重写 500 Lines or Less 项目 - DBDB
概述
本文章是 重写 500 Lines or Less 系列的其中一篇,目标是重写 500 Lines or Less 系列的原有项目:DBDB: Dog Bed Database。
原文主要目的是演示如何实现一个键值对(K-V)数据库,并设定了以下这些要求:
- 允许快速访问任意用户设定的键
- 可包含海量数据————这意味着不能假定所有内容都位于内存中
- 基于不可变(immutable)数据的原则进行设计
作者在文章开头也解释了这些想法的来源。比如,不可变设计的思想是受到 Erlang 语言的影响。Erlang 以其稳定的并发模型和 Let it crash 哲学而闻名,各个轻量级进程之间不允许共享数据,只能通过发送消息来互相通信。而对内存的限制则来自早期 BASIC 编程期间的经历:太大的程序会占用显存,这时如果执行清屏操作的话,会导致程序被截断————这种问题对于今天的程序员来说恐怕很难想象了吧。这些“上古时代”的小故事读来也是蛮有意思的。
作者的文章写法和本系列的其他文章有所不同。他并没有讲述自己是如何写出这个程序的,而是直接给出最终实现,再告诉我们他自己的设计思路是什么。之所以采取这种方式,按照他的说法,是因为 “读代码” 才是程序员大多数时间要做的事情。从理念上讲,我是认同这个说法的,不过即便知道作者的意图,我在对照看源码的时候还是感觉有不少困惑。这一方面是因为原文对代码部分的讲解还是略显单薄,有些细节的含义需要自己去猜测;此外,从 Github 代码库中可以发现一些关于存储结构的草图,这些图对于理解 Storage 的工作原理是很有帮助的,但不知道为什么作者没有把这些图包含在文章中(见下图):


另一方面,在我尝试重写这个程序之后(其中部分还经过了重写)回头看,可以说更加清楚地理解了作者的一些思路,但对于该程序的总体设计却有不同的意见。作者的意图是想要实现逻辑实现和物理结构的分离,但最终实现却呈现出一个比较紧耦合的状态,上下层之间的隐式关联和假定较多,往往需要来回跳转才能理清某个调用的顺序,个人觉得是不太合理的。
因此,本文希望在参考原文的需求和基本原理基础上,按照自己的思路从头开始实现。在开始编码之前,我们还是首先整理一下需求,在此前提下形成一个明确的设计方案。
需求分析
回想一下原文提出的一些要求:
允许快速访问任意用户设定的键
这个要求似乎很简单:对 K-V 访问来说,用哈希表是最直观的解决办法。同时这是几乎内置于所有现代语言的数据结构,也完全满足快速随机访问的要求,似乎是完美的解决办法。但是且往下看...
允许包含海量数据,不能假定所有内容都位于内存中
问题来了。为了限制内存使用,我们需要有一种机制把暂时用不到的数据保存到持久化存储(磁盘)中。但哈希表却是为内存访问而设计的,没有简单的办法可以把部分内容转移到磁盘。一种思路是把值持久化,而键保留在内存中,不过即便如此,海量的键还是有可能超出内存的限制。
解决办法是参考现代数据库的解决方案,也是数据结构课程的常规内容:二叉树。(实际上数据库使用的是更为复杂的结构,如 B+ 树或红黑树,但作为500行以内的示例程序而言,二叉树已经足够好了。)
与读者可能在数据结构课程上学过的常规二叉树相比,本文涉及的问题会更为复杂一些。主要在于,一般数据结构课程基本上不需要你去考虑它在磁盘上如何存放的问题,但对于本文目的而言,既要考虑它的内存结构,同时也要考虑存储格式问题。
二叉树(以及其他变种)有一个特点是非常有利于存储的:对节点的访问总是从根节点开始。因此,我们可以在一开始只加载根节点,其他的节点则在访问到的时候按需加载即可。这样依赖,我们对存储方案应该大体上有思路了。不过且别忙,再继续看下个要求,它对存储结构的设计也有着重大影响。
基于不可变(immutable)数据的原则进行设计
在文章开头提到过:原作者基于 Erlang 的使用经验使他意识到,不可变对象会使得程序设计更加简单、不易出错,而且对于并发也更加友好。这正是现在很多前卫开发者推崇函数式编程的重要原因。
遗憾的是,大多数现行的数据结构课程都没有采用不可变的设计,而是使用初学者更容易理解、但也更容易出错的命令式风格。反过来说,这也让本文的示例程序更具有现实意义,让我们看到不可变的理念是如何影响设计的。
以下示意图有助于帮我们理解:分别用可变和不可变两种风格如何对二叉树进行变换操作,以及两种方式各自的利弊。
![]()
对于可变风格而言,修改二叉树基本上就是一个修改指针的操作。看起来该方式既简单又高效,但在并发环境下却有一个明显问题:为了避免修改冲突就需要加锁,这使得它的实际性能大为下降,并且有同学应该会理解,要把并发程序编写正确(以及如何通过调试重现并发相关的问题)是多么困难。而不可变对象则完全避开了这个缺陷:它们总是可以安全地共享,不必担心访问冲突带来的问题。当然也有一个潜在的问题是,有时访问端可能会看到“过期”的数据。这在数据库中一般被归为“事务隔离级别”的概念,需要在性能和一致性之间进行权衡,并且往往需要开发者介入,不能指望完全依靠数据库系统去解决该问题。
在我初次接受函数式编程概念的时候,尽管能够从理论上接受它的好处,但也有一个疑问:如果任何变化都要重新创建对象,对内存的占用是否会大到无法承受?结合上图来看的话,只要有变化的节点都要新建,的确要比命令式编程的内存消耗要更大,但也绝非需要从头创建整个树(那样的话的确太恐怖了)。如果使用 B+ 树作为数据结构的话,这个消耗还会更少。因此,不可变设计确实会带来额外的开销,但在大多数情况下内存消耗并不会非常离谱。
在我们设计存储结构的时候,也必须把不可变因素考虑进去。对节点进行变换会产生新的对象,如果频繁搬移它们的位置显然会带来沉重的 IO 压力,也容易导致磁盘碎片的出现。对此问题,我们采用一个简单的思路:每次新生成节点,就将它们写入新的地址,原有内容会变成“孤儿”。显而易见,这样长期下来会累积很多不再使用的垃圾数据。这也是许多数据库系统要面临的现实问题:为了快速存储,往往要牺牲掉一些空间,要回收这些空间则需要额外的操作。在 Postgresql 中,压缩和回收空间的操作叫做 vacuuming。其他许多数据库也存在类似的概念,但具体细节方面差别很大。回收空间通常会带来大量 IO 操作,要尽量减轻其对运行中系统的影响还是需要相当的技巧的。鉴于其复杂性,我们在该示例程序中暂时不考虑它。
考虑到以上这些设计要求,现在对于系统结构和存储方案可以有一个明确的思路。读者可以结合下图理解。
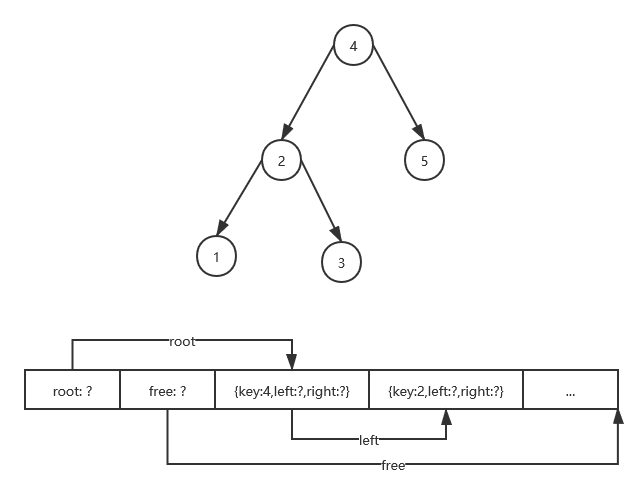 )
)
本文要实现的 K-V 数据库在内存中的存储结构总体上是一棵二叉树。为了能够存储海量数据,并不会把所有内容全部都加载到内存中,而是在开始的时候只加载树的根节点。因此,该数据库的存储结构首先也需要一个指向根节点的指针。
包括根节点在内,所有节点在加载时应包括以下内容:
- 节点的键;
- 指向值的指针(必须存在);
- 指向左节点的指针(若不存在则为0);
- 指向右节点的指针(若不存在则为0);
二叉树对节点的访问总是从根节点开始的。和节点的键进行比较,如果小于它则访问左节点,大于则访问右节点,这样向下构成一个递归的过程。因此,当访问某个特定节点时,我们可以根据地址先从磁盘上加载该节点,然后继续访问。这就是延迟加载的思想,通过它我们可以只使用少量的内存,而存储海量的数据。
反过来说,在保存数据时,我们需要首先在磁盘上找到一块可用空间,把节点内容记录下来(因此需要一个指向可用空间的指针);然后把存储地址记录到父节点的左节点或右节点地址。回想一下,只要某个节点有变化,它的所有上级节点都需要重新生成,因此这是一个递归向上的过程。
对该设计可能会有的一个疑问是:既然节点必须同时有 key 和 value,那么为什么 value 也要通过指针间接访问,和 key 一起存储不是更简单吗?答案是,当遍历树去查找子节点时,通常需要访问多个中间节点,而这些中间节点的值对于本次查找是无关紧要的。对于 K-V 存储来说,值可能会是很大一块数据(比如序列化的完整对象),从磁盘上加载它是非常消耗 IO 的,对于性能敏感的应用能避免则避免。除此之外,它也带来了其他一些有趣的可能,比如对于重复的值可以只存储一份,以节省空间并有利于提高性能。顺便说下,这也是列式数据库的主要卖点之一,因为现实中的数据库确实会有部分列存在大量重复内容,避免重复存储可以带来很大的收益。当然,列式存储又是一个很大的话题,这里就不再展开谈了。
想法有了,接下来就是通过程序去实现它。
按照原文章作者的写作方法,他的意图是引导我们去阅读其代码,然后理解他的设计意图。说实话,虽然通过阅读文章我能够形成一个总体的概念,但在参照文章去阅读代码时很多细节地方还是不明所以,只有在自己从头实现一遍之后,这些问题才有了答案。因此,本文还是按照我自己的思路,把整个程序的实现过程分步骤呈现出来,让读者看到该程序是如何一步步写出来的。
由于该程序编写过程中会有几次大的重构,因此我也编写了不少测试代码,来为重构过程提供一个安全防护网。不过,我假定读者已经对二叉树算法有基本的了解,因此本文不会花太多篇幅来讲解算法的原理;同时,测试主要目的也是为了保证重构,程序本身主要并不是以 TDD 的方式实现的。这是因为,本文的核心算法是通过一个明确的设计过程思考确定的,而不是在写代码的过程中逐渐“浮”出来的,因此 TDD 的方式对于本程序而言作用确实比较有限。
如果读者有兴趣参考实现代码的话,还是按照本系列的老规矩,在 Github 代码库的根目录下有 main.py,找到 DBDB 部分,按照需要打开各个部分的注释并执行即可。需要说明的是,本系列各个文章视其具体需要有时候会引用一些第三方库,比如本文为了给文件加锁就使用了名为 portalocker 的库。每个项目需要的库各自不同,所以它们分别有自己的 requirements.txt,要运行程序的话,建议为它们创建彼此独立的虚拟环境,并按照 data_store/requirements.txt 去初始化它。
以下,我们分步骤实现这个程序。
实现
步骤0:二叉树
数据库在内存中的形式是一棵二叉树。这是核心的数据结构,具备一定复杂性,同时对外界依赖较少,容易进行测试,因此很合适作为程序的入手点。
首先设计节点的数据结构:
class Node:
def __init__(self, key, value, left=None, right=None):
self.key = key
self.value = value
self.left = left
self.right = right
目前,二叉树只需要一个指向根节点的指针就够了,且最初是没有任何节点的。既然采用了不可变的设计思想,我们可以把变换树的算法设计成函数,这样树本身可以极其简单:
class BinaryTree:
def __init__(self):
self._root = None
def get(self, key):
node = find(self._root, key)
return node.value
def set(self, key, value):
self._root = insert(self._root, key, value)
def delete(self, key):
self._root = remove(self._root, key)
查找节点是一个普通的递归向下操作:
def find(node, key) -> Node:
if node is None:
raise KeyError(f'Key not found: {key}')
elif node.key == key:
return node
elif key < node.key:
return find(node.left, key)
else: # key > node.key
return find(node.right, key)
本示例和一般数据结构课程相比,独特之处在于数据结构是不可变的(考虑到延迟加载的因素,也并非绝对的不可变)。因此,插入操作并不修改原有数据,而是通过变换生成新的节点:
def insert(node: Node, key, value) -> Node:
if not node:
return Node(key, value)
elif key < node.key:
return node.transform(left=insert(node.left, key, value))
elif key > node.key:
return node.transform(right=insert(node.right, key, value))
else: # key == node.key
if node.value == value:
return node
return node.transform(value=value)
因为节点的值以及左/右节点都有可能变化,所以为 Node 增加一个辅助方法来执行变换:
class Node:
def transform(self, **kwargs):
return Node(self.key,
value=kwargs.get('value', self.value),
left=kwargs.get('left', self.left),
right=kwargs.get('right', self.right))
删除(remove)节点操作是最复杂的,它需要考虑到许多情形:
- 删除叶子(末端)节点
- 删除只有左子树的节点
- 删除只有右子树的节点
- 删除左/右子树都存在的节点
前三种处理很直观也比较容易理解。在最后一种情况下,我们在目标的左子树中找到一个键最大的节点,把它作为新的子节点,并把移除该节点后的子树挂上去。当然,因为二叉树的对称性,选择右子树来变换也是可以的。这个过程用语言来讲可能不大容易理解,如果读者觉得有点困难的话(像我一样),可以找张纸画一画,或者参考网络上讲述比较细致的资料。鉴于代码分支较多,就不再占用文章篇幅了,读者可以参考代码库中 data_store/step00_binary_tree 部分的实现。
为了确认实现是可行的,我也增加了一些单元测试,这些测试统一放在 tests 包中。测试范围基本上参考了原文的代码,当然二叉树部分和作者的实现差别很大,有兴趣的读者也可以对照着来看,如果觉得原作者的实现更好的话,没有关系 :)
步骤1:引用
在上个步骤中,我们实现了二叉树的访问逻辑,但所有处理都是通过直接的内存访问。这并不是我们最终想要的效果,不过每次专注于一个核心任务有助于帮助我们保持焦点,一小步一小步地稳固推进。在储存和加载数据之前,我们需要对原有的数据结构进行改造,让它可以基于指针进行间接访问。
把值访问改成指针访问从概念上讲并不难,但结构的变化几乎影响到所有代码,工作量(不严格地)几乎等于重写。要想尽量缩小改动范围,避免大量重写当然也是有办法的,这就是面向对象的封装概念发挥作用的时候。
指向值或节点的指针无论从概念上还是用法都是相似的,但在具体访问时还是有所差别。意识到这一点,我们可以把公共部分提取成一个简单的基类,称为引用(Ref),并在此基础上针对值和节点两种引用类型:
MISSING = object()
ADDR_NONE = 0
class Ref:
def __init__(self, addr=ADDR_NONE, target=MISSING):
assert isinstance(addr, int)
self.addr = addr
self.target = target
def get(self):
assert self.target is not MISSING
return self.target
class ValueRef(Ref):
pass
class NodeRef(Ref):
pass
Ref 可以接收两个参数:指向存储位置的指针以及实际值。这实际上包含了两种不同的访问方式:当新建节点时,我们需要指定值,但尚未确定存储地址;而从磁盘中加载时则采用延迟策略,只读取地址到内存中,后续真正访问值的时候再从地址加载数据。读者可能会注意到这里我添加了几个 assert,主要是因为两种不同的访问路径很容易误用,特别是对于 Python 这种缺乏编译时检查机制的语言,多做一些检查有助于尽早定位问题,免得错误扩散。
读者可能也会注意到,我为参数的默认值指定了一个名为 MISSING 的特殊常量。为什么不用 None 呢?这是因为对于 K-V 数据库来说,值为 None 是完全合法的,我们不能把它作为尚未加载的标志。目前我们还没有涉及加载/保存数据的问题,但还是保留了地址(addr)参数,这是为了保证调用参数是正确的,免得以后添加 addr 参数的时候又要再检查一遍。
现在可以把节点改为基于引用的访问:
class Node:
def __init__(self, key, value_ref: ValueRef,
left_ref: NodeRef = None,
right_ref: NodeRef = None):
assert isinstance(value_ref, ValueRef)
assert left_ref is None or isinstance(left_ref, NodeRef)
assert right_ref is None or isinstance(right_ref, NodeRef)
self.key = key
self.value_ref = value_ref
self.left_ref = left_ref
self.right_ref = right_ref
基于同样的原则,多做一些校验以保证传入的参数是符合预期的。不然不难预想到,当构造函数改变之后,创建节点的地方肯定也是要跟着变的,如果初始化的时候不能及时发现问题,以后就很难确定错误的数据到底是从哪里来的。
现在节点结构已经变了,那么之前访问 value/left/right 的地方必须全部重写呢?这时封装技术就有用武之地了:
@property
def value(self):
return self.value_ref.get()
@property
def left(self):
return NodeRef.get_node(self.left_ref)
@property
def right(self):
return NodeRef.get_node(self.right_ref)
就像名言所说的那样:编程中的任何问题都可以通过引入一个额外的间接层来解决。有了这个间接层之后,大部分调用代码几乎不用变化,这比辛辛苦苦找到所有 xxx 的引用点再改成 xxx_ref 显然要容易多了(也不容易出错)。NodeRef.get_node() 则是为了避免重复的空检查而提取的一个简单的辅助方法,读者请直接参考版本库中的代码即可。
基础结构已经就位,我们还要看看哪些部分的代码需要修改。如果读者和我一样懒,不想重新过一遍代码的话,最省事的办法是直接运行测试,出错信息会告诉我们哪里需要修改(这也是测试作为重构安全网的意义所在)。我们会发现 transform() 方法有问题了,它原来像这样:
def transform(self, **kwargs):
return Node(self.key,
value=kwargs.get('value', self.value),
left=kwargs.get('left', self.left),
right=kwargs.get('right', self.right))
现在构造节点不能直接指定 value/left/right 了。因为引用的判断逻辑基本上是相同的,可以再写一个简单的辅助方法,让引用自己来执行变换:
class Ref:
@classmethod
def transform(cls, current, data, key):
return cls(target=data[key]) if key in data else current
class Node:
def transform(self, **kwargs):
return Node(self.key,
value_ref=ValueRef.transform(self.value_ref, kwargs, 'value'),
left_ref=NodeRef.transform(self.left_ref, kwargs, 'left'),
right_ref=NodeRef.transform(self.right_ref, kwargs, 'right'))
看起来 Ref.transform 似乎作为成员方法更加合适,但 NodeRef 是有可能为 None 的,为了简化空指针检查,我还是决定把它作为类方法。
再运行测试,会发现还有一处问题:insert() 方法需要新建节点,这里也要修改。我希望作为算法的函数尽可能不要牵涉到节点内部结构的太多细节,因此把创建节点也封装成一个类方法:
class Node:
@classmethod
def create(cls, key, value):
return cls(key=key,
value_ref=ValueRef(target=value))
def insert(node: Node, key, value) -> Node:
if not node:
return Node.create(key, value)
...
现在测试可以全部通过了。
在这个环节,我们对节点内部结构作出了比较大的调整。然而在经过适当封装之后,除了 transform() 和 insert() 这两处,其他大部分调用代码可以原封不动,测试部分也完全没有变化。可以说是相当优雅了。
把二叉树节点改为通过指针访问,也就为数据的读取和储存做好了准备。在下个步骤我们会实现数据的访问机制。
步骤2:存储
对于存储系统的要求,在文章开头分析过,大致有这个几个方面:
- 它应该视为一个普通的字节流。在
Python中对这种结构有一个很好的抽象:File-like object(以下简称FLO); - 节点内容以数据块形式存储。具体存储格式需要我们自己确定,要简单的话,不妨使用语言内置的
pickle机制(这也是本文采用的方法)。如果要方便调试,也可以考虑使用对人眼更加友好的格式,比如JSON; - 它需要维护两个指针:指向根节点地址,以及指向可用存储位置的指针
显然,数据库的内容最终是要写入磁盘的,似乎可以直接使用文件。但文件的持久性对于测试来说反而是个麻烦,因此为了照顾测试的需要,我决定同时支持基于内存或文件的存储。好在它们都可以视为 FLO,所以几乎不会增加什么工作量。
我们创建一个 storage 模块,并定义接口和工厂方法:
class Storage:
def __init__(self, f, is_new):
pass # TODO: to impl...
def memory() -> Storage:
return Storage(BytesIO(), is_new=True)
def file(file_name: str) -> Storage:
if os.path.exists(file_name):
mode, is_new = 'rb+', False
else:
mode, is_new = 'wb+', True
f = open(file_name, mode)
return Storage(f, is_new=is_new)
在新建文件的情况下,我们需要进行初始化指针等一些必要的维护工作,所以传给构造方法一个 is_new 参数。这之后对于不论基于内存或文件,对于 FLO 的读写都是相同的,无需再做区分。
现在进入二进制的领域。为保证一致性,我们约定使用 8 个字节来储存地址,并且用内置方法 struct.pack/unpack 来进行整数地址与字节之间的转换:
class Storage:
def __init__(self, f, is_new: bool):
self._f = f
if is_new:
self.set_root_addr(ADDR_NONE)
self.set_free_addr(ADDR_FREE_START)
else:
self.root_addr = self.read_int(OFFSET_ROOT)
self.free_addr = self.read_int(OFFSET_FREE)
def set_root_addr(self, addr: int):
self.root_addr = addr
self.write_int(OFFSET_ROOT, addr)
def write_int(self, offset: int, value: int):
self.seek(offset)
self._f.write(struct.pack(INT_FORMAT, value))
由于都是比较简单的读写操作,这里就不列出完整代码了,相信是很容易看懂的。
除了读写地址之外,存储部分还要实现读写节点数据的功能。从概念上讲,存储层最好是只关心数据与字节,不要太了解节点的内部构造,否则就耦合得过于紧密了。因此这部分我们分开来实现,存储层可以基于 pickle 机制读写数据,但不用关心这些数据从哪里来、内部是什么样的。当然,写入数据之后要记得更新地址:
def write_data(self, data) -> int:
data_addr = self.free_addr
self.seek(data_addr)
pickle.dump(data, self._f)
self.set_free_addr(self._f.tell())
return data_addr
def read_data(self, addr: int):
self.seek(addr)
return pickle.load(self._f)
本来,到这里应该顺便把从 Node 到数据的序列化/反序列化操作一起也实现了,但在动手的时候才意识到,要完成这个工作还涉及到内部结构的一些改变,所以这个任务暂且留到下个阶段吧。
按照存储结构去看的话,目前的实现还存在一个问题:我们在二叉树(BinaryTree)中存放的是根节点,但按照存储结构,根节点也需要记录一个地址,而我们并没有地方来存放它。因此这里需要做一个调整:把存储节点改为对节点的引用。与第二步类似,为了避免调用端代码做太多调整,我们也把对节点的访问封装为属性:
class BinaryTree:
def __init__(self, storage):
self._storage = storage
self._root_ref = None
@property
def root_node(self):
return NodeRef.get_node(self._root_ref)
@root_node.setter
def root_node(self, value):
if value == self.root_node:
return
self._root_ref = NodeRef(target=value) if value else None
在完成以上重构之后,可以增加一些测试,来检查存储接口,包括读写地址、数据以及初始化是否都能正常工作。这些都是很简单的判断了,但通过测试我还是发现一个潜在的小问题:对内存的读写是立即生效的,而对文件的访问要记得调用 flush() 或 close(),否则变更有可能并未提交到磁盘,一旦关闭程序就会丢失。当然这也应该是常识了,不过如果只专注于实现功能的话,还是很有可能被忽略掉的。所以我们应当感谢测试:虽然它有时候会被视为额外的工作,但它也经常会提醒我们一些自己可能都忘记了的事情。
步骤3:序列化
在上一步实现了存储读写机制,也遗留了一个问题:要实现节点的序列化/反序列化,需要涉及结构上的变更。为了说明该问题,我们回头看看节点为实现延迟加载而进行的抽象:
@property
def value(self):
return self.value_ref.get()
很明显,数据延迟加载的逻辑放在这里是最合适的。但这就引出一个问题:要加载数据就必须找到存储(Storage)对象,那么这个对象从哪来?由谁去管理它?这就是一个比较重大的设计决策了。
如果读者去看原作者的实现,会看到:存储对象是由接口层(DBDB)创建的,并传递到二叉树(BinaryTree)的构造方法,但实际访问则大多数上推到其基类(LogicalBase),而各个内部对象(BinaryNode/NodeRef/ValueRef)基本上也都能获得并直接调用 Storage 的接口。老实说,这么复杂的调用关系一度让我读代码读得头昏脑胀。所以在自己编写这部分代码的时候,我决定抛开作者的思路,按照自己的想法来实现。
需要访问存储的是节点(Node),但是让各个节点各自去获取 Storage 显然不太合理,并且 Node 自身的逻辑已经相当复杂了。而作为节点的容器,由二叉树去维护 Storage 更为恰当,且BinaryTree 目前相当简单,容易扩充。不过,这样设计仍然存在一个问题:节点要获取 Storage,就意味着它要对 BinaryTree 有所了解,而 BinaryTree 自身又负责管理 Node,这就形成了双向依赖关系。虽然不算严重,总归是一种“坏味道”。依照经验,双向循环一般可以通过提取接口来打破。Python 在语法层面并没有接口这种东西,不过我们可以用抽象类来模拟:
class NodeManager(ABC):
@abstractmethod
def on_load_value(self, ref: ValueRef):
pass
@abstractmethod
def on_load_node(self, ref: NodeRef):
pass
这是一个相当简单的接口。我们希望引用类(ValueRef/NodeRef)用它们来表示需要访问存储的时间点,而具体的访问逻辑则交给 BinaryTree 去实现。这样,节点类的构造方法需要再添加一个参数:
class Node:
"""Node of binary tree"""
def __init__(self, manager: NodeManager, key, value_ref: ValueRef,
left_ref: NodeRef = None,
right_ref: NodeRef = None):
assert isinstance(manager, NodeManager)
...
self.manager = manager
在访问值或子节点时就可以回调此接口。因为 NodeRef 可能为空,所以我们再写一个辅助方法来简化判断逻辑:
def get_child_node(self, ref: NodeRef):
if ref:
self.manager.on_load_node(ref)
return ref.get()
return None
@property
def value(self):
self.manager.on_load_value(self.value_ref)
return self.value_ref.get()
@property
def left(self):
return self.get_child_node(self.left_ref)
@property
def right(self):
return self.get_child_node(self.right_ref)
接下来,让 BinaryTree 实现 NodeManager:
class BinaryTree(NodeManager):
def on_load_value(self, ref: ValueRef):
if ref.has_value():
return
assert ref.has_addr()
ref.target = self._storage.read_data(ref.addr)
def on_load_node(self, ref: NodeRef):
if ref.has_value():
return
assert ref.has_addr()
data = self._storage.read_data(ref.addr)
node = Node.deserialize(self, data)
ref.target = node
它们的逻辑是类似的:如果值已经加载,则不用做任何事情;否则,按照记录的地址读取并加载数据。细心的读者会意识到这里的代码有一点重复。有代码洁癖的同学或许会马上着手提炼代码,但我本着“事不过三,三则重构”的原则,实现功能即可,如果重复达到三次以上再去考虑处理它。
现在我们可以去实现节点的序列化及反序列化:
class Node:
def serialize(self):
data = {
'key': self.key,
}
self.serialize_ref(data, 'value_addr', self.value_ref)
self.serialize_ref(data, 'left_addr', self.left_ref)
self.serialize_ref(data, 'right_addr', self.right_ref)
return data
def serialize_ref(self, data, key, ref: Ref):
if ref:
assert ref.has_addr()
data[key] = ref.addr
@classmethod
def deserialize(cls, manager, data):
key = data['key']
value_ref = ValueRef(data['value_addr'])
left_ref = NodeRef.from_addr(data.get('left_addr', ADDR_NONE))
right_ref = NodeRef.from_addr(data.get('right_addr', ADDR_NONE))
return Node(manager=manager,
key=key,
value_ref=value_ref,
left_ref=left_ref,
right_ref=right_ref)
我们把节点内容序列化为 dict。本着节约空间和减少 IO 的原则,如果左/右子节点为空,则不会记录到字典,相应的处理逻辑要做好对于是否值存在的判断。这里还有一些辅助方法如 has_addr()/from_addr(),其含义是显而易见的,为节约篇幅不再列出,读者可以自行参考代码。
加载有了,现在实现数据的保存。这里需要注意的是保存顺序:应该自底向上,先保存值以及左/右子节点之后,引用中的地址才有效,否则序列化的数据是无意义的。当然,已经保存过(地址有效)的节点应该跳过:
def commit(self):
self.commit_node_ref(self._root_ref)
self._storage.set_root_addr(self.root_addr)
self._storage.flush()
def commit_node_ref(self, ref: NodeRef):
if not ref or ref.has_addr():
return
assert ref.has_value()
node = ref.get()
self.commit_value_ref(node.value_ref)
self.commit_node_ref(node.left_ref)
self.commit_node_ref(node.right_ref)
ref.addr = self._storage.write_data(node.serialize())
def commit_value_ref(self, ref: ValueRef):
assert ref and ref.has_value()
if ref.has_addr():
return
ref.addr = self._storage.write_data(ref.get())
现在读写逻辑都已就绪,但参数有所增加,调用者的代码也要跟着调整才行。这里测试又可以发挥防护网的作用了:不必去一处处查找修改点,只要运行测试,错误信息会告诉我哪些地方需要修改。由于 BinaryTree 的构造方法需要传入 Storage 作为参数,所以测试也要跟着修改,好在这个工作很简单。
为保证完整性,该步骤也增加了一些测试来确认存储接口读写的正确性,这里不再赘述。
步骤4:数据库接口
到此,我们的数据库内部实现已经比较完善,BinaryTree 提供的接口也已经很接近于可以直接调用的成都,但让用户自己去创建一个 BinaryTree 显然是说不过去的。因此,我们可以在此基础上再提供一层简单的封装,作为数据库的对外接口。在这个层面上,我们也会考虑有关并发与性能相关的一些问题。
首先实现接口封装。因为这是一个 K-V 数据库,不妨按照语言协议给它提供类似于 dict 的接口,从而调用起来更加简洁:
class DB:
def __init__(self, file_name: str):
self._storage = storage.file(file_name)
self._tree = BinaryTree(self._storage)
def close(self):
self._storage.close()
def __getitem__(self, key):
return self._tree.get(key)
def __setitem__(self, key, value):
self._tree.set(key, value)
def __delitem__(self, key):
self._tree.delete(key)
def commit(self):
self._tree.commit()
这个工作简直是轻而易举。接下来考虑一下,如果有多个程序同时访问此数据库的话,会出现什么情况?
本程序(以及原文的程序)是基于不可变对象的理念实现的,因此多个程序同时访问并不会导致并发冲突甚至程序崩溃,因为数据是不可变的,我们完全不必担心某项内容突然被其他程序偷偷改掉的可能。
但这并不意味着并发相关的所有问题都自动消失了。一种(可能性很大)的问题是,某个进程进行了修改,但其他进程并未“看到”本次修改,于是它们仍然在原来的数据上执行操作,这样当它们写入磁盘的时候,上一个进程的修改就丢掉了。
解决此问题办法类似于版本控制:我们在提交变更之前先“同步”一下,如果发现有最新的提交,则需要首先合并,再做修改。具体到数据库,则是先检查一下根节点的地址是否有变化(因为任何变化都会导致根节点的变更),如果磁盘上的值和原先的值并不一致,就意味着有其他程序修改了内容。在此情况下,我们可以重新读取根节点,再继续下面的操作,这样就保证了数据总是最新的。该方法未必是最高效的,但却是最容易理解和实现的。
另一个需要考虑的问题是:虽然内存访问不担心访问冲突,但磁盘访问却有可能出问题。回想一下,从磁盘加载至少需要两次操作:
- 读取头部信息(包括根节点和可用空间地址);
- 读取根节点;
在经过多次读写之后,根节点数据距离文件头部可能已经很远,因此无法保证这是一个原子操作(从原理上讲,对同一个磁盘扇区的访问可以认为是原子操作),如果这期间夹杂着其他进程的读写操作的话————在并发情况下这是极有可能的————就会出现问题。对于 commit() 操作,如果需要写入多个节点的话,遇到冲突的危险会更大。因此,对磁盘的读写操作最好还是用锁来进行保护。
本文(以及原文)都使用了一个名为 portalocker 的第三方库来实现文件级别锁(各个操作系统对于文件锁的实现差别很大,不建议自己去实现)。为了实现加锁/解锁,我们首先为 Storage 增加两个方法。以及一个成员变量来记录当前是否有锁:
class Storage:
def __init__(self, f, is_new: bool):
...
self.locked = False
def lock(self):
if not self.locked:
portalocker.lock(self._f, portalocker.LOCK_EX)
self.locked = True
def unlock(self):
if self.locked:
portalocker.unlock(self._f)
self.locked = False
Storage 只提供接口,至于加锁的时机则交给上层,也就是 DB 来控制:
def reload_root(self):
self._storage.lock()
try:
self._tree.reload_root()
finally:
self._storage.unlock()
这样,我们就可以保证读取操作是原子性的,当然这也付出了性能上的代价。之后在每个读写方法之前调用 reload_root() 即可。
我们的代码还存在一个潜在的性能问题。还记得前面说过吗?为了保证数据写入磁盘,我们要记得在数据修改之后调用 flush()。这样保证了数据完整性,但对于批量写入而言,效率确实相当低下的。想象一下,如果我们同时修改 N 个节点,那么根节点也必须变换 N 次,但其实只有最后一次写入磁盘才有意义,前面的提交其实是浪费,同时也会造成更多的磁盘碎片。
现代数据库对此的解决方案是事务。事务中发生的变化都是一起提交的,这样不仅能够提高性能,也可以保证操作的原子性。当然,如果没有日志等辅助手段,我们并不能完全保证原子性,但对于提高效率总是有帮助的。
为了不要给使用者增加太多负担,如果不使用事务的话,我们也不应该让用户自己去记得何时提交,而是可以使用“隐式事务”,让每个修改自动提交。当用户明确指定事务时,则在调用事务的 commit() 时执行提交。用代码来说明可能更为清楚一些:
def test_set_no_transaction(self):
self.db['k1'] = 'v1'
self.db['k2'] = 'v2'
self.assertEqual(2, self.db.commit_times)
def test_set_transaction(self):
with self.db.begin_transaction() as transaction:
self.db['k1'] = 'v1'
self.db['k2'] = 'v2'
transaction.commit()
self.assertEqual(1, self.db.commit_times)
事务的实现并不困难。我们可以提供一个方法 begin_transaction() 让用户自己去启动事务;如果用户不指定的话,则隐含地启动一个自动事务,该事务在调用完毕时即提交。
def begin_transaction(self):
self.transaction = ManualTransaction(self)
return self.transaction
def get_current_transaction(self):
return self.transaction or auto_transaction(self)
def __setitem__(self, key, value):
with self.get_current_transaction():
self._tree.set(key, value)
自动事务的实现用到了一点技巧。尽管它应该是一个实现 __enter__/__exit__ 协议的对象,但通过 contextlib 的封装,我们可以把它写成像一个普通函数:
@contextlib.contextmanager
def auto_transaction(db):
db.reload_root()
yield
db.commit()
另一方面,手动事务在用户调用 commit 时触发,所以无法沿用此模式,只能退回到普通的实现:
class ManualTransaction:
def __init__(self, db):
self.db = db
self.db.reload_root()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
pass
def commit(self):
self.db.commit()
self.db.end_transaction()
在前面的测试中可以看到,数据库接口有一个成员变量 commit_times,可以让我们确认没有多余的提交。
步骤5:命令行接口
我们还差最后一步了。上面实现的 DB是一个程序员调用的接口(API),但仍然不是给最终用户使用的。为了让普通用户也能使用本程序,同时也让自己能够手动运行程序或执行测试,完善的应用应该考虑提供一个命令行接口(CLI)。
本步骤也可以视为一个独立的步骤,但复杂的模块名会给用户的使用造成一定麻烦(多打字)。为方便起见,我还是把它作为项目根目录下的模块,命名为 cli.py。
先设计命令格式,顺便可以把帮助信息也一起实现了:
def usage():
print('Usage:')
print('\t./cli.py <DBNAME> get <KEY> - get value')
print('\t./cli.py <DBNAME> set <KEY> <VALUE> - set key value')
print('\t./cli.py <DBNAME> del <KEY> - delete key')
print('\t./cli.py <DBNAME> purge - delete database')
和原文相比,我们增加了一个 purge 子命令,这样如果出现混乱,或者只是想从头开始,用户不必回到外壳下去自己删除多余的文件。
主程序的实现就是命令映射,其实没有什么要说的:
def _get(db: DB, key):
print('{} => {}'.format(key, db[key]))
...
def main(argv):
try:
if not (2 <= len(argv) <= 4):
raise SyntaxError()
db_name, op = argv[0], argv[1]
db = DB(db_name)
ops = {
'get': _get,
'set': _set,
'del': _del,
'purge': _purge,
}
if op not in ops:
raise SyntaxError()
ops[op](db, *argv[2:])
return 0
except (SyntaxError, TypeError):
usage()
return -1
如果参数有误、又或者参数数量不对,会分别抛出 SyntaxError 或 TypeError,对此处理也很简单:调用 usage() 告诉用户正确的用法。
总结
在本文中,我们以自己的方式实现了 K-V 数据库 DBDB。虽然和原文相比,其基础原理是相同的,但在设计思路和最终实现上则存在较大的差别。如果读者有耐心(也有时间)的话,不妨把两种实现对照起来看。
和该系列的其他文章一样,原作者在最后也提出了一些让读者自己去思考的问题,比如说如何实现磁盘空间的回收。要实现这一点并不难————把节点数据拷贝到一个新的二叉树再保存就行了。然而如果存在大量数据的话,这个操作耗时会很长,不仅带来了沉重的 IO 压力,而且会影响在线事务的性能。要实现完善的空间回收、同时尽量避免影响性能还是要考虑很多方面的因素(是的,即便在 Postgresql 这样成熟的数据库中,何时以及如何进行 vacuum 也是一个复杂的问题)。
用不可变思想来实现数据库是作者提出的一个有趣的思路,但参考现实世界的数据库管理系统,不论传统的关系型数据库还是较新的 NoSql,按照这个思路来实现的系统并不多(当然也可能是我孤陋寡闻了)。这可能是因为大多数数据库产品基本形态已经定型多年,很难在核心思路上再做出重大调整;另一方面也要承认,这样实现的数据库确实节点变更的频率更高,对于空间回收的压力也更大。不管怎么说,作者提出了一个有趣的方向。而且在自己实现一遍之后,我也能够认同,和可变数据结构相比,不变数据结构更不容易出错,即便出错,排查起来也往往更容易一些(因为可能出错的点只有一处)。可能对于从命令范式上手的程序员来说,思维范式的转换才是更大的障碍吧。
文章索引
- 重写 500 Lines or Less 项目 - 前言
- 重写 500 Lines or Less 项目 - Web Server
- 重写 500 Lines or Less 项目 - Template Engine
- 重写 500 Lines or Less 项目 - Continuous Integration
- 重写 500 Lines or Less 项目 - Static Analysis
- 重写 500 Lines or Less 项目 - A Simple Object Model
- 重写 500 Lines or Less 项目 - A Python Interpreter Written in Python
- 重写 500 Lines or Less 项目 - Contingent
- 重写 500 Lines or Less 项目 - DBDB
- 重写 500 Lines or Less 项目 - FlowShop
- 重写 500 Lines or Less 项目 - Dagoba
- 重写 500 Lines or Less 项目 - 3D 建模器