重写 500 Lines or Less 项目 - Contingent
概述
本文章是 重写 500 Lines or Less 系列的其中一篇,目标是重写 500 Lines or Less 系列的原有项目:Contingent: A Fully Dynamic Build System。
在原文中,作者(Brandon Rhodes & Daniel Rocco)首先介绍了面向文档的构建系统(以 Sphinx 为例)面临的问题:它们有时做得太多(即便相关内容并未发生变化,也仍然执行了构建),有时却太少(没有发现本应包含的内容变更,因此内容未能得到及时更新)。然后他编写了一个自己的构建系统来解决以上问题。
在阅读原文时,我首先遇到的一个问题是:尽管作者详细说明了问题出现的场景,但该示例相关的文件并未包含在代码库中,想要自己去复现的话,就不得不手写这些文件。虽然示例文件很简单,不过许多人(包括笔者在内)可能并不是特别熟悉 ReStructuredText 标记格式,因此这个工作还是需要一些额外的努力的。为此,我根据原文的描述自己创建了 Sphinx 项目及相关文件,和代码放在一起,有需要的同学可以参考。
我浏览作者实现的程序发现:该程序作了很多工作去实现诸如检测文件变更、以及生成 graphviz 依赖图等等,目的是为了提供类似 npm watch 和创建示意图,当然这些功能也很有趣和有用,但和前面提出的问题并没有多少直接关系。此外,示例程序的构建目标没有使用问题中提出的 .rst,而使用了一些简化的 .txt 文件(当然也有它自己的格式要求)。因此我觉得,作者的实现离最初的问题是有点距离的。
该程序也设计了一个一般性的、由顶点和边构成的图数据结构,看起来是希望作为一种通用的构建系统基础模型。这当然是合理的,不过对于本项目而言似乎有点大材小用。当我自己尝试编写程序的时候,想到了另外一种思路,即类似编译器那样使用明确的阶段和先后顺序来表示构建过程,不必引入图的结构和算法,也能实现类似的目标,同时在设计上更加简明。因此,本文的实现和原文存在相当大的差异。最终我做了一个大胆的决定:完全抛开原文的思路,按自己的想法去设计。同时为了更加贴近问题,本文也将以问题部分给出的 .rst 文件作为构建目标。
在写作方法方面,还是延续本系列文章的思路,用迭代方法来逐步完成整个项目。我会结合使用自顶向下和自底向上两种思路来实现代码,也希望借此表明,这两种方法并非彼此互斥,而是完全可以、也应当配合使用的。自底向上的部分基本上是以测试驱动的方式(TDD)开发的,而自顶向下的部分则不是,因为我认为(个人意见)测试顶层代码并没有多大意义,而成本却比较高。当然,读者对此可以有不同的看法。
文章结构
本文整体内容如下:
- 提出问题
以一个 Sphinx 项目为例,演示典型的文档构建系统存在的构建“过度” 或“不足”的问题,并分析这些问题是如何产生的;
- 实现原理
在了解问题的基础上,思考如何去解决这个问题,并将本文的实现思路和原文做一对比。
- 代码
接下来进入代码开发环节。本文总体分为以下步骤,依次完成:
- 构建系统的命令行接口
- 实现任务支持
- 解析
.rst文件 - 生成代码模型
- 链接
- 实现增量构建
示例代码
本文及系列文章的所有代码都开源在 Github 仓库:500lines-rewrite。本文相关的代码位于 contingent 目录,在其下为每个阶段创建了单独的子目录。为了避免为每个步骤创建单独的环境,读者可以将主目录下的 main.py 作为入口,并打开相应的注释部分来运行程序。
如果读者想法要自己运行并查看示例的话,需要通过 PIP 安装 sphinx 相关的包。建议的方法是创建 Python 虚拟环境,并运行 pip install -r requirements.txt 命令解决依赖。相信这个操作对本文读者来说应该不成问题。
从解析部分开始,为了验证实现的正确性,每个阶段都包含若干单元测试。根目录下的 main.py 也同样包含了这些单元测试的入口,可以打开相应的注释部分来执行。
为了避免内容过于冗长,文中列出的代码会忽略掉一些注释和导入语句。对于逐步实现的代码,已出现的部分会以 ... 标记,以节约篇幅,相信不会对阅读构成障碍。完整的程序请参考代码库。
问题:文档构建系统
原文对该问题的讲述已经非常详细。唯一的问题是:程序代码中没有提供示例文件,这样我们想要重现问题的话可能会比较麻烦。因此,我重建了示例项目,并放在代码库的 contingent/sphinx-example 目录下。想要自己动手的朋友可以打开该目录来执行操作。
有些读者可能未必熟悉 Sphinx,所以这里先做个简单介绍。Sphinx 本质上是个静态文件构建系统,基于称为 ReStructuredText 的标记格式(有点类似 Markdown 但更加复杂,文件后缀通常为 .rst)生成 html/epub/pdf/chm/latex 等目标格式的内容。它广泛用于项目文档、静态网站、电子书、博客等等,在 Python 社区最为流行。
要构建一个 Sphinx 项目,通常需要以下步骤:
- 通过 PIP 或其他方式安装
sphinx包; - 运行
sphinx-quickstart命令。这是一个基于 CLI 的交互式程序,向用户询问一些问题(如项目名称、目录结构等等),并根据回答创建一个项目的基本骨架; - 用户可以修改向导生成的
.rst文件,或者新增文件; sphinx-quickstart生成的项目包含一个Makefile,因此用户可以通过make [目标格式]命令来生成文件。例如,执行make html会生成 HTML 格式的结果;
和其他构建系统类似,Sphinx 也有一定的智能。当我们修改了部分文件后,它会尝试只重新构建那些可能收到影响的文件,而不是每次都从头开始。本文示例包含以下四个文件:
- index.rst
- api.rst
- install.rst
- tutorial.rst
以 index.rst 为例,它包含若干特殊指令:
Table of Contents
==================================
.. toctree::
install
tutorial
api
toctree 就是一个指令,它会把其他文件的目录结构包含在此文件中。因此,只要以上文件的目录部分(从标题中抽取而得)有所变化,那么 index.rst 也应该重新生成。我们可以尝试一下,比如把 tutorial.rst 标题部分随便做些修改,然后重新运行 make html,应该看到类似这样的输出(忽略次要部分):
写入输出... [ 50%] index
写入输出... [100%] tutorial
它表明对 tutorial.rst 的变动会同时影响 tutorial.html 和 index.html,这个结果是符合预期的。
那么,什么情况下 Sphinx 会做得“太多”?比如说,我们对 tutorial.rst 的正文部分稍作修改,但标题部分不变。此时 index.rst 应该是不受影响的,也无需构建。。但是我们尝试去运行 make html 的话,会发现输出和上面是完全相同的。
这表明 Sphinx 的智慧并不足以区分到底是文档的哪个部分做出了改变,从而浪费了一些无用功。当然,从好的方面说,这样无非是多消耗了一些计算资源,并且也会让整个构建过程变慢,好在结果仍然是正确的。只有在比较大型的项目中才会明显感觉到这种浪费带来的影响。
但另一方面,Sphinx 有时候也会做得“太少”。这种情况虽然不太常见,但应该特别小心,因为它会产生过时的、甚至是错误的结果。
要看到此结果,我们先看看 api.rst,它包含一条指向 tutorial.rst 的特殊指令:
Before reading this, try reading our :doc:`tutorial`!
该指令或插入一个超链接,并以 tutorial.rst 的标题作为文字。因此,如果我们修改了 tutorial.rst 标题的话,那么应该有三个地方受到影响:
tutorial.rst本身index.rst,其 toctree 指令引用了tutorial.rstapi.rst,其包含一个指向tutorial.rst的链接
但是我们再运行 make html 的话,仍然会看到这样的结果:
写入输出... [ 50%] index
写入输出... [100%] tutorial
这显然是不对的。
尽管我们不清楚 Sphinx 的具体实现机制,但是不难猜想,它应该有一个简单的逻辑:只要源文件(比如 api.rst)没有变化,那么它就不需要重新构建。但是我们看到了,这个判断在某些情况下是不成立的:如果文件所引用的外部资源发生了变化,即使文件本身并未变化,也需要重新构建,否则内容就可能过时了。
上述问题在其他构建系统中也是存在的。比如说,有时候配置开关或者环境变量发生了变更,有可能意味着必须重新执行构建,否则结果将是不正确的(当然也不见得总是如此)。但很多构建工具在这个时候会表现得比较“懒惰”——它看到源文件没有变化,就认为什么都不需要做。
解决方法当然也有,且非常古老:提供一个类似 make clean 的命令,删除所有中间结果,重新开始整个过程。简单粗暴,然而有效。
但说到底,这是构建工具不够完善而导致的问题。本文的目标是实现一个“恰到好处”的构建系统————既不过分浪费,也不表现贪婪,总是生成正确且必要的结果。
解决思路
解决问题的方向是明确的。要实现不多也不少、“恰到好处”的构建,我们不能把源文件当作铁板一块,而是必须解析出它的各个组成部分,尤其是那些链接到外部文件的指令,并作为一个依赖关系。当任意一个依赖项发生变化,我们需要重新触发构建。另一方面,如果外部文件内容更新了、但某些特定部分(比如标题)并未改变,这种情况应视为依赖项没有变化,也就不会触发构建。
由此出发,我们可以大致画出该项目的依赖关系(以下示意图出自原文):
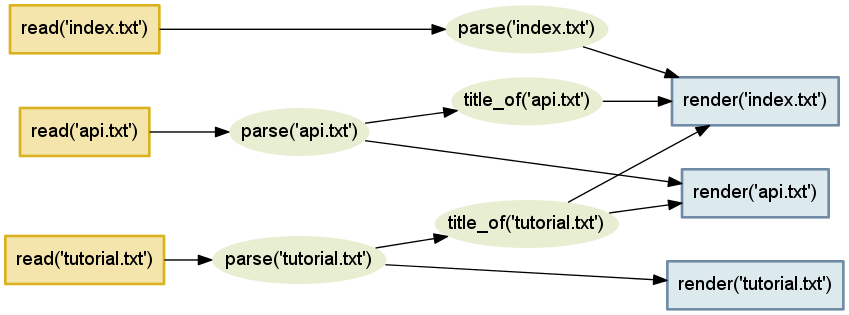
然后是如何实现的问题,从这里开始,本文和原文走向了不同的方向。
如果读者看过原文的话,会发现作者为该项目实现了一个通用的依赖关系结构,即由顶点和边构成的有向图,而构建过程则是对该图依次取边的路径算法。这个思路是正确的,事实上也是大多数通用构建系统普遍采取的做法。该方法一个潜在的问题是:如果图中存在闭合路径(可能是程序 bug,也可能源文件本身就存在循环依赖关系),必须谨慎处理,实现不当的话有可能出现无穷递归(直到堆栈溢出)。
不过在阅读原文的时候我想到:对于文档构建这个目的而言,输入和输出方向都是比较明确的,即便不引入一般性的图结构,用普通的前驱/后续关系也足以描述构建过程。如果不考虑通用性的话,那么完全可以用一个更加简单的思路去设计如下:
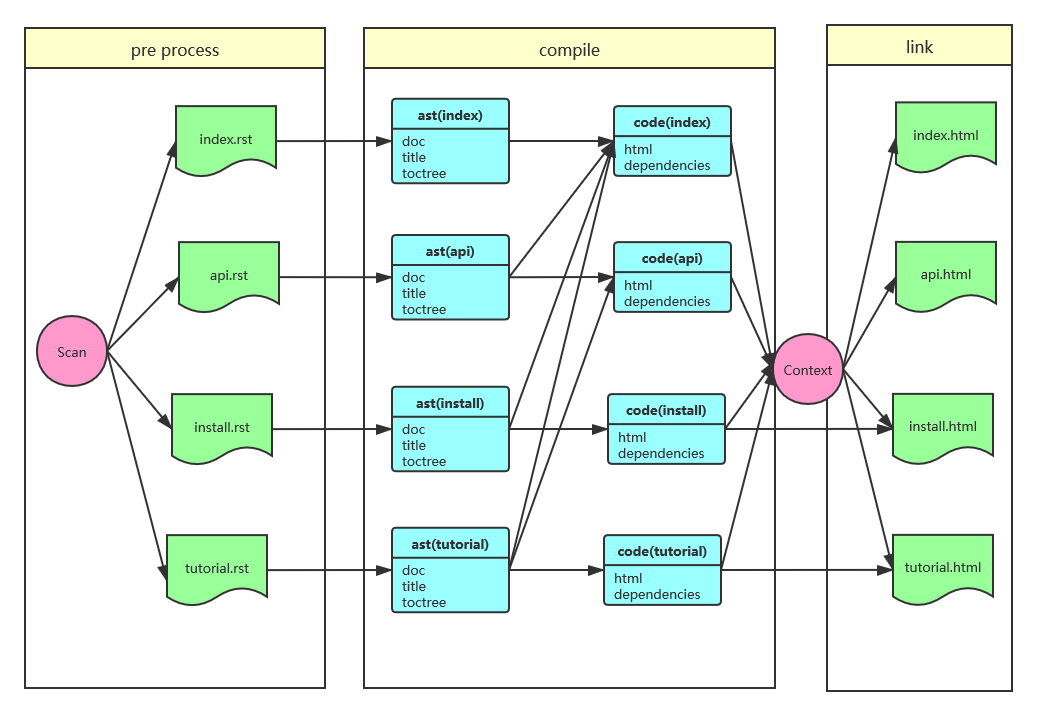
在上图中,我把处理过程分为三个阶段:
- 预处理(pre-process):扫描文档目录,识别出需要处理的文件并排队
- 编译(compile):从源文件生成结构化的、便于生成的数据。如果再细化的话,又可以分为两个步骤:首先将源文件解析成抽象语法树(AST);然后进一步从 AST 生成更接近最终结果的、并且确定了依赖关系的代码模型。
- 链接(link):将从各文件抽取到的信息统一注入全局上下文(Context),输出也从此上下文中获取必要的数据,生成最终的文档(比如 HTML)。
大家会发现,上述过程非常类似常规编译器的工作方式,甚至术语(编译/链接)都是直接借用了编译器的叫法。而原文实现的更类似于 Ant/MsBuild 那样的通用性构建系统。因为处理步骤有明确的先后关系,无须引入有向图算法,所以本文的实现方式在设计上更加简明。当然,这两种方式各自有各自的应用场景,对本文要解决的问题而言,我相信还是类似编译器的方式更加直观明确。
该方法也存在一个潜在的问题:由于在链接阶段需要将大量数据注入上下文,如果处理不当的话,Context 可能会占用大量内存,甚至导致构建失败。如果读者编译过 Qt 或 Chromium 这一类大型软件的话,可能已经见过类似现象了。不过为了支持增量构建,本身设计的 Context 数据会写入文件,而不是纯粹依赖于内存,所以此问题是可以缓解的,并不是很大的缺陷。
下面我们就来动手实现这个构建工具。编程社区常有这样的争论:程序设计可以自顶向下(Top Down),也可以自底向上(Bottom Up),那么在写程序的时候究竟应该采取哪种思路?我希望本文的实现可以说明,这两种方法并不是非此即彼的关系,而是应该共同使用:总体设计明确了自顶向下分解的方向,但是在完成各个小步骤时,我们可以采取自底向上的方式,先实现必要的组件,再把它们拼接起来,以构成完整的系统。
实现
步骤 0:命令行接口
让我们首先从接近用户的层面做起。像其他编译器一样,我们需要给用户提供一个命令行接口。本程序实现三个子命令:
- build(构建文档)
- clean(清除中间结果)
- rebuild(相当于 clean + build)
如果不指定目标的话,则程序应给出类似下面的提示信息:
Usage:
main.py build - Build project
main.py clean - Clean intermediate files
main.py rebuild - Force rebuild
此外,我们假定文档源文件(.rst)和输出文件使用类似这样的目录结构:
- docs
- src
- index.rst
- ...
- cache
- build.cache
- build
- index.html
- ...
以上目标是简单而明确的,所以直接给出实现:
def main():
base_dir = os.path.normpath(os.path.join(os.path.dirname(__file__), '../docs'))
proj = Project(base_dir)
if len(sys.argv) < 2:
proj.usage()
sys.exit(0)
target_name = sys.argv[1]
proj.run(target_name)
我们用一个 Project 类来管理命令行接口,每个子命令实现为类中的方法,并通过 usage() 方法输出帮助信息:
class Project:
def __init__(self, base_dir):
self.src_dir = os.path.join(base_dir, 'src')
self.cache_dir = os.path.join(base_dir, 'cache')
self.build_dir = os.path.join(base_dir, 'build')
self.targets = ('build', 'clean', 'rebuild')
def usage(self):
entry = os.path.basename(sys.argv[0])
print('Usage:')
for target in self.targets:
method = getattr(self, target)
name, doc = method.__name__, method.__doc__
print(f' {entry} {name} - {doc}')
def run(self, target):
method = getattr(self, target)
method()
def build(self):
print('build')
def clean(self):
print('clean')
def rebuild(self):
print('rebuild')
再考虑如何实现这些子命令。rebuild 规则最简单:先 clean 再 build 即可:
def rebuild(self):
self.clean()
self.build()
clean 也很容易实现————删除整个中间目录。但相应地,再生成阶段应该有额外的检查:如果目标目录不存在的话,需要首先创建它们。
def clean(self):
shutil.rmtree(self.build_dir, ignore_errors=True)
shutil.rmtree(self.cache_dir, ignore_errors=True)
print('Cleaned up.')
实现 build 显示是个相当复杂的过程。我们把这个任务留到后面,现在先简单提供一个占位符。从命令行执行一下,看以上这些子命令是否都能正常工作。确认代码没有问题之后,进入下个步骤。
步骤 1:实现任务(Task)
在前述设计中,我们把构建过程分成若干阶段(pre/compile/link),而每个阶段又可以包含一个或多个步骤。不仅各个步骤有着严格的先后顺序,各个阶段之间也是:只有在所有 compile 阶段的任务都已完成后,才能执行 link 阶段的任务,否则部分文件的解析尚未完成,有可能拿不到完整的数据,从而导致构建失败。
按照此设计,我们可以创建如下抽象:
Project可以创建并执行多个任务(Task);- 每个
Task又可以声明自身完成之后要继续执行哪些新的Task; Project依次执行各个阶段的任务。当没有后续任务要执行时,表明该阶段执行完毕,可以转入下个阶段。
在开始写代码之前,还有一个问题需要注意。Project 要管理 Task,但是 Task 又可以往 Project 添加新的 Task————这就形成了双向依赖关系,而双向依赖几乎总是应当避免的。对 Python 来说,双向依赖还有可能造成难以排查的 import error。为了避免此问题,我们首先做个重构,把构建过程需要使用的数据结构提取为一个称为 BuildContext 的类,而 Project/Task 都在 BuildContext 上执行操作,以打破它们的彼此依赖。
现在,把 Project 修改为:
class Project:
def __init__(self, base_dir):
self.ctx = BuildContext(base_dir)
self.targets = ('build', 'clean', 'rebuild')
self.verbose = ('--verbose' in sys.argv)
def build(self):
self.ctx.exec_task(None, Scan())
self.ctx.exec_tasks(self.ctx.compile_tasks)
self.ctx.exec_tasks(self.ctx.link_tasks)
if self.verbose:
for task in self.ctx.executed_tasks:
print(f'executed task: {task}')
以上代码增加了新的一个命令行选项:--verbose,主要目的是方便调试。我们希望确认哪些 Task 被执行了、以及它们的执行顺序是否正确。当使用此开关时,命令行输出会包含已执行步骤的列表;如果一切正常的话,则可以关闭此开关,以使得输出更加整洁。
Task 是一个简单的抽象类,可以看作 Template 设计模式的应用,它具体要如何执行留给子类去解决:
class Task:
def exec(self, ctx: BuildContext):
self.ctx = ctx
self.run()
def run(self):
raise NotImplementedError()
BuildContext 记录构建过程中的必要信息,为 Project/Task 提供一个共享的上下文:
class BuildContext:
"""Manage build process"""
def __init__(self, base_dir):
self.src_dir = os.path.join(base_dir, 'src')
self.cache_dir = os.path.join(base_dir, 'cache')
self.build_dir = os.path.join(base_dir, 'build')
self.compile_tasks = []
self.link_tasks = []
self.executed_tasks = []
def add_compile_task(self, task):
self.compile_tasks.append(task)
def add_link_task(self, task):
self.link_tasks.append(task)
当执行完一个 Task 之后,该 Task 应当从任务列表中移除,同时为了跟踪执行过程,记录到已执行队列:
def exec_task(self, task_list, task):
task.exec(self)
if task_list:
task_list.remove(task)
self.executed_tasks.append(task)
每个阶段有一个任务队列,需要不断执行直到所有任务都完成为止。注意以下代码迭代使用的是列表的副本,而不是列表本身,否则在迭代过程中删除元素会出现问题:
def exec_tasks(self, task_list):
"""execute all until no task pending"""
while task_list:
for task in task_list[:]:
self.exec_task(task_list, task)
这样,任务的基础结构就搭好了。我们来编写初始任务,它的工作是查找所有需要处理的 .rst 文件,并启动后续处理:
class Scan(Task):
def run(self):
for filename in os.listdir(self.ctx.src_dir):
if filename.endswith('.rst'):
self.ctx.add_compile_task(Parse(filename))
self.ctx.add_link_task(Link(filename))
至于其他任务,目前只需要提供一个空的 run() 方法。我们运行一下 main.py build --verbose 命令,检查所有任务是否按照预期的顺序执行了。在下面的过程,我们会依次实现每一个 Task。
步骤 2:解析 RST 文件
ReStructuredText 是一种比较复杂的标记格式,要实现一个完整的解析器在 500 行之内是不现实的。一种可能的方法是利用现成的解析库,比如 docutils,但 docutils 的接口相当复杂,而文档却比较有限。最终我决定自己实现一个刚好能够支持示例文件内容的简版解析器,仅用于示例的目的。
在前面两个步骤(实现命令行接口和任务支持),由于目标简单明确,我采用了直接进入实现的方法,通过命令行去保证程序的正确性。但是对于解析来说,它要完成的工作会比较复杂,完全通过命令行验证有点不太现实。所以,从这个步骤开始,我们采用一种自底向上的方式来开发:将解析器实现为一个组件,通过测试驱动开发(TDD)的方法去逐步完善;等组件功能完备之后,在顶层把功能组织起来,构成完整的程序。这就是自底向上+自顶向下混合使用的思想。
示例的四个 .rst 文件中,install.rst 是最简单的:它只包含一个标题。我们从它入手,先写下一个测试:
from ..parser import parse_file
class ParserTest(TestCase):
def test_parse_install(self, file_name, expected_ast):
file_path = relative_of(__file__, '../../docs/src/install.rst')
ast = parse_file(file_path)
self.assertEqual(ast.dump_ast(), """
doc(install)
h1(Installation)
""".strip())
AST 是一个树型结构,要验证其正确性,如果通过普通的相等性比较,通常难以清楚地看到是哪个层次或节点出现了问题。因此测试把 AST 输出为文本进行比较会更为直观。relative_of 则是一个解析文件具体位置的辅助方法。
为了满足测试,我们需要编写 parse_file 方法,读取文件内容并生成 AST:
def parse_file(file_path) -> AstDoc:
name = os.path.splitext(os.path.basename(file_path))[0]
with open(file_path, 'r') as f:
lines = [x.rstrip() for x in f.readlines()]
doc = parse(name, lines)
return doc
def parse(name, lines) -> AstDoc:
doc = AstDoc(name)
# TODO: parse lines
return doc
AST 是一个树状结构,我们把其中的节点称为 AstNode,每个节点需要记录名称、内容和子节点集合。树的根节点也是一个 AstNode,但它还需要一些额外的方法,比如测试要求的 dump_ast(),所以我们把它单独提取成类。
这里的描述有一点简化。实际上在最初编写该程序时,我的做法是为每种节点都创建单独的子类————毕竟从面向对象的角度看,这是很直观的做法。但代码写到一半我就发现,基本上所有节点的逻辑都非常相似,用太多子类其实毫无必要。所以我又把它“拍扁”,最终只保留了 AstNode 和 AstDoc 两个类:
class AstNode:
def __init__(self, name, data=None):
self.name = name
self.data = data
self.children = None
def append_child(self, child):
self.children = self.children or []
self.children.append(child)
class AstDoc(AstNode):
def __init__(self, data):
super().__init__('doc', data)
要让内容按照层次结构输出,我们创建一个递归遍历子节点的辅助方法,同时每个子节点可以按照所在层次输出自身内容。在最顶层,AstDoc 把所有节点内容合并成单一的字符串:
class AstNode:
def iter(self, depth: int):
yield depth, self
for child in self.children or []:
for descendant in child.iter(depth + 1):
yield descendant
def ast_string(self, depth: int):
indent = ' ' * (depth * 2)
result = f'{indent}{self.name}'
if self.data:
result += f'({self.data})'
return result
class AstDoc(AstNode):
def dump_ast(self):
return '\n'.join([item.ast_string(depth)
for depth, item in self.iter(depth=0)])
那么如何解析文件内容?需要用 Antlr 一类的语法解析器吗?对于示例而言这个路子有点太重了。我决定采用一个比较“土”的办法:对文件执行多遍扫描,每次解析出一种节点:
def parse(name, lines) -> AstDoc:
doc = AstDoc(name)
items = list(parse_headers(lines))
items = list(parse_toctree(items))
items = list(parse_paragraphs(items))
for item in items:
doc.append_child(item)
return doc
扫描过程把 parse_paragraphs() 放到最后,因为除了标题和特殊指令外的文本内容都当作是普通段落。
我不打算详细讲解这部分的代码细节,毕竟本文使用的不是正规的解析器实现,只会稍作说明。例如,parse_headers() 检查文本后面是否紧随 ========= 或 -------,如果是则当作标题处理,否则返回原始内容。
def parse_headers(lines):
index = len(lines) - 1
nodes = []
while index >= 0:
line = lines[index].rstrip()
if set(line) == set('=') and index > 0:
nodes.insert(0, AstNode('h1', lines[index - 1].strip()))
index -= 2
elif set(line) == set('-') and index > 0:
nodes.insert(0, AstNode('h2', lines[index - 1].strip()))
index -= 2
else:
nodes.insert(0, line)
index -= 1
return nodes
对 install.rst 测试通过以后,我们可以继续编写对其他文件的测试,并通过测试完善 parser 的实现。在编写过程中会注意到,所有测试模式都是类似的,因此可以提取出公共方法:
class ParserTest(TestCase):
def assert_parse(self, file_name, expected_ast):
ast = parse_test_file(file_name)
self.assertEqual(expected_ast.strip(), ast.dump_ast())
def test_parse_tutorial(self):
self.assert_parse('tutorial.rst', """
doc(tutorial)
h1(Beginners Tutorial)
p
text(Welcome to the project tutorial!)
p
text(This text will take you through the basic of ...)
h2(Hello, World)
h2(Adding Logging)
""")
当所有四个文件测试都通过之后(请参考 tests/test_parser.py),解析器也就写好了。现在,我们可以添加相关的任务:
class Parse(Task):
def __init__(self, filename):
self.filename = filename
def run(self):
full_path = os.path.join(self.ctx.src_dir, self.filename)
ast = parse_file(full_path)
self.ctx.add_compile_task(Transform(ast))
解析完成之后,还需要进一步将其转换为更接近生成目标的代码模型,这个过程我们把它叫做 Transform,具体实现留给下个阶段来完成。
步骤 3:转换代码模型
以上,我们通过解析源文件生成了 AST 结构,但 AST 还不足以产生最终的输出。我们还需要解决以下问题:
- 特定的 .rst 文件可以输出哪些内容给其他文件?
- 特定的 .rst 文件依赖于其他哪些文件的什么输出内容?
就我们的示例而言,可能的依赖项主要又以下这几种:
- 文档内容本身
- 其他文件的标题(例如 api 引用了 tutorial)
- 导航树(toctree,例如 index 包含其他文件的导航结构)
上述内容中,标题可以视为一个简单的字符串,而文档内容和导航树则比较复杂,通常包含多行内容。依赖项不应该有重复且顺序不重要,最合适的数据类型是 set。因此设计数据结构如下:
class Code:
def __init__(self, name):
self.name = name
self.title = None
self.html = []
self.toctree = []
self.dependencies = set()
在转换之后,程序应该能正确产生各个部分的内容,包括依赖关系。install.rst 最简单,它除了文档本身之外没有其他依赖关系。所以我们编写测试:
class TransformerTest(TestCase):
def test_transform_install(self):
ast = parse_test_file('install.rst')
code = transform('install.rst')
self.assertEqual('install', code.name)
self.assertEqual('Installation', code.title)
self.assertEqual(code.toctree, [ '<ul>', ..., '</ul>' ])
self.assertEqual(code.html, [
'<html>', ..., '</html>',
]))
self.assertEqual(set([
('doc', 'install')
]), code.dependencies)
HTML 片段数量比较多,但内容是很简单的,为了节约篇幅,这里就略过中间部分。
要通过上述测试也不是简单的事,我们还是一个个来。要获得标题很简单:找到 h1 节点,把它的内容当作标题即可。
def transform(doc: AstDoc) -> Code:
code = Code(doc.data)
code.title = doc.title()
return code
这里 title() 是 AstDoc 的一个辅助方法。请记住 iter() 迭代得到的是一个 Tuple[depth, node],所以通过下标取得的才是真正的节点。
class AstDoc:
def title(self):
h1 = find_first(self.iter(0), lambda x: x[1].name == 'h1')
return h1[1].data if h1 else 'Untitled'
接下来是如何生成 toctree。为了生成 toctree,基本上需要两个步骤:
- 找出所有级别的标题
- 将标题按照级别构成嵌套的
<ul>标签
第一步很简单。我们为节点添加辅助方法:
class AstNode:
def header_level(self) -> int:
if self.name in ('h1', 'h2', 'h3', 'h4', 'h5', 'h6'):
return int(self.name[1:])
return 0
class AstDoc:
def headers(self):
return [node for depth, node in self.iter(0) if node.header_level() > 0]
第二步就有点复杂了。比如说,对于如下的标题列表结构:
(h1, 'Title')
(h2, 'Header 1')
(h3, 'Header 1 of 1')
(h3, 'Header 2 of 1')
(h2, 'Header 2')
要生成的 HTML 标签类似这样,是一个嵌套的 <ul> 树:
<ul>
<li>
<a class="toc-h1" href="my.html">Title</a>
<ul>
<li>
<a class="toc-h2" href="my.html#h_1">Header 1</a>
<ul>
<li><a class="toc-h3" href="my.html#h_1_1">Header 1 of 1</a></li>
<li><a class="toc-h3" href="my.html#h_1_2">Header 1 of 2</a></li>
</ul>
</li>
<li>
<a class="toc-h2" href="my.html#h_2">Header 2</a>
</li>
</ul>
</li>
</ul>
因此,这本质上是个递归的过程,此外还包括其他一些附属工作:
- 为每个标题生成一个唯一名称,作为 a 元素引用的名字
- 出于显示目的,应该为每级目录添加一个 CSS 类名
先写出总体代码,并且包含一个内部函数用于实现递归处理:
def transform_toctree(doc: AstDoc, code: Code):
headers = doc.headers()
def transform_toc(index, node):
...
code.add_toctree('<ul>')
for index, node in enumerate(headers):
if node.name == 'h1':
transform_toc(index, node)
code.add_toctree('</ul>')
transform_doc 需要再使用一个辅助方法 get_children() 找到当前节点所属的子节点集合。如果子节点有内容的话,那么再创建一个新的 <ul> 层级,并继续递归下去:
def get_children(index, node):
for sub_index in range(index + 1, len(headers)):
child = headers[sub_index]
if child.header_level() == node.header_level() + 1:
yield sub_index, child
else:
break
def transform_toc(index, node):
cls_name = f'toc-{node.name}'
target = f'{code.html_name()}'
if node.header_level() > 1:
target += f'#{node.slug()}'
li = f'<a class="{cls_name}" href="{target}">{node.data}</a>'
children = list(get_children(index, node))
if children:
code.add_toctree('<li>', li, '<ul>')
for sub_index, child in children:
transform_toc(sub_index, child)
code.add_toctree('</ul>', '</li>')
else:
code.add_toctree('<li>' + li + '</li>')
以上代码还用到了其他一些辅助方法。Code.add_toctree() 用来将多个 HTML 片段添加到自身的 toctree 集合,而 node.slug() 用于生成节点的唯一名称。这些实现都比较简单,有兴趣的同学参考代码即可。
接下来是一个更大的工程:将 AST 文档部分转换成 HTML 内容。这已经接近最终输出结果了,但还不是完全的 HTML,因为部分来自其他文件的动态内容需要在链接时刻才能确定。
HTML DOM 也是一个树状结构,把 AST 树转换成 DOM 树需要相当复杂的处理。这就是 Visitor 设计模式出场的时候了。我们创建一个 CodeVisitor 类,把对各个节点的处理映射到对应的方法:
class CodeVisitor:
"""Visit structure of ast model to generate code"""
def __init__(self, code: Code):
self.code = code
def visit(self, node: AstNode):
getattr(self, node.name)(node)
def visit_children(self, node: AstNode):
for child in node.children or []:
self.visit(child)
接下来的工作就是实现对各种节点的访问。例如,要生成整个 HTML 的基本结构,添加方法如下:
def doc(self, node: AstNode):
self.code.add_html('<html>',
'<head>',
f'<title>{node.title()}</title>',
'</head>',
'<body>')
self.visit_children(node)
self.code.add_html('</body>',
'</html>')
self.code.add_dependency('doc', node.data)
而对标题的处理相当简单:
def h1(self, node: AstNode):
self.code.add_html(f'<h1>{node.data}</h1>')
测试会告诉我们哪些节点还未得到支持;只要继续添加对节点的处理,直到测试通过为止。
对 install.rst 测试通过后,我们用类似的方法继续添加对其他文件的测试。还记得吗?api.rst 涉及到对 tutorial.rst 的引用,而这个依赖在当前的编译阶段是无法确定下来的。为此,我参考 Jinja2 模板的语法规则设定这样的处理:如果字符串内容类似 {{ expr(arg1, arg2) }},则当作表达式,在链接阶段动态执行并生成最终结果。
所以,对 api.rst 编写测试类似这样:
def test_transform_api(self):
code = transform_test_file('api.rst')
self.assertEqual(code.html, html_lines('API Reference', [
...
'<a href="tutorial.html>',
'{{ ctx.get_title("tutorial") }}',
'</a>',
...
]))
self.assertEqual(set([
('doc', 'api'),
('title', 'tutorial')
]), code.dependencies)
对应节点访问方法:
def a(self, node: AstNode):
target = f'{node.data}.html'
self.code.add_html(f'<a href="{target}>',
f'{{{{ ctx.get_title("{node.data}") }}}}',
'</a>')
self.code.add_dependency('title', node.data)
我们预期 BuildContext 应该增加一个 get_title() 方法,用来从其他文件获取标题。不过这个方法可以留给链接阶段再去实现。另外,{} 对格式化字符串来说有特殊含义,所以这里的四重大括号实际上会被解释为 {{ }}。
最后我们要实现对 index.rst。它所需要的 toctree 也是一个动态表达式,方法和上述过程基本类似,这里就不再赘述了。
现在代码模型已经完成,我们还需要实现一个任务:把解析到的内容写入 Context 以备后续处理,更具体地说,应该写入文件,这样才能保证每次构建时不是从头来过。
因为 BuildContext 本身已经比较复杂了,所以我们把读写文件的任务委派给另一个类:CacheFile。还是写一个测试:
class CacheFileTest(TestCase):
def test_load_save(self):
file_path = relative_of(__file__, '../../docs/cache/test.cache')
save_file = CacheFile(file_path)
save_file.purge()
dependencies = set([('doc', 'install')])
save_file.set_dependencies('install', dependencies)
save_file.set_code('doc', 'install', ['1', '2'])
save_file.save()
load_file = CacheFile(file_path)
self.assertEqual(dependencies, load_file.get_dependencies('install'))
self.assertEqual(['1', '2'], load_file.get_code('doc', 'install'))
我考虑了一下如何选择文件格式。想要方便调试的话,用 json 会比较容易,但问题是 json 没有直接的方法可以支持 Python 中的 set。最终我决定,鉴于这里要读写的都是常规数据类型,所以用 pickle 来实现是最方便的。
class CacheFile:
def __init__(self, path):
self.path = path
self._data = {
'dependencies': {},
'code': {}
}
if os.path.exists(path):
self.load()
def load(self):
with open(self.path, 'rb') as f:
self._data = pickle.load(f)
def save(self):
os.makedirs(os.path.dirname(self.path), exist_ok=True)
with open(self.path, 'wb') as f:
pickle.dump(self._data, f)
现在我们为 Code 添加一个辅助方法,让它把内容保存到 CacheFile:
class Code:
def write_cache(self, cache: CacheFile):
cache.set_dependencies(self.name, self.dependencies)
cache.set_code('doc', self.name, self.html)
cache.set_code('title', self.name, self.title)
cache.set_code('toctree', self.name, self.toctree)
为 BuildContext 增加 Cache 支持:
class BuildContext:
def __init__(self, base_dir):
...
self.cache = CacheFile(os.path.join(self.cache_dir, 'compile.cache'))
最后,实现任务:
class Transform(Task):
def __init__(self, ast: AstDoc):
self.ast = ast
def run(self):
code = transform(self.ast)
self.ctx.add_compile_task(WriteCache(code))
class WriteCache(Task):
def __init__(self, code: Code):
self.code = code
def run(self):
self.code.write_cache(self.ctx.cache)
self.ctx.cache.save()
为了让任务更加单纯,我选择把“转换模型”和“写入数据”分成两个不同的步骤。WriteCache 之后就不需要再添加新的任务————编译阶段到此完毕,接下来要到链接了。
步骤 4: 链接
在编译阶段,我们几乎已经把 .rst 内容转换成了真正的 HTML 内容,只是其中可能还包含一些依赖于其他文件的动态表达式,需要在链接阶段解析出最终结果。
但我们还是用测试来驱动这个过程。install.rst 不包含外部依赖,只取决于文档自身内容,所以是个很好的入口点。但是在执行之前,要先保证其他文档已经通过编译:
def pre_link(ctx: BuildContext, file_name):
ast = parse_test_file(file_name)
code = transform(ast)
code.write_cache(ctx.cache)
def link_test_file(file_name):
base_dir = relative_of(__file__, '../../docs')
ctx = BuildContext(base_dir, cache_name='test.cache')
pre_link(ctx, 'index.rst')
pre_link(ctx, 'install.rst')
pre_link(ctx, 'api.rst')
pre_link(ctx, 'tutorial.rst')
ctx.cache.save()
return list(link(ctx, get_name_prefix(file_name)))
class LinkerTest(TestCase):
def test_link_install(self):
self.assertEqual(link_test_file('install.rst'), html_lines('Installation', [
'<h1>Installation</h1>',
]))
这里 html_lines() 是一个辅助方法,由于生成的 HTML 总是包含基本固定的头部/尾部标签,该方法可以大大简化测试代码。
由于不需要额外的工作,上述测试很容易通过:
def link(ctx: BuildContext, name):
for line in ctx.cache.get_code('doc', name):
yield line
接下来考虑 api.rst。它包含一个到 tutorial 的链接,最终应该生成类似这样的结果:
def test_link_api(self):
self.assertEqual(link_test_file('api'), html_lines('API Reference', [
...
'<p>',
'<a href="tutorial.html>',
'Beginners Tutorial',
'</a>',
'!',
'</p>',
...
]))
为实现该测试,我们需要找出 HTML 片段中的表达式,并且动态执行它们,以得到结果。我们创建的表达式都需要一个名为 ctx 局部变量,表示 BuildContext。表达式的结果可能是单个字符串(如 ctx.get_title()),也可能是字符串列表(ctx.get_toctree()),所以要区分处理这两种情况。
修改如下:
def link(ctx, name):
for line in ctx.cache.get_code('doc', name):
for result_line in get_output_lines(ctx, line):
yield result_line
def get_output_lines(ctx, line):
if line.startswith('{{') and line.endswith('}}'):
expr = line[2:-2].strip()
result = eval(expr, {}, {'ctx': ctx})
if isinstance(result, str):
yield result
elif isinstance(result, Iterable):
for item in result:
yield item
else:
raise ValueError(f'Expected either str of list[str]', result)
else:
yield line
我们还要为 BuildContext 增加要调用的方法:
class BuildContext:
def get_title(self, name):
return self.cache.get_code('title', name)
def get_toctree(self, name):
return self.cache.get_code('toctree', name)
这样,所有测试都可以通过了。最后实现 Link 任务:
class Link(Task):
def __init__(self, filename):
self.name = get_name_prefix(filename)
def run(self):
lines = link(self.ctx, self.name)
lines = [x + '\n' for x in lines]
html_name = self.ctx.get_build_path(self.name, '.html')
os.makedirs(os.path.dirname(html_name), exist_ok=True)
with open(html_name, 'w') as f:
f.writelines([x + '\n' for x in lines])
看起来有点复杂,实际上大部分是简单的文件处理。虽然 HTML 不在乎换行,但是万一出现问题的话,多行文本还是比挤成一坨的大块文本容易检查,所以在输出 HTML 时会增加必要的换行。get_name_prefix() 方法取得文件名不带扩展名的部分,用来区分要处理的文件名称。
我们现在可以用命令行执行 main.py build 或 main.py rebuild,如果一切正常的话,会看到 docs/build 目录下已经生成了 HTML 文件!用浏览器打开文件,也完全可以正常浏览。(当然,显示效果有点过于朴素,不过这个例子不打算涉及 .css 和网页设计的话题)
我们现在距离胜利只有一步之遥了。还记得当初的目标吗?我们要实现不多不少、刚好足够的构建,而不是每次从头开始。这是下一步的任务:增量构建。
增量构建
为了避免不必要的工作,加快构建速度,我们需要实现:
- 不论源文件、最终结果还是中间产物,都需要带有时间戳,这样我们可以知道它们是何时创建或修改的。当然,文件本身就带有修改时间,所以我们要实现的是为缓存内容记录时间;
- 对于缓存内容,如果内容没有变化的话,那么时间戳也不应该变化;
- 各个步骤,如果可能的话,要检查输入和输出的时间戳。如果输出尚不存在、或者早于任一输入项的时间,则应该再次执行;否则,可跳过此步骤。
为此,我们再增加两个测试,检查它是否能够正确记录时间戳:
class CacheFileTest(TestCase):
def test_set_twice_timestamp_updated(self):
self.file.set_code('doc', 'install', ['1', '2'])
self.file.save()
timestamp1 = self.file.get_code_timestamp('doc', 'install')
time.sleep(0.1)
self.file.set_code('doc', 'install', ['1', '2', '3'])
self.file.save()
timestamp2 = self.file.get_code_timestamp('doc', 'install')
self.assertTrue(timestamp2 > timestamp1)
def test_set_same_content_stamp_unchange(self):
self.file.set_code('doc', 'install', ['1', '2'])
self.file.save()
timestamp1 = self.file.get_code_timestamp('doc', 'install')
time.sleep(0.1)
self.file.set_code('doc', 'install', ['1', '2'])
self.file.save()
timestamp2 = self.file.get_code_timestamp('doc', 'install')
self.assertEqual(timestamp1, timestamp2)
这里用到了 time.sleep() 将时间稍微延迟一下。一般来说,在代码中使用 sleep() 是不好的做法,因为它表明执行结果依赖于特定的时序。但这里的目的只是为了避免代码运行太快、导致本应不同的时间判定为相同,所以是可以接受的。
为了通过测试,我们需要把 CacheFile 修改一下。它原本将数据记录为单一的值,现在则需要改成 Tuple(data, timestamp),在访问时也要通过下标。此外还增加了一个获取时间戳的方法:
class CacheFile:
def set_code(self, kind, name, data) -> bool:
dic = self._data['code']
key = (kind, name)
curr_data, timestamp = dic.get(key, (None, None))
if curr_data == data:
return False
dic[key] = (data, datetime.now())
return True
def get_code(self, kind, name):
key = (kind, name)
return self._data['code'][key][0]
def get_code_timestamp(self, kind, name) -> datetime:
key = (kind, name)
if key in self._data['code']:
return self._data['code'][key][1]
return None
测试通过后,我们可以修改任务的执行逻辑,增加对时间戳的检查。默认的实现仍然假定所有任务都是需要执行的,如果允许跳过的话,子类应该增加自己的判断逻辑:
class Task:
def exec(self, ctx: BuildContext) -> bool:
self.ctx = ctx
if self.is_outdated():
self.run()
return True
return False
def run(self):
raise NotImplementedError()
def is_outdated(self) -> bool:
return True
新增方法 is_outdated() 用于判断内容是否过期,具体的判断逻辑交由子类去实现。
BuildContext.exec_task() 方法也稍作修改,只有 exec() 返回 True,才增加到已执行列表:
def exec_task(self, task_list, task):
if task.exec(self):
self.executed_tasks.append(task)
if task_list:
task_list.remove(task)
现在依次检查各个任务,如果有需要就重载 is_outdated() 实现。比如说,如果缓存内容已经生成、且源文件并未改变,那么就不需要再次解析:
class Parse(Task):
def is_outdated(self) -> bool:
name = get_name_prefix(self.filename)
in_timestamp = self.ctx.get_src_timestamp(self.filename)
out_timestamp = self.ctx.cache.get_code_timestamp('doc', name)
return self.is_outdated_timestamp(in_timestamp, out_timestamp)
def is_outdated_timestamp(self, in_timestamp, out_timestamp) -> bool:
return (out_timestamp is None) or (out_timestamp < in_timestamp)
Transform 和 WriteCache 不需要修改————如果需要重新解析的话,那么后续步骤总是要执行的。Link 则更加复杂一些,它需要判断所有外部依赖是否有变化:
class Link(Task):
def is_outdated(self) -> bool:
out_timestamp = self.ctx.get_build_timestamp(self.name + '.html')
for kind, name in self.ctx.cache.get_dependencies(self.name):
in_timestamp = self.ctx.cache.get_code_timestamp(kind, name)
if self.is_outdated_timestamp(in_timestamp, out_timestamp):
return True
return False
现在我们可以试试效果了。比如说,我们可以先执行一次 rebuild,再执行 build,同时用 --verbose 开关检查有哪些任务被执行了。正常情况下,你应当会看到除了 Scan 之外的所有任务都会跳过(所以速度很快!)
如果你感兴趣的话,还可以按照前述问题描述的步骤执行一次,看调用的步骤是否符合预期。
总结
在本文中,我们以和原文大相径庭的方式实现了文档构建系统 contingent。原文采用的是一种通用的有向图数据结构和相关算法,此外还涉及到跟踪文件变更、输出依赖关系图等附属功能。本文则用接近编译器的 compile + link 分阶段方式,不涉及附加任务。当然也要承认,原文实现的文件跟踪和图形输出功能尽管和问题不太相关,但是也很有趣,如果读者感兴趣的话,可以阅读原文及示例代码,去了解这些功能是怎么实现的。
本文也尝试结合自顶向下和自底向上两种设计思路,共同完成一个完整的程序。我个人的看法是,在现实中只要是超过一定复杂度的程序,基本上不太可能只用一种思路去完成,总是要两个方向配合实现的,只是从哪里开始、到何处结合,根据个人喜好和实际要求,每个人的取舍可能会有所不同,但这并不是一个二选一的问题。
本文的实现也有很多可以改进的地方。首要的问题是,本文实现的解析器是一个比较粗糙和低效的版本,只能解析很少数的 RST 格式和指令,但要做出一个真正完整的解析器又明显超出了范围。如果读者有此雄心的话,不妨参考 docutils,或者用 Antlr 之类的工具自己制作一个。
另一个潜在的优化方向是性能。为了简单起见,本文实现的所有步骤都是顺序执行的,但从前面的示意图可以看出,各个文件的解析彼此之间并无依赖关系,它们完全是可以并行执行的;在链接阶段,上下文的数据只需要读取而无需变更,因此各个步骤也是完全可以并行的。在大型项目中如果能够充分利用并行处理,对于提高构建速度是很有好处的。如果读者有兴趣的话,也不妨尝试把该程序改写成支持并行处理的版本。
文章索引
- 重写 500 Lines or Less 项目 - 前言
- 重写 500 Lines or Less 项目 - Web Server
- 重写 500 Lines or Less 项目 - Template Engine
- 重写 500 Lines or Less 项目 - Continuous Integration
- 重写 500 Lines or Less 项目 - Static Analysis
- 重写 500 Lines or Less 项目 - A Simple Object Model
- 重写 500 Lines or Less 项目 - A Python Interpreter Written in Python
- 重写 500 Lines or Less 项目 - Contingent
- 重写 500 Lines or Less 项目 - DBDB
- 重写 500 Lines or Less 项目 - FlowShop
- 重写 500 Lines or Less 项目 - Dagoba
- 重写 500 Lines or Less 项目 - 3D 建模器