重写 500 Lines or Less 项目 - Web Server
本文章是 重写 500 Lines or Less 系列项目其中一篇,目标是重写 500 Lines or Less 系列的原有项目:A Simple Web Server。原文章代码是用 Python2 开发的,目前在 Python3 上无法正常运行。同时,部分内容比如 CGI 也已经不太适合目前的时代。因此本次重写主要关注以下方面:
- Python3
原文代码除了使用 Python2 之外,还保留了一些旧式的代码风格,比如 old style class、小写类名等等。经过重写的代码采用更加现代的代码风格,并且使用了 f-string、类型标注等较新的语法特性。要运行代码,请使用 Python3.6 以上版本。
- 去掉原理性介绍
原文用了大量篇幅解释 Web 服务器和 HTTP 的基本工作原理。这些内容现在看来也并不过时,如果读者还不太了解的话,可以阅读原文或参考资料部分列出的中文翻译;同时,网络上也可以找到大量相关的资料可以参考,没有必要再重述。因此,本文不再包括原文中的原理讲解部分。
- 内容调整
原文章涉及到的 CGI 模式在 Web 服务器发展的早期比较常见,但现代 Web 服务器已经有了更高效和先进的模式,CGI 的使用也越来越少见。因此本文不再涉及该话题,而是转而介绍以 Web 服务器常用的处理管线,包括与之匹配的中间件(Middleware)用法。此外,本文还实现了原文没有涉及到的路由组件。
- 结构调整
如 概述 部分所述,本文采取分阶段、递进式的写法,逐步完成整个程序,这样有利于读者循序渐进地理解,也更加符合程序开发的现实情况。
文章结构
本文从头开始,同样在 500 行代码的限制下,实现一个略具规模的基本的 Web 服务器。由于本程序注重于教学目的,不是为了实现具有生产级别的服务器,为此会有意忽略一些协议解析的细节及错误处理,而侧重于整体结构的实现以及架构设计。本文按照如下顺序开发:
-
基本服务 首先实现一个基本的 Web 服务器骨架,了解必备的知识,为进一步的开发做好准备;
-
中间件 复杂的 Web 服务需要应对多种多样的请求类型,为此,Web 服务器也需要有一个灵活的体系结构。这个阶段将模仿常见的 Web 服务器架构,实现一个可扩展的处理管线,并且通过配置不同的中间件(Middleware)来实现灵活的功能组合。
-
静态文件 处理管线创建好之后,我们就能动态插入多种功能。Web 服务器要处理的无非是静态或动态请求,尽管 Web 服务器的主要目标是处理动态请求,但处理静态请求的要求也是存在的,同时它也比较简单,所以我们先实现这一部分。
-
路由 为了支持动态请求,我们需要实现几乎所有 Web 服务器都包含的路由功能。大家可能知道,
Python社区的 Web 服务器对于路由主要有两种实现模式:类似Django的集中管理方式或类似Flask的分散管理方式,其他实现基本上都是这两者的变种。我们这里的例子采用类似Flask的方式实现。如果读者想用Django的方式,也是可能的,感兴趣的话不妨作为练习。
示例代码也是按照如上顺序组织的,大家可以在 web_server 目录下找到所有步骤的代码。
示例代码
本文及系列文章的所有代码都开源在 Github 仓库:500lines-rewrite。本文相关的代码位于 web_server 目录,在其下为每个阶段创建了单独的子目录。为了避免为每个步骤创建单独的环境,读者可以将主目录下的 main.py 作为入口,并打开相应的引用部分来运行程序。
下面我们就来编写这个程序。
基本服务
为了实现 Web 服务器,Python 标准库包含了一个模块 http.server,它提供了基本的构建块,但请求具体该如何处理则交由程序员来实现。这个模块在 Python2 里面叫做 BaseHTTPServer(因此从 PY2 升级到 PY3 时要作相应的修改)。
更具体地说,我们需要创建一个 HTTPServer 的实例作为服务器,而服务器又需要一个从 BaseHTTPRequestHandler 派生的对象来处理请求。请求是根据方法(HTTP Method)也叫做动词(HTTP Verb)来分派的,比如说,要让服务器处理 GET 请求,我们需要实现名为 do_GET() 的方法,处理 POST 请求则实现 do_POST(),依此类推。HTTPServer 会自动把请求信息绑定到该对象的字段,比如 path 和 headers,要输出内容则使用它的 wfile 属性(类似于文件的可写输出流)。
通过实际代码会看得更清楚一些:
from http.server import BaseHTTPRequestHandler, HTTPServer
class RequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
resp_text = f"""<h1>Hello World!</h1>
<p>Client address: {self.client_address}</p>
<p>Command: {self.command}</p>
<p>Path: {self.path}</p>
<p>Headers: {self.headers}</p>
"""
resp_data = resp_text.encode('utf8')
self.send_response(200)
self.send_header("Content-Type", "text/html; charset=utf-8")
self.send_header("Content-Length", len(resp_data))
self.end_headers()
self.wfile.write(resp_data)
def main():
addr = ('', 8080)
server = HTTPServer(addr, RequestHandler)
server.serve_forever()
if __name__ == '__main__':
main()
以上代码将 Web 服务器运行在本机的 8080 端口。我们这个示例同时也演示了如何从请求中提取必要的信息,包括客户端地址、请求路径、HTTP 头部等等。动态 Web 服务器存在的最大理由就是它需要根据客户端请求做出处理,并返回不同的应答信息,因此我们有必要了解有哪些属性是可用的。同时,输出应答也是有要求的,我们必须先输出头部信息,然后才能写入内容体。
运行程序,然后用浏览器访问 http://localhost:8080。我们应该看到类似这样的内容:

同时,在控制台应该有 HTTPServer 自动输出的日志:

这里之所以记录了两个请求,是因为浏览器会在服务器上寻找 favicon.ico,找到的话则作为该网站的图标显示。这是客户端的处理细节,我们可以不用去关心它。
如果你多刷新几次页面,会发现 Client Address 部分的端口是变化的。Web 服务器绑定的端口几乎都是固定的,但客户端连接的时候并不需要指定端口,因此它会使用本机上一个随机的可用端口。当然,一般情况下我们也不用关心客户端的端口,不过看到它的值有助于帮助我们理解幕后发生的事情。
现在我们有了一个基本的 Web 服务器骨架,接下来要考虑如何让它实现更为复杂的功能。
中间件
首先说明,从这个阶段开始,代码会变得有些复杂,并且为了节约篇幅,文章中只给出重点代码,有意忽略掉部分注释和已经出现过的部分。建议读者在阅读的同时参考代码库中的完整代码。
此外,示例代码也使用了 Python 的新功能:类型标注。加入类型标准让 Python 有点类似于强类型的语言,同时也会让代码略显冗长。对于它喜欢与否是个人风格的问题,我个人相信它更符合 Python 之禅,即:显式优于隐式。如果有同学觉得它比较碍眼,并且你所使用的 IDE 是 PyCharm 的话,那么你可以考虑在 PyCharm 的语法高亮方案中为 Type Annotations 选择一个比较黯淡的色调,这样你就能在视觉上快速跳过它们。
要让 Web 服务器处理其他类型的请求,我们可以在 RequqestHandler 中根据请求信息增加相应的处理代码。但是相信大家从上个例子也会意识到,这部分代码膨胀得很快,如果不加以控制的话,很快就会变得无法管理。
现代 Web 服务器基本上都是按照类似如下的思路设计的:
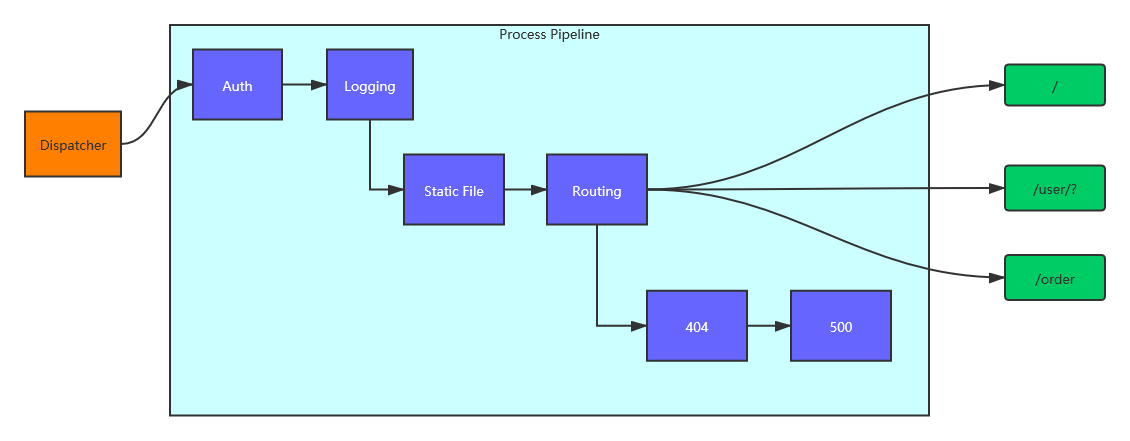
在这种设计下,会有一个输入组件(通常叫做分派者 Dispatcher 或者前端控制器 Front Controller)接收请求并放入一个处理管线(Pipeline)。这个管线类似于工厂流水线的组织形式,其中每个组件只关心某项特定的工作,而通过动态添加管线或调整结构,Web 服务器就能在不修改基本架构的前提下,不断增加新的功能,从而获得了一个高度灵活的体系结构。用架构设计的术语说,这种设计很好地体现了单一职责原则以及开闭原则。
管线上的处理单位在不同的 Web 框架中有不同的叫法,比如中间件(Middleware)、处理器(Handler)或者过滤器(Filter)都是比较流行的名称。本实例将使用中间件(Middleware)这个名称。
一般来说,Web 服务器会有这些类型的中间件:
- 处理和具体业务关联不大的通用功能,如用户验证/授权、日志、跨域、压缩等;
- 返回静态文件,如原始 HTML、CSS、JS、图像;
- 根据网站设计者规定的 URL 规则动态分派和处理客户请求。在大多数 Web 框架中,这个组件会叫做路由(
Routing); - 处理错误。如果某个请求没有任何中间件来处理,那么我们通常希望返回 HTTP 404,表示目标不存在;或者在处理过程中出现异常,按照协议标准,我们应该返回 HTTP 500(或其他 5xx 系列的标准错误码)。
接下来我们来设计这个管线。
我们希望中间件有一个统一的接口,这样管线才能够一致地对待它们。同时,中间件有时候会有一些共享的功能。因此,可以将中间件设计为抽象类:
class Middleware:
def handle(self, ...):
pass
大家可能会想到一个问题:中间件肯定需要一些途径方法从请求和应答中获取信息,而这些信息目前只能通过 RequestHandler 提供的接口来访问。从设计角度讲,我们希望中间件最好只关注自己的功能,不要与 RequestHandler 耦合在一起。为此,首先创建几个辅助类,把请求和应答的信息抽象出来:
class Request:
def __init__(self, handler: BaseHTTPRequestHandler):
self._handler = handler
class Response:
def __init__(self, handler: BaseHTTPRequestHandler):
self._handler = handler
class HttpContext:
def __init__(self, handler: BaseHTTPRequestHandler):
self.request = Request(handler)
self.response = Response(handler)
self.error = None
我们分别用 Request/Response 来代表请求和应答。由于每个中间件都需要它们,因此再添加一个 HttpContext 来汇总这些信息,以简化接口。它还提供了一个字段来记录处理管线中出现的异常,稍后我们在处理 HTTP 500 的时候会用到它。当然,目前这些接口基本上是空的。虽然我们可以基于猜测去添加一些接口,但是我将坚持 KISS (Keep It Simple Stupid)的指导思想,不要预测,而是等到确实需要的时候再去添加它们。
有了这些辅助类,我们把中间件设计为抽象类:
class Middleware:
def handle(self, ctx: HttpContext) -> bool:
raise NotImplementedError()
返回值是一个结构上的优化:如果某个中间件处理了请求,它应该返回 True,这样管线就可以到这里停止,不必再浪费时间遍历所有中间件。
对于本示例而言,为了验证管线的处理逻辑是否正常,我们实现这样几个中间件:
- 模拟通用类型的中间件,为输出加上一个通用的头部信息
- 普通的请求处理中间件,对首页请求(/)输出普通的 HTML 文本。为了测试目的,如果请求 /?err=1,我们让它抛出异常,以便检查后面的错误处理中间件是否正确执行
- 处理 HTTP 错误 404(文件不存在)以及 500(服务器异常)
为了更加匹配现在的用途,我们把前面创建的 RequestHandler 重命名为 RequestDispatcher,并增加处理管线的逻辑:
class RequestDispatcher(BaseHTTPRequestHandler):
def __init__(self, request, client_address, server):
self._middlewares = [
ServerHeader(),
Index(),
NotFound(),
]
self._catchall = GenericError()
super(RequestDispatcher, self).__init__(request, client_address, server)
def do_GET(self):
ctx = HttpContext(self)
try:
for middleware in self._middlewares:
if middleware.handle(ctx):
ctx.response.send()
break
except Exception as e:
ctx.error = e
self._catchall.handle(ctx)
ctx.response.send()
我们在构造函数中定义所有需要执行的中间件。其中 _catchall 比较特殊,它只有在出错的情况下才会介入并接管处理过程,所以单独定义。
以上设计还有一个值得注意的点。通过第一节的代码我们已经知道,RequestHandler 输出顺序是有严格要求的,必须先输出头部再写入正文。但在每个中间件都有机会处理请求的场景下,强制它们组合起来还能遵守顺序是不太现实的。因此我们这样来设计 Response:把所有要输出的头部和内容都缓存下来,当调用 send() 的时候按照规定的顺序统一输出。因此,Response 的实现大概是这样的:
class Response:
"""Provide interface to write HTTP response"""
def __init__(self, handler: BaseHTTPRequestHandler):
self._handler = handler
self._status = 200
self._headers = {}
self._data = BytesIO()
def header(self, key: str, value: str):
self._headers[key] = value
return self
def status(self, code: int):
self._status = code
return self
def html(self, text: str):
self._data.write(text.encode('utf8'))
self._headers.setdefault('Content-Type', 'text/html; charset=utf-8')
return self
def send(self):
self._handler.send_response(self._status)
resp_data = self._data.getvalue()
self._headers.setdefault('Content-Length', len(resp_data))
for k, v in self._headers.items():
self._handler.send_header(k, v)
self._handler.end_headers()
self._handler.wfile.write(resp_data)
代码有点长,不过逻辑还是很简单的。为了简化调用者的工作同时避免出错,我们还添加了逻辑来自动处理某些信息,比如根据输出内容自动生成 Content-Type 以及 Content-Length 头部。
下面我们就可以实现各个中间件了。首先是 ServerHeader:
class ServerHeader(Middleware):
def handle(self, ctx: HttpContext) -> bool:
ctx.response.header('X-Server-Type', '500lines server (testonly)')
它对于任何请求都生成一个固定的头部信息。这里的逻辑很简单,但它确实是有实际意义的,很多现实的 Web 服务都会用基于某种规则生成以 X- 开头的自定义头部。比如说,Github API 会在头部中包含 X-Ratelimit-Limit,告诉你还有多少调用余额可用。
然后是响应对首页(/)的请求:
class Index(Middleware):
def handle(self, ctx: HttpContext) -> bool:
if ctx.request.path == '/':
if ctx.request.query_string('err', '0') == '1':
raise Exception('test error')
else:
ctx.response.html('<h1>Index</h1>')
return True
return False
这里的中间件使用了从 Request 提取参数信息的辅助方法。这是协议的处理细节,实现代码就不再给出了,大家可以参考源码。
如果没有任何中间件处理请求,处理逻辑会来到最末的 NotFound,它会生成 HTTP 404 作为应答:
class NotFound(Middleware):
def handle(self, ctx: HttpContext) -> bool:
ctx.response.status(404).html('<h1>File Not Found</h1>')
return True
最后,处理一般性错误:
class GenericError(Middleware):
def handle(self, ctx: HttpContext) -> bool:
if ctx.error:
logging.getLogger('server').error(str(ctx.error))
ctx.response.status(500).html('<h1>Internal Server Error</h1>')
return True
大家会看到,这里每个中间件的逻辑都是相当简单的(在生产级别的代码中它们肯定会更加复杂一些)。然而,通过把这些中间件串联起来,Web 服务器能够完成非常复杂的任务,同时核心逻辑仍然保持稳定。
代码编写完成,我们可以测试一下。运行程序,用浏览器访问 ·http://localhost:8080/·,我们会看到如下输出:
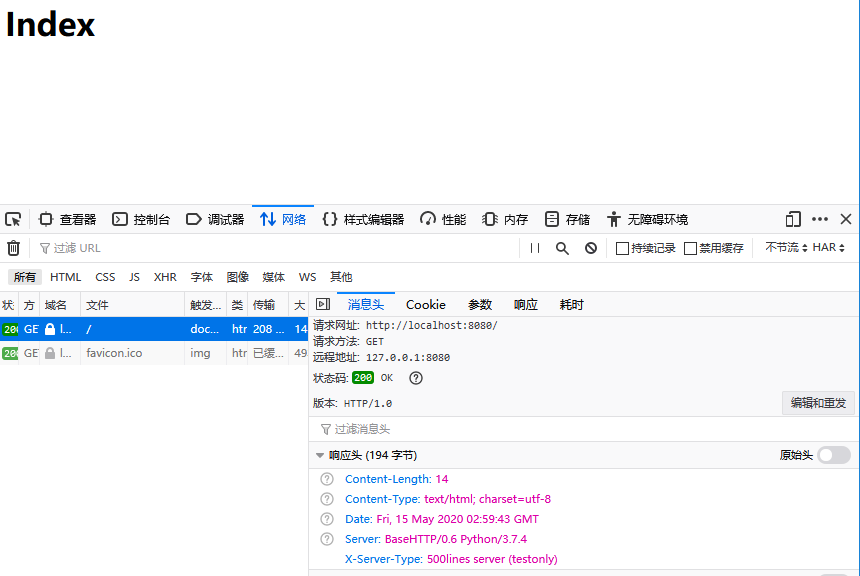
注意浏览器开发工具的响应部分也显示了我们添加的自定义 HTTP 头。
如果我们访问一个不存在的地址,比如 http://localhost:8080/nopage,就会看到 File Not Found 信息,说明 404 的处理也已经生效了。
再访问 http://localhost:8080/?err=1。我们应该在浏览器看到 Internal Server Error 的字样,并且服务器控制台会输出:

到此,HTTP 处理管线已经实现好了,后续的工作基本就是实现各种中间件。首先要处理的是比较简单的静态文件。
静态文件
对于生产级的 Web 服务来说,处理静态文件通常会委托给更加专业且高效的应用,比如 Nginx 或者 Apache。但返回静态内容的需求在一些场合下仍然是存在的,并且如果希望将 Web 服务器作为开发用途,那么程序员通常会希望它能够在本地直接处理静态文件,尽量避免把搭建开发环境的工作搞得过于复杂。
返回本地文件的内容并不难实现,如果你写过用 Python 读写文件的程序的话,应该已经猜到该怎么做了。为了让问题更有趣一点,我们尝试模仿常见的静态服务器行为,概括来说:
- 如果请求指向某个具体的文件,则返回文件内容
- 如果请求指向某个目录
- 若目录下存在公认的“入口”文件,比如 index.html 等等,则返回该文件内容
- 否则,显示该目录下的文件列表
我们分部实现以上要求。处理静态文件的组件仍然是一个中间件:
class StaticFile(Middleware):
def __init__(self, root_path: str):
self._root_path = root_path
class RequestDispatcher(BaseHTTPRequestHandler):
def __init__(self, request, client_address, server):
self._middlewares = [
StaticFile(os.path.dirname(__file__) + '/static'),
# Index(),
NotFound(),
]
...
我们希望静态文件处理器具有一定的灵活性————能够让使用者指定使用哪个目录来存放静态文件。因此,把初始目录作为参数传入构造函数。同时,去掉上一节作为测试的 Index 中间件,代之以新创建的 StaticFile 中间件。
然后,实现返回静态文件的逻辑:
def handle(self, ctx: HttpContext) -> bool:
full_path = os.path.normpath(self._root_path + ctx.request.path)
if os.path.isfile(full_path):
self.send_file(ctx.response, full_path)
return True
return False
def send_file(self, resp: Response, file_path: str):
content_type = mimetypes.guess_type(file_path)[0] or 'application/octec-stream'
with open(file_path, 'rb') as f:
resp.header('Content-Type', content_type).data(f.read())
为了让客户端能够正确显示文件,服务器需要设置响应的 Content-Type 头部。Python 内置模块 mimetypes 提供了方便的获取内容类型的方法,所以我们直接调用它。其他就是简单的文件访问代码了。返回文件的处理逻辑在后面还会用到,所以我们把它封装成 send_file() 方法。
继续扩展该逻辑,加入访问目录时的处理:
def handle(self, ctx: HttpContext) -> bool:
full_path = os.path.normpath(self._root_path + ctx.request.path)
if os.path.isfile(full_path):
self.send_file(ctx.response, full_path)
return True
elif os.path.isdir(full_path):
if self.process_index(ctx.response, full_path):
return True
else:
html = self.build_dir_html(full_path)
ctx.response.html(html)
return True
return False
process_index() 辅助方法查找可能的首页文件,如果找到则返回其内容:
def process_index(self, resp: Response, dir_path: str) -> bool:
index_names = ['index.html', 'index.htm', 'default.html', 'default.htm']
for name in index_names:
index_path = os.path.join(dir_path, name)
if os.path.isfile(index_path):
self.send_file(resp, index_path)
return True
return False
如果没有合适的文件,那么我们根据目录下的文件列表动态生成 HTML 内容。这段代码比较长,但都是简单的 HTML 拼接,为了节约篇幅只显示主要实现。读者可以从代码库找到完整的实现。
def build_dir_html(self, dir_path: str):
lines = []
lines.append(f"<h1>Direcdtory of {os.path.split(dir_path)[1]}:</h1>")
lines.append("<hr/>")
lines.append("<table>")
...
for file_name in os.listdir(dir_path):
full_path = os.path.join(dir_path, file_name)
lines.append("<tr>")
...
lines.append("</tr>")
lines.append("</tbody></table>")
return '\n'.join(lines)
代码完成后,为了看到效果,我们在程序目录下创建 static 子目录,其中包含首页文件(index.html),以及它所引用的图像和 CSS 文件。现在,我们启动程序并访问 http://localhost:8080/,就会看到 index.html 呈现的内容:

你也可以访问 /img 或者 /css,检查动态生成文件列表的效果。
路由
下面来处理 Web 服务器的重头戏:动态请求。通常,Web 服务器会通过路由机制,把不同的请求路径分派到对应的方法去处理。以常见的 Flask 框架为例,它用来定义路由的语法是这样的:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Hello World!'
本阶段也试图实现一个类似的机制,不过我们会基于中间件而不是 App。
class Routing(Middleware):
def __init__(self):
self._routes = []
def handle(self, ctx: HttpContext) -> bool:
for pattern, handler in self._routes:
kwargs = self.match(ctx.request.path, pattern)
if kwargs is not None:
handler(ctx.request, ctx.response, **kwargs)
return True
return False
def match(self, url_path: str, pattern: str) -> dict:
re_pattern = '^' + re.sub(r'<(\w+)>', r'(?P<\1>\\w+)', pattern) + '$'
m = re.match(re_pattern, url_path)
return m.groupdict() if m else None
def route(self, path: str):
def wrapper(f):
self._routes.append((path, f))
return f
return wrapper
代码看上去不算长,但是信息量比较大。首先,我们希望路由格式能够支持类似 Flask 的变量。为了更直观地理解这一点,我们先看看路由函数的定义:
routing = Routing()
@routing.route('/')
def index(req, resp):
resp.html('<h1>Index</h1>')
@routing.route('/user/<name>')
def username(req, resp, name):
resp.html(f"<h1>Hello {name}!</h1>")
第二个方法就是所谓的动态路由,学过 Flask 的同学应该对这段代码相当熟悉。我们希望服务器能够处理任意合法的用户名,因此需要路由格式能够识别尖括号中的变量,并自动把它传递给处理方法的对应参数。为了实现这一点,我们使用了一个较为复杂的正则表达式:
re_pattern = '^' + re.sub(r'<(\w+)>', r'(?P<\1>\\w+)', pattern) + '$'
m = re.match(re_pattern, url_path)
return m.groupdict() if m else None
该表达式的作用是:识别尖括号中的分组,并把它转换为命名的分组表达式,比如 /user/(?P<name>\w+)。用该结果再去匹配路径,如果成功的话,则结果的 groupdict() 就会包含匹配到的参数信息。假如我们使用请求路径 /user/dave 去尝试的话,那么应该返回参数和对应的值 {'name': 'dave'}。
如果读者觉得这段代码理解起来有困难的话,可以把它复制到 Python 解释器中,尝试去处理不同的输入路径,看会得到什么样的结果。
接下来是声明路由的装饰器:
def route(self, path: str):
def wrapper(f):
self._routes.append((path, f))
return f
return wrapper
装饰器是一个高级的 Python 语法构造,我们这里不打算详细介绍它的细节,读者如果觉得有必要,有很多 Python 的进阶学习资料会讲到这个话题。这里的重点是,我们要把声明的路径及其对应的处理函数记录下来,在处理请求时会查找该记录。除此之外,装饰器没有必要修改处理器的实现,因此直接返回原函数即可。
记录下来的路由映射会保存在成员变量 _routes 中。当请求到来时,我们查找该表,确定应该由哪个函数来处理该请求:
def handle(self, ctx: HttpContext) -> bool:
for pattern, handler in self._routes:
kwargs = self.match(ctx.request.path, pattern)
if kwargs is not None:
handler(ctx.request, ctx.response, **kwargs)
return True
return False
我们使用 Python 的可变参数语法,把提取到的路径变量自动映射到函数中对应的参数。因此,如果我们请求 /user/dave 的话,框架会把它映射到函数调用 username(req, res, 'dave')。
最后,把路由添加到处理管线中。通常来说,我们应当把它放到静态文件(StaticFile)的前面,否则我们会看到 index.html,而不是动态处理的结果:
class RequestDispatcher(BaseHTTPRequestHandler):
def __init__(self, request, client_address, server):
self._middlewares = [
routing,
StaticFile(os.getcwd() + '/static'),
NotFound(),
]
现在,我们请求首页(http://localhost:8080/),会看到如下响应:

如果请求任意用户名,比如 http://localhost:8080/user/John,则会看到:

总结
到此,我们的 Web 服务器实现了一个灵活的处理管线,并在此基础上提供了对静态文件以及动态路由的支持,已经具备一个 Web 服务器应有的基本功能了。通过定义新的路由(Routing),我们就能支持各种请求,而无需对服务器内部逻辑作任何修改。
当然,我们实现的还不能算一个产品级别的代码,这里所展现的也不是唯一可行的设计。本文中的例子采用了类似 Flask 的设计风格,如果你更喜欢 Django 的话,那么设计方案肯定会有很大差别。
我们同时也略去了一些细节问题。比如说在处理静态文件的时候,代码使用了读取全部内容的方式。如果客户端要访问的文件很大的话,那么这种方式在速度和内存占用上都是有问题的。此外,如果要支持客户端的流式读取,我们可能要根据 HTTP 的 Range 头部返回相应的内容。还需要说明的是,示例代码并未考虑安全问题;如果服务器运行在生产环境,那么我们应该有一定的安全性检查,不能让客户端随意访问服务器上的任意文件,否则就可能被黑客所利用。不过,这些处理已经超过了本文的范围。如果读者愿意的话,也可以把这些课题作为自己的练习。
如果本文的代码对你来说已经不成问题,那么我建议你再往前迈出一步:阅读一个真正的、产品级别的开源 Web 服务器源码。这里仍然要推荐 Flask,因为它是 Python 社区公认的代码风格比较清晰、一致和 Pythonic 的,同时也不会过于庞大(当然比这里的代码还是要复杂得多)。Django 也是一个可能的选择,不过它的架构复杂度更高,阅读难度也更大。如果你真的有兴趣挑战的话,建议的方法是选一个主题来重点突破,不要试图面面俱到。当然,如果能找到有同好的小伙伴们来一起学习,共同进步,就更好了。
文章索引
- 重写 500 Lines or Less 项目 - 前言
- 重写 500 Lines or Less 项目 - Web Server
- 重写 500 Lines or Less 项目 - Template Engine
- 重写 500 Lines or Less 项目 - Continuous Integration
- 重写 500 Lines or Less 项目 - Static Analysis
- 重写 500 Lines or Less 项目 - A Simple Object Model
- 重写 500 Lines or Less 项目 - A Python Interpreter Written in Python
- 重写 500 Lines or Less 项目 - Contingent
- 重写 500 Lines or Less 项目 - DBDB
- 重写 500 Lines or Less 项目 - FlowShop
- 重写 500 Lines or Less 项目 - Dagoba
- 重写 500 Lines or Less 项目 - 3D 建模器