重写 500 Lines or Less 项目 - A Simple Object Model
概述
本文章是 重写 500 Lines or Less 系列项目其中一篇,目标是重写 500 Lines or Less 系列的原有项目:A Simple Object Model。在阅读原文时,我发现一个问题:作者设计的代码其实是非常合理的,问题在于他直接给出了几乎是最终版的类层次结构,首次阅读的用户来说很可能会对为什么要这样设计感到疑惑。我也是在自己从头完整地实现一遍之后,才算是比较清楚地理解到作者的设计意图。因此,本次重写主要在以下几个方面做出改变:
如何检测程序运行在虚拟机中?

最近在网络上看到有人提出一个有趣的问题:程序能否知道自己是在虚拟机中运行的?如果能,是怎么做到的?
之前并没有深入考虑过这个问题,不过我知道这确实是可能的。比如说,国内比较有知名度的深度操作系统在安装时就会检查自己所在的运行环境,如果发现是从虚拟机运行的,就会主动关闭一些比较消耗资源的动画与特效。
内容丰富的命题作文 - 《Visual Studio Code 权威指南》书评

Visual Studio Code 是微软推出的、主要面向程序员的新一代编辑器,在某些轻量级场景下已经可以替代专业的 IDE 产品(尽管从本质上说它仍然是编辑器)。其实它出现也已经有好几年了,但一直以来除了官方文档之外,缺乏其他系统性的学习资料。当然也不是完全没有,比如:
- Syncfusion: Visual Studio Code 2016 Succinctly
- Apress: Visual Studio Code Distilled
- Wiley: Visual Studio Code
现在,由微软中国的工程师韩骏编写的《Visual Studio Code 权威指南》出版了,也算是填补了该主题在中文领域的一项空白。
重写 500 Lines or Less 项目 - Static Analysis
概述
本文章是 重写 500 Lines or Less 系列项目其中一篇,目标是重写 500 Lines or Less 系列的原有项目:静态分析/Static Analysis。原文章代码是基于 Julia 这种新型的编程语言,主要分析目标是该语言中比较被强调的一个特性:多重分派(multiple dispatch)。考虑到 Julia 语言并不是特别普及,同时多重分派在其他语言中也并非常见特性(也有与之相近的概念),可能大部分读者对它会比较陌生,影响对于原文的理解。因此,本文选择基于主流、同时也比较便于学习和理解的 Python 来演示静态分析的原理和过程,不再按照原文的体例。
微软发布了 Pylance,但并不开源
最近,微软发布了 PyLance。这是一个新的、用于语言服务协议(LSP)的 Python 语言支持,目的是希望在未来逐渐取代已经在 Visul Studio Code 中使用了数年的 Python 扩展的当前版本。以下是微软官宣的信息:
Announcing Pylance: Fast, feature-rich language support for Python in Visual Studio Code
重写 500 Lines or Less 项目 - Continuous Integration
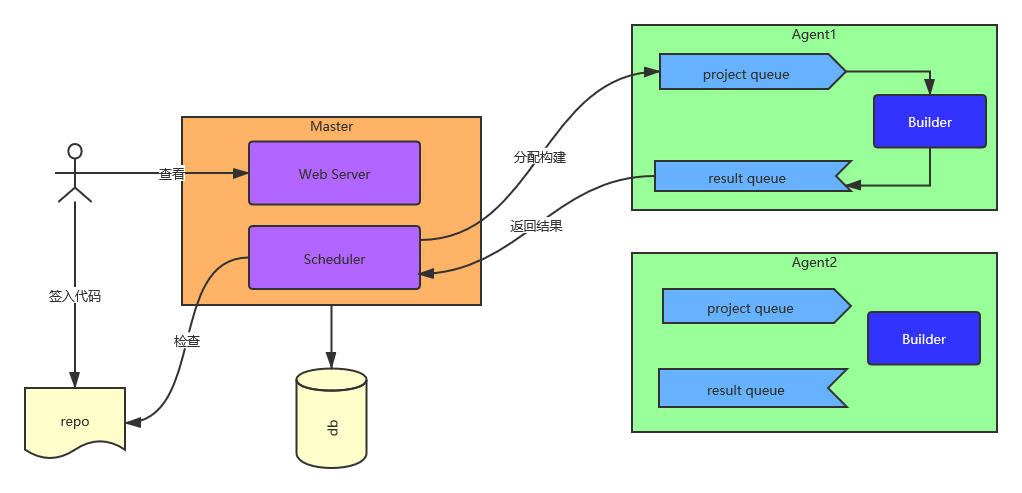
概述
本文章是 重写 500 Lines or Less 系列的其中一篇,目标是重写 500 Lines or Less 系列的原有项目:持续集成系统(A Continuous Integration System)。本文部分借鉴了原程序的实现思路,但文章和代码都是从头编写的。相对于原文而言,本次重写在以下方面做出了比较重大的修改:
重写 500 Lines or Less 项目 - Template Engine
概述
本文章是 重写 500 Lines or Less 系列的其中一篇,目标是重写 500 Lines or Less 系列的原有项目:模板引擎(A Template Engine)。本文借鉴了原程序的实现思路,但文章和代码都是从头编写的。相对于原文而言,本次重写在以下方面做出了比较重大的修改:
重写 500 Lines or Less 项目 - Web Server
本文章是 重写 500 Lines or Less 系列项目其中一篇,目标是重写 500 Lines or Less 系列的原有项目:A Simple Web Server。原文章代码是用 Python2 开发的,目前在 Python3 上无法正常运行。同时,部分内容比如 CGI 也已经不太适合目前的时代。因此本次重写主要关注以下方面:
重写 500 Lines or Less 项目 - 前言
对于有一定编程基础、希望提高项目能力的同学来说,500 Lines or Less 无疑是个很好的参考。它的若干实例都是来自实际、具有现实意义的项目,500 行左右的代码规模对初学者来说略有难度但也不至于高不可攀,作为提高级别的学习资料是相当合适的,因此也有不少人推荐过它。
不过在浏览这个项目之后,我也发现一些问题。最大的问题可能是这些文章写成时间较早,代码也有些过时,比如很多示例是用 Python2 写成的,它们如果不经修改的话,在目前的 Python3 上是无法运行的;此外,部分内容也应当更新。比如 Web 服务器的例子讲述到了 CGI,但 CGI 在现代的 Web 服务器上已经很少使用,不太值得再去花时间深究。
另外一个遗憾是作为教材的写作方法。尽管这些代码并不算多——从题目就能知道,都在 500 行以内——但除非你对目标领域非常熟悉,否则是不太可能一次写成的。然而,大部分示例是先讲解原理之后就展示最终的代码。我们既看不到作者思考的过程,也不太日常项目开发的实际情况。因此,我决定不再跟随原文章的节奏,而是自己从头写起,并采用分步骤、渐进式的方法,保持文章和代码同步。这样,你能够看到一个较大的需求是如何从简单的方式入手,一步步扩展成完整的程序的。相信每个人在开发时会有自己的思考方式和具体步骤,如果自己去完成该项目的话,各人的实现会有很大差异,这是完全正常的。所以我也希望大家通过自己的思考去理解代码,当然,有条件的话最好是再自己动手写一遍,这样才能让自己的理解更加深入。
当然,重写这么多篇文章是个宏大的工程,我的力量毕竟有限,不可能面面俱到。原文中大多在开篇时会花一些篇幅来讲解项目设计的基础知识,比如涉及到的网络协议的工作原理等等,这些内容并不过时,基本上也没有更新的必要,因此直接阅读原文即可。本系列的文章一般会先简述背景和内容结构,然后直接进入开发环节。
以上说到了一些问题,但这并不是对原项目的批评。相反,这些作者前辈是非常值得尊敬的,他们乐于向后辈分享知识,并耐心编写了这些颇具深度的学习资料。我所编写的大部分代码也是在他们的基础上进行扩展或改写,换句话说,我也是站在巨人的肩膀上,希望给后来人的学习提供一点微小的贡献。当然,自私地说,对我本人也是一个学习和实践的机会。
示例代码
本文章系列的所有代码都放在 我的 Github 代码库,每个项目使用一个单独的目录,命名和 500 Lines or Less 项目保持一致,以方便查找。但为了方便使用,避免为各个项目及步骤单独创建环境的麻烦,代码根目录下包含了总的入口,比如 Python 代码的入口是 main.py。部分示例代码如下:
"""
Web Server example.
"""
# Run Step 00: Basic Server
# from web_server.step00_basic_server import main; main()
# Run Step 01: Middlewares
# from web_server.step01_middlewares import main; main()
读者想要运行哪个项目/步骤的代码,只要去掉注释符号即可。大家也会发现,为了让目录成为合法的模块,部分目录名称做了相应的修改,相信对查找代码不会造成障碍。
以下列出分类文章/项目目录以及相关的参考资料,大家可以选择自己感兴趣的主题来阅读。
文章索引
- 重写 500 Lines or Less 项目 - 前言
- 重写 500 Lines or Less 项目 - Web Server
- 重写 500 Lines or Less 项目 - Template Engine
- 重写 500 Lines or Less 项目 - Continuous Integration
- 重写 500 Lines or Less 项目 - Static Analysis
- 重写 500 Lines or Less 项目 - A Simple Object Model
- 重写 500 Lines or Less 项目 - A Python Interpreter Written in Python
- 重写 500 Lines or Less 项目 - Contingent
- 重写 500 Lines or Less 项目 - DBDB
- 重写 500 Lines or Less 项目 - FlowShop
- 重写 500 Lines or Less 项目 - Dagoba
- 重写 500 Lines or Less 项目 - 3D 建模器