是在不断的重构过程中“浮现”出来的。
文章结构
本文按照如下步骤依次开发:
- 基本原理和工具
以 Python 内置的 dis 模块为工具,理解 Python 字节码是什么、解释器是如何工作的,为后续实现打下基础;
- 实现加法
以基础的算数运算为例,实现最初的解释器版本,初步建立起程序的整体结构;
-
函数调用 在上一步的基础上实现调用 Python 内部函数的功能,以扩展解释器的应用范围;
-
分支判断
以 if 语句为例,实现分支和跳转指令。该步骤需要对解释器的执行过程进行重构;
- 自定义函数
实现对用户定义函数的处理和调用过程。这是一个相当大的变化,因此我也会仔细说明重构的过程;
- 列表解析
实现对列表解析(List Comprehension)语法构造的支持。在已经实现了前面步骤的基础,这一步会相对简单,但是能帮助我们理解 Python 在幕后是如何支持这些有趣的语法构造的。
以上每个步骤都增加了对一些常见的 Python 语法结构的支持。经过这些步骤以后,我们实现的解释器已经可以用来运行一些比较简单的程序了。当然,还有一些更为复杂的内容,比如异常、类定义、生成器等高级语法构造并未包含在内。要在 500 行内完成这个目标是不太现实的,我们去阅读原文的 byterun 代码会发现,它的长度也早已超过了这个限制。不过,一旦读者理解基本语法是如何构造出来的,后面只要理解各个指令的细节,在原有基础上继续扩展即可,从理论上并没有太大问题了。
示例代码
本文及系列文章的所有代码都开源在 Github 仓库:500lines-rewrite。本文相关的代码位于 intercepter 目录,在其下为每个阶段创建了单独的子目录。为了避免为每个步骤创建单独的环境,读者可以将主目录下的 main.py 作为入口,并打开相应的引用部分来运行程序。
接下来,我们首先要搞清楚 Python 字节码是怎么、它是怎么运行起来的,以及我们该如何去解析它的内容。
理解 Python 字节码
尽管在传统上 Python 往往被称为解释性语言(与编译性语言相对),但从工作原理上讲,Python 其实和 Java、C# 更为相近,当你运行 Python 程序的时候,它会首先把源码编译为二进制形式的内部形式,也就是字节码(Bytecode)。这样有利于提高程序的执行速度,也可以免去运行时重复解析的开销。不过和 Java/C# 比较起来,Python 字节码更为简单、指令也比较抽象,它把更多的工作交给解释器在运行期间完成。这样设计的好处是:程序可以有更多的运行期灵活性(这是动态语言的显著特点),也使得 Python 执行内部编译的过程快到让程序员和用户几乎感觉不到。当然,凡事都有代价。Python 字节码为灵活性付出的代价就是:它必须在运行期执行更多检查,因此和多数传统的编译性语言比起来,它的执行效率并不算高。等实现这个解释器以后,我们对上述特点会有更加清楚的认识。
经典书籍《Python 学习手册》中有这样一张插图,可以帮助我们理解 Python 程序的执行过程:

因为编译到字节码的功能已经内置在 Python 之中,想要看到它是非常容易的。比如说,当我们定义一个函数时,它会在幕后自动被转换成字节码。用类型化的术语来说:字节码就是一个带有执行信息的code 对象,其 co_code 属性的内容就是字节码。当然,如果不用特殊工具去解析的话,我们看到的只是一串不明所以的二进制数据:
>>> def f(): return 1
...
>>> f.__code__
<code object f at 0x00000171E2253F50, file "<stdin>", line 1>
>>> f.__code__.co_code
b'd\x01S\x00'
那么如何去理解字节码的内容?其实 Python 已经为我们提供了必要的工具,这就是内置模块 dis,它可以把二进制的字节码整理成容易阅读的文本形式。一下是用来显示字节码内容的一个小的示例程序:
import dis
def main():
print("====dis code====")
source = "n = a + 1"
code = compile(source, filename='', mode='exec')
print('co_names:', code.co_names)
print('co_consts:', code.co_consts)
print('co_code', code.co_code)
dis.dis(code)
print("====instructions====")
for instruction in dis.get_instructions(code):
print(instruction.opcode, instruction.opname, instruction.arg, instruction.offset)
运行程序,会看到类似这样的输出:
====dis code====
co_names: ('a', 'n')
co_consts: (1, None)
co_code b'e\x00d\x00\x17\x00Z\x01d\x01S\x00'
1 0 LOAD_NAME 0 (a)
2 LOAD_CONST 0 (1)
4 BINARY_ADD
6 STORE_NAME 1 (n)
8 LOAD_CONST 1 (None)
10 RETURN_VALUE
====instructions====
101 LOAD_NAME 0 0
100 LOAD_CONST 0 2
23 BINARY_ADD None 4
90 STORE_NAME 1 6
100 LOAD_CONST 1 8
83 RETURN_VALUE None 10
如果读者对 CPU 执行指令的过程有所了解的话,那么 Python 字节码的原理也是类似的。它带有一系列指令(instruction),某些指令需要额外的参数,也有些指令不需要参数。除了指令之外,字节码的执行还需要其他一些信息,包括运行所需的常量、变量名称等等,这些附属信息记录在 co_names 和 co_consts 等属性中。
dis 以列表的形式显示字节码指令,不过它的格式需要一点时间来熟悉。一般来说,这个列表会有 5 列,从左到右,它们的内容包括:
- 对应源码的行号
- 指令在整个字节码中的偏移量
- 指令名称
- 指令的参数(如果有的话)
- 对指令参数的含义进行补充说明,以便于理解。比如上面字节码的第一条指令
LOAD_NAME参数为 0, 表示需要取co_names[0]也就是变量 a 的内容作为值。
后面我们会看到,如果字节码包含跳转指令的话,那么在跳转的目标地址前面还会显示一个 >> 符号,方便我们查找。
对这个简单的代码而言,即便读者对字节码指令一无所知,和源码对照着看,也不难猜到各个指令的含义:
| 指令 | 含义 |
|---|---|
| LOAD_NAME(0) | 取 co_names[0],也就是变量 a 的值 |
| LOAD_CONST(0) | 取 co_consts[0],也就是常量 1 |
| BINARY_ADD | 执行加法 |
| STORE_NAME(1) | 将结果记录到 co_names[1] 对应的变量,也就是 n |
| LOAD_CONST(1) | 取 co_consts[1],也就是常量 None |
| RETURN_VALUE | 返回值 |
现在我们能够大概知道这些指令做了什么,但具体是怎么做的,仍然存在模糊之处。比如说,LOAD_NAME 指令是从 co_names 取变量值,但取出以后放到哪里?BINARY_ADD 指令没有参数,它又怎么知道到底要加什么?
答案是:Python 解释器是一个基于堆栈(Stack)的工作模型。许多指令都是从堆栈中获取需要的参数,并且执行的结果通常也要再次推到堆栈中。通常,这些指令也会对堆栈的状态做出一定的假设,比如 BINARY_OP 指令就假定在它执行的时候,需要的两个操作数都已经在栈上,所以就不要额外的参数了。
知道原理以后,上述字节码就很好理解了。我们从堆栈的角度再次推演这个过程:
LOAD_NAME取出一个变量,并压入堆栈;LOAD_CONST取出一个常量,也压入堆栈;- 现在堆栈上有两个值,
BINARY_ADD指令从栈上弹出两个参数,执行加法计算,把结果再次压入堆栈; STORE_NAME从堆栈上取得计算结果,并保存到变量 n。- 字节码的最后一个指令通常都是
RETURN_VALUE。但我们目前还没有涉及到函数调用,模块级别的返回值并不重要,因此可以暂时忽略它。
有了以上知识,可以开始着手实现解释器了。
基本运算
我们从最简单的情况开始入手,先实现基本的算术运算场景。按照 TDD 的原则,首先写一个失败的单元测试,来表达我们预期的场景:
import unittest
from .interpreter import Interpreter
class InterpreterTest(unittest.TestCase):
def test_add(self):
source = "n = a + 1"
interpreter = Interpreter(source)
interpreter.set_local('a', 2)
interpreter.exec()
self.assertEqual(3, interpreter.get_local('n'))
为了满足该测试,运用前面学到的知识,我们需要:
- 用
dis模块将代码翻译成指令 - 将执行所需的常量和变量等注入执行环境
- 依次执行各条指令
前两条很容易实现。这里直接给出代码:
import dis
class Interpreter:
def __init__(self, source):
self._code = compile(source, filename='', mode='exec')
self._locals = {}
def get_local(self, name):
return self._locals[name]
def set_local(self, name, value):
self._locals[name] = value
def get_const(self, consti):
return self._code.co_consts[consti]
那么如何执行指令?我们已经了解到,Python 解释器本质上是一个基于堆栈(Stack)的虚拟机,绝大部分指令都涉及压栈(push)或出栈(pop)的动作。因此,我们先引入堆栈和辅助方法:
class Interpreter:
def __init__(self, source):
...
self._stack = []
def stack_push(self, value):
self._stack.append(value)
def stack_pop(self):
return self._stack.pop(-1)
接下来要实现执行指令的操作。本代码使用一个简单的映射关系,把指令名称对应到成员函数。当然这不是很高效的做法,但对于教学目的而言是最简单明了的:
def exec(self):
for instruction in dis.get_instructions(self._code):
fn = getattr(self, 'exec_' + instruction.opname)
fn(instruction.arg)
def exec_LOAD_NAME(self, namei):
...
我们如何知道各条指令的处理规则是什么呢?这就要阅读文档了。dis 模块文档 的字节码部分列出了解释器支持的所有指令、以及它们各自的执行细节。在我们实现解释器的时候,该文档是最权威的参考资料。
通读一下文档就会发现,所有字节码指令要么没有参数(比如 BINARY_ADD/RETURN_VALUE),要么只有一个参数(如 LOAD_CONST/LOAD_NAME)。为了避免检查每个指令是否支持参数的麻烦,代码统一规定:所有实现函数都带有一个参数,对于不需要参数的指令,可以把参数命名为 _(要丢弃的变量标记为 _,这是一个没有公共规则、但在各种语言中广为采用的惯例)。
此外需要说明的一点是,如果你是第一次去看该文档,那么其中某些术语可能会让你摸不着头脑。比如在很多地方频繁出现的 TOS 并未给出一个明确的解释。实际上,TOS 表示栈顶数据(Top Of Stack),对应代码也就是 stack[-1]。TOS1,TOS2 等表示栈再往下的数据,也就是 stack[-2], stack[-3],依次类推。
举个例子。文档中对于指令 LOAD_NAME 是这样描述的:
LOAD_NAME(namei)
Pushes the value associated with co_names[namei] onto the stack.
这是个非常简单的指令。但在实现时需要注意,co_names 记录的只是变量名称,我们取到名称之后,还要到局部变量里去查找它的具体值,因此需要两步才能拿到真正的数据:
def exec_LOAD_NAME(self, namei):
name = self.get_name(namei)
value = self.get_local(name)
self.stack_push(value)
BINARY_ADD 则需要从栈上弹出两个操作数,相加后再次放到栈上:
def exec_BINARY_ADD(self, _):
tos = self.stack_pop()
tos1 = self.stack_pop()
result = tos1 + tos
self.stack_push(result)
从代码看来,为了实现计算需要频繁执行入栈/出栈的操作,看起来似乎效率不高。实际上,真正的解释器往往是用低级语言(C/C++)实现的,在这些实现中出栈只需要移动栈指针即可,速度是非常快的。
其他指令比如 LOAD_CONST、STORE_NAME 等都可以按照文档去实现,这里不再一一列举了,大家可以参考代码。唯一有点问题的是 RETURN_VALUE,按照文档说明,它的作用是向调用函数返回值。目前我们还没有涉及到函数调用,所以留空即可,不影响测试:
def exec_RETURN_VALUE(self, _):
pass
第一个测试现在可以正常通过了。如果大家去看代码的话,会发现我还添加了两个辅助方法,分别用来输出字节码内容和运行时堆栈:
def dump_code(self):
print(f"====dis code of {self._code.co_name}====")
print('co_names:', self._code.co_names)
print('co_consts:', self._code.co_consts)
print('co_code', self._code.co_code)
print('co_varnames', self._code.co_varnames)
dis.dis(self._code)
def dump_stack(self, instruction):
print(f'Stack after {instruction.opname}({instruction.offset}): {self._stack}')
这些辅助方法对于实现功能来说并无帮助。但是,相信大家可以理解,在我们编写代码的时候难免会引入一些 bug(特别是对于字节码还不太熟悉的情况下),且 Python 解释器是基于栈的模型,如果堆栈操作有错误的话,可能后面的执行就彻底乱套了。因此,我们一方面用单元测试来保证每个步骤都被正确实现,才进入下一个环节;另一方面,如果出现错误的话,我们可以使用这些辅助方法来详细观察程序执行情况,了解问题到底出在哪一步。
调用函数
现在我们有了一个基本的解释器实现,在它的基础上进行扩展,就可以支持更多指令了。下一个目标也是常见的操作:调用内置函数并获得返回值。
在编写本文时,最初我想用 print() 这个最为常见的函数作为例子,但很快发现,print() 涉及外部 IO 问题,有点过于复杂,且比较难以验证它的调用是否正常。因此,我转而使用容易验证的数学函数,比如 divmod。
还是用 TDD 的方法,开始编写下一个测试用例,但我们会意识到:测试代码已经开始出现重复了。这是因为基本上所有测试都使用同样的模式:输入代码和变量,执行解释器,然后检查结果。为了简化后续测试的编写,现在可以稍微做一下重构,提取出通用的部分:
class InterpreterTest(unittest.TestCase):
def exec_interpreter(self, source, local_vars=None, dump_code=False, trace_stack=False):
interpreter = Interpreter(source,
local_vars=local_vars,
dump_code=dump_code, trace_stack=trace_stack)
interpreter.exec()
return interpreter
def test_add(self):
...
def test_call_func(self):
source = "n = divmod(a, 2)"
interpreter = self.exec_interpreter(source, {'a': 11}, False, False)
self.assertEqual((5, 1), interpreter.get_local('n'))
现在去执行测试当然是失败的。我们可以把调用 exec_interpreter() 部分的参数改为 True,观察字节码是什么样的:
====dis code of <module>====
co_names: ('divmod', 'a', 'n')
co_consts: (2, None)
co_code b'e\x00e\x01d\x00\x83\x02Z\x02d\x01S\x00'
co_varnames ()
1 0 LOAD_NAME 0 (divmod)
2 LOAD_NAME 1 (a)
4 LOAD_CONST 0 (2)
6 CALL_FUNCTION 2
8 STORE_NAME 2 (n)
10 LOAD_CONST 1 (None)
12 RETURN_VALUE
这个字节码也不算复杂,唯一一条新的指令是 CALL_FUNCTION。参考文档,我们知道它需要从堆栈上弹出调用参数(指令的参数就是需要弹出的参数数量),此外还要弹出调用的函数本身。调用结果也会压入堆栈,随后被 STORE_NAME 指令取出。
搞清楚了 CALL_FUNCTION 指令的含义,但是且别忙着动手实现,我们还有一个问题要解决:字节码的 co_names 只记录了 divmod 函数的名称,我们该到哪去找到函数本体?
实际上,divmod 是一个内置函数,Python 会把它记录在 builtins 中。Python 有一套查找变量的规则,如果目标名称在局部变量和全局变量中都找不到的话,那么 Python 会到 builtins 中去找它。我们可以用如下代码来验证它的存在:
>>> import builtins
>>> getattr(builtins, 'divmod')
熟悉 Python 的朋友可能会知道,Python 还有一个特殊变量 __builtins__,它本质上和 builtins 模块是一样的。但按照官方说明,__builtins__ 属于“实现细节”,也就是说如果不是要去修改 Python 的话,普通应用是不应该使用这个变量的。
理解了上述规则,我们可以把代码修改如下:
import builtins
class Interpreter:
def __init__(self, source, local_vars=None, dump_code=False, trace_stack=False):
...
self._builtins = {x: getattr(builtins, x) for x in dir(builtins) if not x.startswith('__')}
def exec_LOAD_NAME(self, namei):
name = self.get_name(namei)
if name in self._locals:
value = self.get_local(name)
elif name in self._builtins:
value = self._builtins[name]
else:
raise NameError(name)
self.stack_push(value)
上述代码实现其实还不是非常完善,因为它没有考虑全局(global)作用域的问题。不过目前我们的测试还不涉及这一点。感兴趣的同学可以作为自己的练习。
然后实现 CALL_FUNCTION 指令。按照文档,它要从栈中弹出所有位置参数(指令的参数就是要弹出的数量)。需要注意的是弹出顺序,栈顶对应最右边的参数,最后弹出参数本身。
def stack_popn(self, count):
if count > 0:
result = self._stack[-count:]
self._stack = self._stack[:-count]
return result
return []
def exec_CALL_FUNCTION(self, argc):
args = self.stack_popn(argc)
func = self._stack.pop(-1)
result = func(*args)
self.stack_push(result)
这里把 “从堆栈弹出 n 个值” 的操作提取成了辅助方法,这是因为在阅读文档的时候我注意到,还有其他指令也会用到这个操作。因为堆栈的存储结构正好和参数顺序是匹配的,获取切片(slice)即可,无需再循环取值了。
需要说明的是,Python 存在多种绑定参数值的方式,包括按位置绑定、可变参数、命名参数、默认值等,为了支持所有这些绑定方式,函数调用的实现其实是相当复杂的。体现在字节码上,除了这里实现的 CALL_FUNCTION 之外,还有更为复杂的 CALL_FUNCTION_KW 和 CALL_FUNCTION_EX 等指令。不过如果把它们都加进来的话,会把这个部分变得过于冗长。所以我们到此为止,如果读者有兴趣的话,可以自己去尝试实现对于其他调用指令的支持。
实现 if 分支
我们知道,要实现复杂的程序,要用到顺序、分支和循环三种结构。到现在我们实现的字节码都是从头到尾顺序执行的。这只适用于非常简单的程序。从字节码角度看,分支(如 if 语句)和循环(for, while)本质上是类似的,它们都是通过有条件/无条件跳转指令实现的。我们以 if 语句为例,看看如何支持这些需要跳转的字节码。
还是先编写测试代码:
def test_if(self):
source = """
if a > 10:
b = True
else:
b = False
""".strip()
interpreter = self.exec_interpreter(source, {'a': 11}, True, True)
self.assertEqual(True, interpreter.get_local('b'))
interpreter = self.exec_interpreter(source, {'a': 3}, False, False)
self.assertEqual(False, interpreter.get_local('b'))
测试失败。输出对应的字节码:
co_names: ('a', 'b')
co_consts: (10, True, False, None)
co_code b'e\x00d\x00k\x04r\x0ed\x01Z\x01n\x04d\x02Z\x01d\x03S\x00'
1 0 LOAD_NAME 0 (a)
2 LOAD_CONST 0 (10)
4 COMPARE_OP 4 (>)
6 POP_JUMP_IF_FALSE 14
2 8 LOAD_CONST 1 (True)
10 STORE_NAME 1 (b)
12 JUMP_FORWARD 4 (to 18)
4 >> 14 LOAD_CONST 2 (False)
16 STORE_NAME 1 (b)
>> 18 LOAD_CONST 3 (None)
20 RETURN_VALUE```
这里出现了多条新的指令,我们来各个理解它们。
COMPARE_OP
很明显,这是用来执行比较的。它从堆栈上弹出两个值来进行比较,比较结果也会压入堆栈中。但参数 4 表示什么意思?其实这是用来支持不同的比较方法的。所有比较方法可以在 dis.cmp_op 中找到:
>>> dis.cmp_op
('<', '<=', '==', '!=', '>', '>=', 'in', 'not in', 'is', 'is not', 'exception match', 'BAD')
可见,上述代码执行的是 dis.cmp_op[4],也就是 > 比较。其他比较操作的含义大多是非常明显的,只有最后两个用于异常,目前我们先不管它。
POP_JUMP_IF_FALSE
跳转指令来了。POP_JUMP_IF_FALSE 从堆栈上弹出一个值,如果值为 False 的话就跳转到参数指定的地址(14),否则继续往下执行。在真正的解释器(如 CPython)中可以直接把指针指向偏移量位置,因此执行速度很快,而基于 Python 的实现需要从偏移量反查对应的指令,可想而知性能不会很高。当然,想要优化也是有办法的,不过我们这个代码目的是为了理解工作机制,希望保持简洁和清晰,不会特意去优化运行速度。
JUMP_FORWARD
这是一个无条件跳转指令。有一点可能会让人觉得有点迷惑:它的参数是跳转的偏移量,但并不是从当前指令开始计算,而是从下一条开始,需要注意不要算错了位置。不过所有基于偏移量的指令都遵循相同的规则,只要适应一下就好了。
了解上述三条指令,我们就能看懂上述字节码了:
- 从
POP_JUMP_IF_FALSE指令的地方开始代码分支,如果值为 True 则执行位置 8~12 部分的代码,否则执行 14~18 部分; - 8~12 部分执行完毕后,通过
JUMP_FORWARD指令跳转到最后; - 14~16 部分正常执行到最后。
为实现跳转,解释器部分必须进行较大的修改。首先,因为指令是可能随时跳转的,所以我们不能再依次迭代它们,而是需要预先解析出所有指令;其次,需要记录接下来要执行那一条指令。为了确定当前需要顺序执行还是跳转,我们再作一个约定:所有指令对应的方法如果返回 False(也包括什么都不返回)表示没有跳转,解释器继续往下执行;那些执行了跳转的指令则需要自行设置跳转目标并返回 True。这样约定的好处是:我们已经实现的那些方法可以继续使用,不需要做任何修改。
我们还做了一个改动,就是把结束执行的条件改为通过异常结束。这是因为我们现在必须把字节码当作可以任意跳转的,而不是按照顺序思维认定最后一条语句一定表示结束(尽管字节码的最后指令几乎总是 RETURN_VALUE)。
class ReturnValue(Exception):
pass
class Interpreter:
def __init__(self, source):
...
self._instructions = list(dis.get_instructions(self._code))
self._next_instruction = 0
def exec(self):
while True:
try:
instruction = self._instructions[self._next_instruction]
fn = getattr(self, 'exec_' + instruction.opname)
if not fn(instruction.arg):
self._next_instruction += 1
except ReturnValue:
break
def exec_RETURN_VALUE(self, _):
raise ReturnValue()
接着实现 COMPARE_OP:
def exec_COMPARE_OP(self, opname):
opname = dis.cmp_op[opname]
comparers = {
'<': lambda x, y: x < y,
'<=': lambda x, y: x <= y,
'==': lambda x, y: x == y,
'!=': lambda x, y: x != y,
'>': lambda x, y: x > y,
'>=': lambda x, y: x >= y,
'in': lambda x, y: x in y,
'not in': lambda x, y: x not in y,
'is': lambda x, y: x is y,
'is not': lambda x, y: x is not y,
}
comparer = comparers[opname]
rhs = self.stack_pop()
lhs = self.stack_pop()
result = comparer(lhs, rhs)
self.stack_push(result)
代码比较长,但只是因为要支持的操作符比较多,逻辑是相当简单的。
POP_JUMP_IF_FALSE 略微复杂,因为要处理字节码偏移量的问题。后面会看到,“按偏移量跳转”对于大多数跳转指令而言是常规操作,因此我们把它封装为辅助方法:
def exec_POP_JUMP_IF_FALSE(self, target):
value = self.stack_pop()
if not value:
self.jump_by_offset(target)
return True
return False
def jump_by_offset(self, offset):
index = [index for index, instruction in enumerate(self._instructions)
if instruction.offset == offset][0]
self._next_instruction = index
接着是 JUMP_FORWARD。无条件跳转的规则比较简单,需要注意的是偏移量计算以下一条指令为基准:
def exec_JUMP_FORWARD(self, delta):
offset = self._instructions[self._next_instruction + 1].offset + delta
self.jump_by_offset(offset)
return True
现在测试可以正常通过了。如果你回头看一下测试代码的话,会发现我们特地测试了在两种分支情况下返回结果都是正确的。
再看一下 COMPARE_OP 指令的实现,我们会更清楚地认识到本文开头提出的观点:Python 字节码的指令是相当高层的,它只说明了要执行比较操作,但并未说明具体是如何比较的。可想而知,大部分工作留给了运行时去解决。相比较而言,很多静态语言编译产生的代码会会直接绑定到实现,因此性能更高,但有时也显得缺乏灵活性。这是静态语言和动态语言的显著区别。
定义函数
接下来我们要做的可能是本文中难度最大的步骤:实现自定义函数。为此,解释器的实现需要做出相当大的修改,所以请打起精神来。
还是先写一个简单的测试用例:
def test_define_func(self):
source = """
def f(x):
return x + 1
n = f(a)
""".strip()
interpreter = self.exec_interpreter(source, {'a': 11}, True, True)
self.assertEqual(12, interpreter.get_local('n'))
测试失败。检查字节码:
====dis code of <module>====
co_names: ('f', 'a', 'n')
co_consts: (<code object f at 0x00000257F23D83A0, file "", line 1>, 'f', None)
co_code b'd\x00d\x01\x84\x00Z\x00e\x00e\x01\x83\x01Z\x02d\x02S\x00'
co_varnames: ()
1 0 LOAD_CONST 0 (<code object f at 0x00000257F23D83A0, file "", line 1>)
2 LOAD_CONST 1 ('f')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (f)
4 8 LOAD_NAME 0 (f)
10 LOAD_NAME 1 (a)
12 CALL_FUNCTION 1
14 STORE_NAME 2 (n)
16 LOAD_CONST 2 (None)
18 RETURN_VALUE
Disassembly of <code object f at 0x00000257F23D83A0, file "", line 1>:
2 0 LOAD_FAST 0 (x)
2 LOAD_CONST 1 (1)
4 BINARY_ADD
6 RETURN_VALUE
请仔细阅读,因为这个字节码比起我们迄今为止看到的都要复杂。最明显的是字节码分成了两个部分。我们现在对于字节码的了解已经足以推断,下面的部分就是函数 f,而上面部分则对应主体代码。我们还会发现函数 f 作为一个代码对象被添加到了主体代码的 co_consts 部分。通过标题(dis code of <module>)还可以推测,主体部分的代码是被解释器当作模块来执行的。
借此,我们可以进一步深化对于 Python 解释器的了解。对于 Python 运行时来说,每个函数(以及其他一些高层语法构造,比如模块、包)等等,都是一个独立的可执行对象,它们各自有自己的常量/变量以及作用域空间。在复杂的程序中,函数之间往往会形成非常复杂的调用关系。当进行函数调用时,幕后会发生这样一些动作:
- 函数创建一个运行时结构,在 Python 解释器的术语中称为“Frame”,表示一个独立的执行空间,有它自己的作用域、指令和堆栈;
- Frame 也是用一个类似堆栈的运行时结构来管理的。每次调用函数都会形成一个新的 Frame,并放到堆栈的顶部,执行完毕后从栈中清除;
- Frame 可以“看到”调用它的那个对象(可能是主模块,也可能是另一个函数)定义的数据,并且可以层层上溯直到全局变量(这就是 Python 查找变量的规则);
- 当 Frame 执行时,它所需要的参数从调用者空间拷贝到被调用者的执行空间(每个 Frame 有自己的执行堆栈);
- Frame 依次执行指令(以及跳转),一旦遇到 RETURN_VALUE 指令,则该 Frame 执行完毕,该 Frame 将会被清除,但返回值会传递给被调用者
- 被调用者从函数调用后的代码继续执行
如果你觉得这个过程听起来比较复杂的话,可以把解释器想象成一个讲谈节目。开始会有一个主持人(主模块)来主导节目的进行,但是他中间会让其他人来发言(调用函数),这就需要主持人需要把话筒和发言权让给发言者(接管指令执行)。发言者的话题结束后,需要把话筒返还给主持人(返回值)。更复杂的情况下,发言者还可以暂时把话筒让给其他人(嵌套调用)。当然,正常情况下是不应该出现出现某人请自己发言(递归调用)这种事情的......
现在我们对解释器的理解又加深了一层。还是回到代码。我们已经看到,dis 是模块能够发现并输出函数调用的,但美中不足的是,它不会自动输出除字节码之外的其他属性。为了看清楚自定义函数的字节码,我们把 dump_code 改为单独的递归方法,让它能够显示各个函数的具体细节:
def dump_recursive(code):
def dump(acode):
print(f"====dis code of {acode.co_name}====")
print('co_names:', acode.co_names)
print('co_consts:', acode.co_consts)
print('co_code', acode.co_code)
print('co_varnames:', acode.co_varnames)
dis.dis(acode, depth=0)
dump(code)
for item in code.co_consts:
if hasattr(item, 'co_code'):
dump_recursive(item)
现在可以看到自定义函数的属性:
====dis code of f====
co_names: ()
co_consts: (None, 1)
co_varnames: ('x',)
co_code b'|\x00d\x01\x17\x00S\x00'
2 0 LOAD_FAST 0 (x)
2 LOAD_CONST 1 (1)
4 BINARY_ADD
6 RETURN_VALUE
我们考虑如何实现这个要求。因为要为每个函数生成单独的 Frame,所以一个 Intercepter 类是不够用了。意识到这个重构会相当复杂,所以我选择后退一步,暂时屏蔽掉新添加的测试,先修改内部实现,同时保证原先的测试仍能够正常工作。
为此,我们创建一个新类:Frame,并把原来 Interpreter 中所有执行指令相关的代码都移动过来。另一个相关改动是,考虑到作用域问题,我们用 Python 数据结构中的 ChainMap 来管理局部变量,这个结构能很好地处理嵌套的作用域:
class Frame:
def __init__(self, interpreter, code, scope):
self._interpreter = interpreter
self._code = code
self._instructions = list(dis.get_instructions(self._code))
self._next_instruction = 0
self.scope = scope.new_child()
self._stack = []
def get_local(self, name):
return self.scope[name]
def set_local(self, name, value):
self.scope[name] = value
...
这样,Interpreter 的实现被大大简化,但构造方法变得复杂了一些:
class Interpreter:
def __init__(self, source, local_vars=None,
dump_code=False, trace_stack=False):
self._code = compile(source, filename='', mode='exec')
self._dump_code = dump_code
self.trace_stack = trace_stack
builtin_dict = {x: getattr(builtins, x) for x in dir(builtins) if not x.startswith('__')}
self._scope = ChainMap(builtin_dict)
self._frames = []
main_frame = Frame(self, self._code, self._scope)
if local_vars:
for k, v in local_vars.items():
main_frame.set_local(k, v)
self._frames.append(main_frame)
# main frame treat as global scope and never pop
def top_frame(self):
return self._frames[-1]
def get_local(self, name):
return self.top_frame().get_local(name)
def set_local(self, name, value):
self.top_frame().set_local(name, value)
def frame_push(self, frame):
self._frames.append(frame)
def frame_pop(self):
if len(self._frames) == 1:
raise RuntimeError('main frame cannot pop out')
return self._frames.pop(-1)
def exec(self):
if self._dump_code:
dump_recursive(self._code)
self.top_frame().exec()
_frames 也是一个类似于堆栈的结构,每次调用函数就会形成一个新的 Frame,而执行完毕后就会被清除。解释器一开始就会初始化主模块,但执行完毕后并不从栈上弹出——因为我们还要检查主模块的变量值。为了避免出错,frame_pop() 部分包含了额外的检查。
现在,我们打开新添加的测试,并添加对新指令的支持。首先是 MAKE_FUNCTION,它把代码对象和一个名字关联起来,形成新的函数对象。该指令的参数有不少细节要处理,因为函数参数存在按位置、可变参数、命名参数和默认值等多种不同的绑定方式,所以要完整实现是相当麻烦的。我这里不准备处理所有细节,只支持位置参数就可以了,但基本的分支逻辑还是全部包括进来了:
def exec_MAKE_FUNCTION(self, flags):
name = self.stack_pop()
code = self.stack_pop()
freevars, annonations, defaults, kwdefaults = None, None, None, None
if flags & 0x8:
freevars = self.stack_pop()
if flags & 0x4:
annonations = self.stack_pop()
if flags & 0x2:
kwdefaults = self.stack_pop()
if flags & 0x1:
defaults = self.stack_pop()
func = Function(self._interpreter, name, code, freevars, annonations, kwdefaults, defaults)
self.stack_push(func)
MAKE_FUNCTION 只是定义了函数,它会被后续的指令保存在局部变量中。只有真正执行(也就是CALL_FUNCTION)的时候它才会真正构造出一个 Frame。
在实现之前先回想一下,CALL_FUNCTION 指令现在用于两种不同的场景:
- 调用内置函数。这时我们只需要像普通代码一样执行它——运行时会处理所有细节
- 调用自定义函数:我们需要自己处理参数压栈/出栈的操作
为了让两种情况能够得到一致的处理,Function 对象最好能像普通函数一样调用,内部去处理这些调用细节。也就是说,它需要实现 __call__ 调用协议:
class Function:
def __init__(self, interpreter, name, code, freevars, annonations, kwdefaults, defaults):
self.interpreter = interpreter
self.name = name
self.code = code
self.freevars = freevars
self.annonations = annonations
self.kwdefaults = kwdefaults
self.defaults = defaults
def __call__(self, *args, **kwargs):
frame = Frame(self.interpreter, self.code, self.interpreter.top_frame().scope)
frame.set_args(args)
self.interpreter.frame_push(frame)
result = frame.exec()
self.interpreter.frame_pop()
return result
这里,Function.__call__ 方法处理了调用的细节。虽然看起来很简单,但是正像前面提到过的,如果考虑到多种参数绑定方式的话,最终的实现可能会相当复杂。此外,这里用到一个辅助方法 set_args()。如果所有参数都是按位置绑定的话,那么参数入栈的顺序应该保持和函数变量名保持严格一致的关系。因此,set_args() 的实现大概是这样的:
def set_args(self, args):
for varnum, arg in enumerate(args):
name = self._code.co_varnames[varnum]
self.set_local(name, arg)
然后是 LOAD_FAST 指令:
def exec_LOAD_FAST(self, varnum):
name = self._code.co_varnames[varnum]
value = self.get_local(name)
self.stack_push(value)
在存在函数调用的情况下,RETURN_VALUE 就要发挥它真正的作用了。所以我们还要做一点修改,让它记录实际的值。它也会作为 Function.__call__() 调用的结果被返回:
class ReturnValue(Exception):
def __init__(self, value):
self.value = value
class Frame:
def exec_RETURN_VALUE(self, _):
value = self.stack_pop()
raise ReturnValue(value)
def exec(self):
while True:
try:
...
except ReturnValue as e:
return e.value
现在,测试又可以通过了。
列表解析
上一步是个相当重大的修改,几乎所有实现代码都被改写(或移动)了。不过经此一役,我们也完成了一个具有相当复杂度、能够执行函数调用的解释器。接下来的任务会比较轻松,我们实现 Python 语言中一个独特且有趣的语法构造:列表解析。通过这个过程,我们也可以了解到列表解析在幕后是如何工作的。
还是先上单元测试:
def test_list_comprehension(self):
source = """
n = [x for x in range(a) if x>5]
""".strip()
interpreter = self.exec_interpreter(source, {'a': 10}, True, True)
self.assertEqual([6, 7, 8, 9], interpreter.get_local('n'))
检查字节码:
====dis code of <module>====
co_names: ('range', 'a', 'n')
co_consts: (<code object <listcomp> at 0x0000017C38C6DB30, file "", line 1>, '<listcomp>', None)
co_code: b'd\x00d\x01\x84\x00e\x00e\x01\x83\x01D\x00\x83\x01Z\x02d\x02S\x00'
co_varnames: ()
1 0 LOAD_CONST 0 (<code object <listcomp> at 0x0000017C38C6DB30, file "", line 1>)
2 LOAD_CONST 1 ('<listcomp>')
4 MAKE_FUNCTION 0
6 LOAD_NAME 0 (range)
8 LOAD_NAME 1 (a)
10 CALL_FUNCTION 1
12 GET_ITER
14 CALL_FUNCTION 1
16 STORE_NAME 2 (n)
18 LOAD_CONST 2 (None)
20 RETURN_VALUE
====dis code of <listcomp>====
co_names: ()
co_consts: (5,)
co_code: b'g\x00|\x00]\x10}\x01|\x01d\x00k\x04r\x04|\x01\x91\x02q\x04S\x00'
co_varnames: ('.0', 'x')
1 0 BUILD_LIST 0
2 LOAD_FAST 0 (.0)
>> 4 FOR_ITER 16 (to 22)
6 STORE_FAST 1 (x)
8 LOAD_FAST 1 (x)
10 LOAD_CONST 0 (5)
12 COMPARE_OP 4 (>)
14 POP_JUMP_IF_FALSE 4
16 LOAD_FAST 1 (x)
18 LIST_APPEND 2
20 JUMP_ABSOLUTE 4
>> 22 RETURN_VALUE
结果可能出乎你的意料:尽管源码只有一行、也没有定义任何函数,但生成的字节码却是嵌套的。通过内部函数的名称(
我们再看看列表解析所使用的新指令。
BUILD_LIST(n)
从堆栈中取出 n 个元素并形成一个列表。在本例中,构造的是一个空列表。
FOR_ITER(delta)
该方法假定堆栈顶部是一个可迭代对象,并获取它的下一个值。如果返回一个新值,则将新值压入堆栈并继续执行;否则,将该迭代对象弹出,并跳转到参数指定的地址(偏移量)
LIST_APPEND(i)
这个指令有些复杂。它假定栈顶是一个值,而 TOS[-i] 是一个列表,将值附加到列表的末尾。这个指令的存在可能有些出乎意料:我们可能会认为只需要调用 list.append() 方法就好,而 Python 解释器却专门为它添加了一个指令。文档也提到,该指令是专门为列表解析这种场景而设计的,它跳过了正常的方法查找规则,因此速度更快,代价是失去了运行期的灵活性,可以认为这是为了提高执行速度而进行的专门优化。
JUMP_ABSOLUTION(taret)
按照绝地地址进行跳转。
其他部分我们在前面的 if 阶段已经见过,理解起来应该没什么难度。因此,我们的任务就是实现这些新的指令。只要理解了它们各自的工作原理,实现起来应该没什么难的。
def exec_BUILD_LIST(self, count):
value = self.stack_popn(count)
self.stack_push(value)
def exec_FOR_ITER(self, delta):
it = self.stack_top()
try:
value = next(it)
self.stack_push(value)
except StopIteration:
self.stack_pop()
self.jump_delta(delta)
return True
def exec_LIST_APPEND(self, i):
value = self.stack_pop()
l = self._stack[-i]
assert isinstance(l, list)
l.append(value)
def exec_JUMP_ABSOLUTE(self, target):
self.jump_by_offset(target)
return True
上述代码用到一个辅助方法 dump_delta(delta)。实际上它和从前面实现的 JUMP_FORWARD 指令的跳转规则是一样的,既然有多个指令用到它,我们还是提取出一个辅助方法。
此外,主模块代码还包括一个新指令 GET_ITER。这也是一个简单的指令,文档几乎已经给出了它的伪代码实现,这里就不再啰嗦了。有兴趣的同学可以直接参考代码。
总结
经过前面几个步骤,我们实现了一个具有一定复杂度的解释器,可以执行许多比较简单的代码。当然,还有很多高级语法构造如类、异常、with、异步代码等尚未得到支持。尽管这些内容各自都有着相当的复杂度,不可能在一篇文章中讲清楚,但我相信只要掌握了基本的思路,不断扩充以支持更多语法应该不是难事。
编写解释器也有助于我们理解 Python 的工作内幕,同时对一些规律也能有深入的认识。比如,有的书籍会提到:你可以从 list,dict 等内置类派生,但 Python 不一定会调用你所定义的方法,这是为什么?自己动手实现过 LIST_APPEND 指令以后,相信你对此已经能自己回答这个问题了。除此之外,对于 Python 程序到底慢不慢、有多慢的问题,我们也能从指令的角度得到更具体的答案。
如果你对本文的解释器感觉不满意的话,也有很多地方可以继续优化。一个明显的方向是增加更多的指令支持(我们只实现了很少的一部分指令,部分指令的支持也还不是非常完成)。如果你像原文的作者一样有雄心,希望实现一个类似 byterun 那样近乎完整的解释器,那简直太好了。我也希望你能把自己的发现分享给我。
另一个可能的优化方向是性能。前面已经多次提到过,本文的解释器在执行效率方面并不高。比如压栈、出栈操作,真正的解释器通常会使用直接移动栈指针的方式以提高效率,而不会像本文那样老老实实地修改列表。此外,查找变量和计算偏移量等算法也没有使用高效的数据结构(和算法)。当然,要追求效率几乎肯定会让程序变得更加复杂和难以理解,这就是我为什么刻意回避了性能问题的原因。如果你愿意的话,也可以为了性能而优化——当然,更高效的方式是用比较底层的语言,比如C/C++去实现。
文章索引
- 重写 500 Lines or Less 项目 - 前言
- 重写 500 Lines or Less 项目 - Web Server
- 重写 500 Lines or Less 项目 - Template Engine
- 重写 500 Lines or Less 项目 - Continuous Integration
- 重写 500 Lines or Less 项目 - Static Analysis
- 重写 500 Lines or Less 项目 - A Simple Object Model
- 重写 500 Lines or Less 项目 - A Python Interpreter Written in Python
- 重写 500 Lines or Less 项目 - Contingent
- 重写 500 Lines or Less 项目 - DBDB
- 重写 500 Lines or Less 项目 - FlowShop
- 重写 500 Lines or Less 项目 - Dagoba
- 重写 500 Lines or Less 项目 - 3D 建模器