重写 500 Lines or Less 项目 - A Simple Object Model
概述
本文章是 重写 500 Lines or Less 系列项目其中一篇,目标是重写 500 Lines or Less 系列的原有项目:A Simple Object Model。在阅读原文时,我发现一个问题:作者设计的代码其实是非常合理的,问题在于他直接给出了几乎是最终版的类层次结构,首次阅读的用户来说很可能会对为什么要这样设计感到疑惑。我也是在自己从头完整地实现一遍之后,才算是比较清楚地理解到作者的设计意图。因此,本次重写主要在以下几个方面做出改变:
- Python3
原文代码同时兼容于 PY2/3。考虑到目前的发展趋势,本文将只考虑 PY3,不再特意去兼容 PY2。更明确地说,本文代码是在 Python3.7 上开发并测试的,采用了一些更加现代的代码风格,特别是 f-string 和类型标注等。因为使用的都是语言本身的功能,因此使用哪一种操作系统并不重要。
- 测试驱动
原文使用了大量测试用例,既作为对象模型的设计参考,也用来保证程序实现的正确性。本文继续沿用这种风格,测试内容也大体上和原文一致,但是更进一步:采用测试驱动(TDD)的风格开发。在后续内容中,我们将看到设计是如何根据测试要求而逐步演化的。
原文使用的测试框架是 pytest/nose(两种框架在测试接口上非常类似,使用哪一种都可以)。但考虑到本文的代码仓库是多个项目的集合,为了管理起来更加容易,我希望尽可能避免引入不必要的第三方依赖,所以还是使用 Python 内置的 unittest。虽然 unittest 在语法上会稍微啰嗦一些,但代码的复杂性主要在于对象模型本身,测试引起的差别并不大。
- 结构调整
如 概述 部分所述,本文采取分阶段、递进式的写法,逐步完成整个程序,相信这样更加有利于读者逐步理解整个项目的全貌,也能够看清楚代码设计是怎样随着要求变化逐步“浮现”出来的,这样更加符合程序开发的现实情况。
文章结构
本文按照如下步骤依次开发:
- 读写对象属性 搭建一个粗糙的对象模型,首先实现对象属性的读写;
- 读写类属性 在第一步的基础之上,将读写支持扩大到类。为此,需要对实现结构进行一定的重构;
- 类型判断 实现对象类型的关系判断,也就是类似
Python的isinstance函数; - 调用方法 实现调用对象和类的方法;
- 元对象协议 以
__getattr__/__setattr__接口为例,展示如何实现一个类似于Python的元对象协议(meta-object protocol)。 - 性能优化 展示如何用一种常用的手法,去优化对象模型的内存占用
原文首先用一些篇幅介绍了关于对象模型的背景知识,这部分内容对本文也同样适用,因此读者可以直接去阅读原文,这里就不再重复了。
示例代码
本文及系列文章的所有代码都开源在 Github 仓库:500lines-rewrite。本文相关的代码位于 objmodel 目录,在其下为每个阶段创建了单独的子目录。为了避免为每个步骤创建单独的环境,读者可以将主目录下的 main.py 作为入口,并打开相应的引用部分来运行程序。
下面我们就来编写程序。
读写属性
本文采用测试驱动(TDD)方法,因此首先要做的是为将要实现的需求编写一个测试用例。在测试中,我们沿用原文的做法,即首先给出 Python 版本的调用方法,再给出对应的自定义模型版本。
通常来说,定义语言模型的工作应该是由某种低级语言实现的(比如 Python 的对象模型定义实际上是在 C 源码中)。为了容易理解,我们的示例还是用 Python 编写。请读者了解,这里定义对象和创建实例的操作在实际的 OOP 语言中应该被编译器或解释器转换成某种内部表示,因此最终的用户代码不会有那么啰嗦。
我们要测试的目标是:为对象设置属性,然后检查设置的值是否生效。我们把类的定义和实例分别称为 Class 和 Instance。
class ObjModelTest(unittest.TestCase):
def test_get_set_field(self):
# Python
class A:
pass
obj = A()
obj.a = 1
self.assertEqual(1, obj.a)
obj.b = 5
self.assertEqual((1, 5), (obj.a, obj.b))
obj.a = 2
self.assertEqual((2, 5), (obj.a, obj.b))
# Object Model
A = Class(name='A')
obj = Instance(A)
obj.set_attr('a', 1)
self.assertEqual(1, obj.get_attr('a'))
obj.set_attr('b', 5)
self.assertEqual((1, 5), (obj.get_attr('a'), obj.get_attr('b')))
obj.set_attr('a', 2)
self.assertEqual((2, 5), (obj.get_attr('a'), obj.get_attr('b')))
为了让测试通过,我们需要实现上述两个类。以下的实现非常简单而粗糙,我们也非常清楚它存在一些潜在的问题,但是按照 KISS 原则,请抑制住马上优化的冲动,只编写让测试通过的最简单的代码。
class Class:
def __init__(self, name: str):
self.name = name
class Instance:
def __init__(self, cls: Class):
self.cls = cls
self._fields = {}
def get_attr(self, name: str):
return self._fields[name]
def set_attr(self, name: str, value):
self._fields[name] = value
这样简单的实现就足以让测试通过。然后,为了让它更为完整一些,我又增加了一个测试,目的是为了检查边际情况:如果读取尚未设置的属性,模型应该抛出 AttributeError:
def test_get_set_field_missing(self):
# Python
class A:
pass
obj = A()
with self.assertRaises(AttributeError):
obj.a
# Object Model
A = Class(name='A')
obj = Instance(A)
with self.assertRaises(AttributeError):
obj.get_attr('a')
测试失败了。但是我们只需要在 get_attr() 方法中添加一句检查,就可以再次满足测试:
class Instance:
def get_attr(self, name: str):
if name not in self._fields:
raise AttributeError(f"'{self.cls.name}' has no attribute {name}")
return self._fields[name]
读写类属性
不仅对象实例可以定义和访问属性,类本身也可以。在某些语言中,属于类的变量称为静态变量,需要明确地用 static 来声明。而在 Python 中,凡是在类范围内、而不是方法作用域内声明的变量,都会自动绑定到类本身(静态方法的声明比较特殊,这里暂不考虑)。还是编写测试用例:
def test_get_set_class_field(self):
# Python
class A:
a = 1
self.assertEqual(1, A.a)
A.a = 2
self.assertEqual(2, A.a)
# Object Model
A = Class(name='A', fields={'a': 1})
self.assertEqual(1, A.get_attr('a'))
A.set_attr('a', 2)
self.assertEqual(2, A.get_attr('a'))
实现上述逻辑并不困难,我们只需要把实例的做法照搬过来即可。但 Class 和 Instance 在其他方面也存在一些相似性,所以最好是再创建一个公共基类 Base,把共享的逻辑提取出来。
class Base:
def __init__(self, fields: dict = None):
self._fields = fields or {}
def get_attr(self, name: str):
return self._fields[name]
def set_attr(self, name: str, value):
self._fields[name] = value
class Class(Base):
...
class Instance(Base):
...
现在测试通过了。但 Class 和 Instance 只读取自身定义的属性,而实际上,在类中定义的属性通过实例也是可以访问的。但反过来说,通过实例设置的属性应该由实例来管理,不应该写到类的静态属性中去。写个测试来证明这一点:
def test_get_class_field_from_instance(self):
# Python
class A:
a = 1
obj = A()
self.assertEqual(1, obj.a)
obj.a = 2
self.assertEqual(2, obj.a)
self.assertEqual(1, A.a)
# Object Model
A = Class(name='A', fields={'a': 1})
obj = Instance(A)
self.assertEqual(1, obj.get_attr('a'))
obj.set_attr('a', 2)
self.assertEqual(2, obj.get_attr('a'))
self.assertEqual(1, A.get_attr('a'))
为此,我们的查找逻辑需要稍作修改:如果属性在实例中没有找到,则需要去查找它所定义的类型。
现在查找规则开始复杂起来了,我们需要尝试多个方向,只有所有可能的路径全部失败的情况下,才抛出 AttributeError。所以,特定的查找规则本身不应该再抛出异常,而是返回某种明确的标志表示找不到。这个“找不到”的标志我们把它叫做MISSING,它应该只存在一个实例。为什么不用 None?因为给属性赋值为 None 是完全合法的,所以它不能用来表示“找不到”。
class Base:
def get_attr(self, name: str):
if name not in self._fields:
raise AttributeError(f"'{self.cls.name}' has no attribute {name}")
return self.read_dict(name)
def read_dict(self, name: str):
return self._fields.get(name, MISSING)
class Instance(Base):
def __init__(self, cls: Class, fields: dict = None):
super().__init__(fields=fields)
self.cls = cls
def get_attr(self, name: str):
# Lookup in instance first
value = self.read_dict(name)
if value is not MISSING:
return value
# Then check if defined by class
value = self.cls.read_dict(name)
if value is not MISSING:
return value
raise AttributeError(f"'{self.cls.name}' has no attribute {name}")
MISSING = object()
类型判断
现在,我们已经有了一个可以工作的对象模型。现在需要为它增加重要的特性:支持基于继承关系的类型判断。在 Python 里面用 isinstance 方法来完成这个工作。
def test_iscreate_instance(self):
# Python
class A: pass
class B(A): pass
b = B()
self.assertTrue(isinstance(b, B))
self.assertTrue(isinstance(b, A))
self.assertTrue(isinstance(b, object))
self.assertFalse(isinstance(b, type))
# Object Model
A = Class(name='A')
B = Class(name='B', base=A)
b = Instance(B)
self.assertTrue(b.is_instance(B))
self.assertTrue(b.is_instance(A))
self.assertTrue(b.is_instance(Object))
self.assertFalse(b.is_instance(Type))
这里出现了两个新的东西:Object 和 Type。许多主流面向对象语言使用单继承关系,没有明确指定基类的对象默认从 object 继承,这样 object 就成了“万类之母”。Python 也支持多继承,但最终基类仍然是 object。type 则属于非常特殊的一种对象,它用来定义“类型”。
为了让对象判断它是否属于特定的类型,我们需要沿着继承层次关系一直向上查找,直到发现目标为止。这从本质上讲是一种递归操作:
class _Class(Base):
def inheritance_hierarchy(self):
yield self
if self._base:
for base in self._base.inheritance_hierarchy():
yield base
class _Instance(_Base):
def is_instance(self, cls):
return cls in self.cls.inheritance_hierarchy()
其次,类型本身也支持 isinstance 判断,不过它的规则要简单的多:所有类型都算是 type,但彼此之间不再有继承关系。
def test_isinstancedefine_class(self):
# Python
class A: pass
class B(A): pass
self.assertTrue(isinstance(B, type))
self.assertTrue(isinstance(A, type))
# Object Model
A = Class(name='A')
B = Class(name='B', base=A)
self.assertTrue(B.is_instance(Type))
self.assertTrue(B.is_instance(Type))
因此实现很简单:
class _Class(_Base):
def is_instance(self, cls):
return cls is Type
在完成上述代码之后,我意识到,现在对象模型暴露出两组对象:Class/Instance 和 Object/Type,它们之间的区别有点让人容易混淆。实际上,Object/Type 可以大致看做是对应于 Python 中的 object/type,它们是用户可以访问的,而 Class/Instance 只用来定义对象模型,对于使用者来说它应该是透明的。为了避免混乱,我又进行了以下重构:
Class/Instance重命名为_Class/_Instance,表明它们是不应该直接使用的内部对象;objmodel模块提供define_class以及create_instance方法,用来定义对象以及创建对象实例。它们不过是上述对象的简单包装,作为创建对象的原语;- 对测试而言,把创建
Class/Instance的操作变成分别调用define_class/create_instance,参数不变。
调用方法
除了读写属性之外,对象模型另一种重要的操作是调用方法(有的 OOP 语言称为 member function)。对于 Python 而言,方法的第一个参数总是和对象实例绑定的,按照约定,它应该叫做 self。
def test_call_method(self):
# Python
class A:
def f(self):
return self.x + 1
obj = A()
obj.x = 1
self.assertEqual(2, obj.f())
class B(A): pass
obj = B()
obj.x = 2
self.assertEqual(3, obj.f())
# Object Model
def f_A(self):
return self.get_attr('x') + 1
A = define_class(name='A', fields={'f': f_A})
obj = create_instance(A)
obj.set_attr('x', 1)
self.assertEqual(2, obj.call_method('f'))
B = define_class(name='B', base=A)
obj = create_instance(B)
obj.set_attr('x', 2)
self.assertEqual(3, obj.call_method('f'))
我们目前的实现可以找到方法,但并不能作为普通函数来调用,因为它并不知道如何传递实例参数(self)。为了能够调用,我们要把它变成一个绑定对象实例的函数,在 Python 术语中叫做绑定方法(bound method)。
想要把函数变成绑定方法,我们有两个途径。想要偷懒的话,最简单的方式是使用基础库给我们提供的 functools.partial()。或者我们也可以自己写一个返回方法的高阶函数。这两种方法从效果上讲是完全相同的,使用哪一种就看个人喜好了。在下面的代码中同时包括两种写法:
class _Instance(_Base):
def call_method(self, name: str, *args, **kwargs):
fn = self.get_attr(name)
# method = functools.partial(fn, self)
method = self.make_bound_method(fn)
return method(*args, **kwargs)
def make_bound_method(self, fn):
def method(*args, **kwargs):
return fn(self, *args, **kwargs)
return method
现在测试可以正常通过了。我们再试试看包含参数的方法能否正常调用:
def test_call_method_with_args(self):
# Python
class A:
def f(self, delta):
return self.x + delta
obj = A()
obj.x = 1
self.assertEqual(3, obj.f(2))
# Object Model
def f_A(self, delta):
return self.get_attr('x') + delta
A = define_class(name='A', fields={'f': f_A})
obj = create_instance(A)
obj.set_attr('x', 1)
self.assertEqual(3, obj.call_method('f', 2))
没有问题。但且别忙结束这个步骤,调用方法还有另外一种方式:把方法作为一个函数变量来调用:
def test_call_method_by_attr(self):
# Python
class A:
def f(self):
return self.x + 1
obj = A()
obj.x = 1
method = obj.f
self.assertEqual(2, method())
# Object Model
def f_A(self):
return self.get_attr('x') + 1
A = define_class(name='A', fields={'f': f_A})
obj = create_instance(A)
obj.set_attr('x', 1)
method = obj.get_attr('f')
self.assertEqual(2, method())
测试出错了。这是因为绑定方法的操作发生在 call_method(),但通过属性执行并未调用这个方法。为了解决此问题,我们要把绑定操作搬移到 get_attr(),让它在被获取之前就执行绑定:
class _Instance(_Base):
def get_attr(self, name: str):
value = self.read_dict(name)
if value is _MISSING:
value = self.cls.read_dict(name)
if value is _MISSING:
raise AttributeError(f"'{self.cls.name}' has no attribute {name}")
if callable(value):
# return functools.partial(value, self)
return self.make_bound_method(value)
else:
return value
元对象协议(Meta Object Protocol)
我们知道,Python 定义了许多特殊方法,这些方法通常以双下划线作为标志,具有特殊含义,如果存在的话,它们可以通过多种不同的方式调整对象的行为。这些特殊方法就是所谓的元对象协议(meta object protocol)。在前面的部分,我们实现了通过“正常”方式访问对象属性。除此之外,Python 也允许我们自己实现 __getattr__ 或 __setattr__ 方法,通过“非正常”的方式来读写属性。我们接下来以这两个方法为例,看看对象模型如何处理特殊协议。
注:原文采用的例子是摄氏/华氏温度的互相转换。考虑到国内很少使用华氏温度,所以我把它换成比较容易理解的例子:角度/弧度的互相转换。
元对象协议虽然威力强大,但编写的时候也要特别小心,比如 __getattr__/__setattr__ 如果实现不正确的话很容易引起无限递归。因此,无论如何都要保证一定数量的测试,以便尽早发现问题。
def test_get_attr(self):
scales = dict(degree=1, radian=math.pi / 180)
# Python
class A:
def __getattr__(self, name):
if name in scales:
return self.degree * scales[name]
raise AttributeError(name)
def __setattr__(self, name, value):
if name in scales:
object.__setattr__(self, name, value / scales[name])
obj = A()
obj.degree = 180
self.assertEqual(math.pi, obj.radian)
# Object Model
def __getattr__(self, name):
if name in scales:
return self.get_attr('degree') * scales[name]
raise AttributeError(name)
def __setattr__(self, name, value):
if name in scales:
self.set_attr(self, name, value / scales[name])
A = define_class(name='A',
fields={'__getattr__': __getattr__, '__setattr__': __setattr__})
obj = create_instance(A)
obj.set_attr('degree', 180)
self.assertEqual(math.pi, obj.get_attr('radian'))
我们需要把这些特殊方法的处理加入到正常的属性访问逻辑中:
class _Instance(_Base):
def get_attr(self, name: str):
value = self.read_dict(name)
if value is _MISSING:
value = self.cls.read_dict(name)
if value is _MISSING:
getter = self.cls.read_dict('__getattr__')
if getter is not _MISSING:
return getter(self, name)
if value is _MISSING:
raise AttributeError(f"'{self.cls.name}' has no attribute {name}")
if callable(value):
# return functools.partial(value, self)
return self.make_bound_method(value)
else:
return value
def set_attr(self, name: str, value):
setter = self.cls.read_dict('__setattr__')
if setter is not _MISSING:
return setter(name, value)
return super().set_attr(name, value)
可以看到,要支持元对象协议并不困难(尽管我们忽略了一些细微的错误检查)。但加入各种协议处理之后,对象的访问代码变得更加复杂也更容易出错了。按照类似的规则,我们可以支持更多不同类型的协议,对本示例而言,理解原理就可以了。
性能优化
最后一个步骤和功能无关,而是着眼于内存方面的优化。到目前为止,我们保存属性使用的是 Python 中的字典(dict)。如果单从实现角度看,使用 dict 是完全合理的;但我们也需要了解一个事实,那就是 dict 为了提高效率,对内存的占用是相当可观的。这种占用可以用内置方法 getsizeof() 观察到:
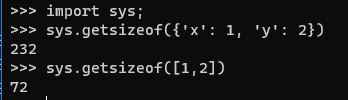
可见,一个仅包含两个属性的字典就占用了 200 字节以上的内存,可以说是非常惊人了。如果我们只保存值的话,就能够节省超过 2/3 的空间。当然,我们不能只保存值,还要考虑需要的时候如何访问到值的问题。这就引出了另一个客观现象:在大多数情况下,相同类型的对象具有的属性应该是相同的,只是值不同而已。比如说,用来保存坐标的 Point 对象总是需要 x/y 两个属性。尽管对于动态语言来说,在运行时添加属性是完全可能的,但这种需求相当罕见。
所以,问题可以归结为:是否可以把对象的属性设计成某种类似 copy-on-write 的数据结构,保证具有相同属性的对象总是引用同一个目标,而新增属性则会创建全新的目标?完全可以。这也是在一些动态语言中普遍采用的优化手段。原文也通过一张示意图形象地说明了此方法:
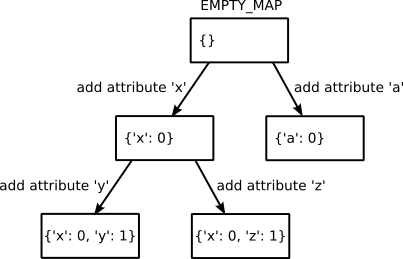
在该图中,所有属性定义都从一个空白字典开始,并形成一个有向图。添加一个属性会创建一个新的边,并导向一个新的属性集合。如果我们遵循先设置属性 x、再设置属性 y 的顺序,那么最后总会走到相同的节点(左下角),也就是使用相同的数据。
有的同学可能会想到,如果我们先设置 y 再设置 x,结果就不同了。的确如此,但考虑到现实的程序总是使用相同的代码(不考虑运行期生成等特殊场景),因此初始化顺序也应该是相同的,所以这个问题并不严重。
因为是性能优化,所以测试用例不能再单纯检查程序的行为,而是要关注它所使用的内部数据结构是否指向预期的目标。也就是说,我们现在要作“白盒测试”(相对于“黑盒测试”):
def test_use_map(self):
Point = define_class(name='Point')
p1 = create_instance(Point)
p1.set_attr('x', 1)
p1.set_attr('y', 2)
self.assertEqual([1, 2], p1._values)
self.assertEqual({'x': 0, 'y': 1}, p1._map._attrs)
p2 = create_instance(Point)
p2.set_attr('x', 5)
p2.set_attr('y', 6)
self.assertEqual([5, 6], p2._values)
self.assertIs(p1._map, p2._map)
p3 = create_instance(Point)
p3.set_attr('x', 100)
p3.set_attr('z', -343)
self.assertEqual({'x': 0, 'z': 1}, p3._map._attrs)
self.assertIsNot(p1._map, p3._map)
只要读者理解了上面的原理图,那么看懂实现代码应该不成问题:
class AttrMap:
def __init__(self, attrs: dict):
self._attrs = attrs
self._next = {}
def index_of(self, name: str):
return self._attrs.get(name, -1)
def next(self, name):
if name in self._attrs:
return self
if name in self._next:
return self._next[name]
attrs = self._attrs.copy()
attrs[name] = len(attrs)
new_map = AttrMap(attrs)
self._next[name] = new_map
return new_map
EMPTY_MAP = AttrMap({})
然后,我们需要把原来的内部字典替换成新的数据结构,并相应修改访问逻辑:
class _Base:
def __init__(self, fields: dict = None):
self._map = EMPTY_MAP
self._values = []
if fields:
for k, v in fields.items():
self.set_attr(k, v)
def get_attr(self, name: str):
if name not in self._map._attrs:
raise AttributeError(f"'{self.cls.name}' has no attribute '{name}'")
return self.read_dict(name)
def set_attr(self, name: str, value):
index = self._map.index_of(name)
if index >= 0:
self._values[index] = value
else:
self._map = self._map.next(name)
self._values.append(value)
def read_dict(self, name: str):
index = self._map.index_of(name)
if index < 0:
return _MISSING
return self._values[index]
当然,我们的测试程序规模很小,这种优化无法在直观上体现出来。但对于使用成千上万对象的大型应用来说,优化能够节省的内存空间还是相当可观的。
总结
到此,我们以 Python 语言为蓝本,实现了一个基本的对象模型,包括属性读写、类型检查、调用方法、元对象协议,最后甚至做了一些性能优化的工作。
如果对这个模型觉得不够完善的话,我们可以找到很多方向去继续修改它。一个显而易见的方向是支持更多的元对象协议。另一个可能的目标是支持多继承(本文代码只实现了单继承,但是扩展实现来支持多继承也是很容易的)。或者你也可以考虑更进一步,实现其他风格的对象模型,比如基于原型(类似于 JavaScript)的对象模型。
可能最大的遗憾是:示例实现的是一个“概念”上的模型,由于缺乏语法级别的支持,我们并没有真正实现一个面向对象的编程语言。但发明一种新的语言明显放大了这个问题的难度,也不太可能仅仅在 500 行代码之内搞定(我知道有人想说 Lisp,但那又是另外一个话题了...)
最后需要说明的是,本文最后实现的代码和原文的思路基本上是相同的,虽然细节上有所差异,但那只是个人风格上的不同。我个人在阅读原文的时候曾经感觉到困惑,主要是因为作者一开始就给出了 Base/MISSING/callmethod 等实现细节,但从头几个测试看不出来这些设计的意义在哪,只有完整走下来才会明白。所以我采用分步的方法来开发,让设计根据需求自己“浮现”出来,相信也能够让读者朋友少走一些弯路,对于更好地理解作者的设计意图有所帮助。
文章索引
- 重写 500 Lines or Less 项目 - 前言
- 重写 500 Lines or Less 项目 - Web Server
- 重写 500 Lines or Less 项目 - Template Engine
- 重写 500 Lines or Less 项目 - Continuous Integration
- 重写 500 Lines or Less 项目 - Static Analysis
- 重写 500 Lines or Less 项目 - A Simple Object Model
- 重写 500 Lines or Less 项目 - A Python Interpreter Written in Python
- 重写 500 Lines or Less 项目 - Contingent
- 重写 500 Lines or Less 项目 - DBDB
- 重写 500 Lines or Less 项目 - FlowShop
- 重写 500 Lines or Less 项目 - Dagoba
- 重写 500 Lines or Less 项目 - 3D 建模器